IP Adapter
1.0.0
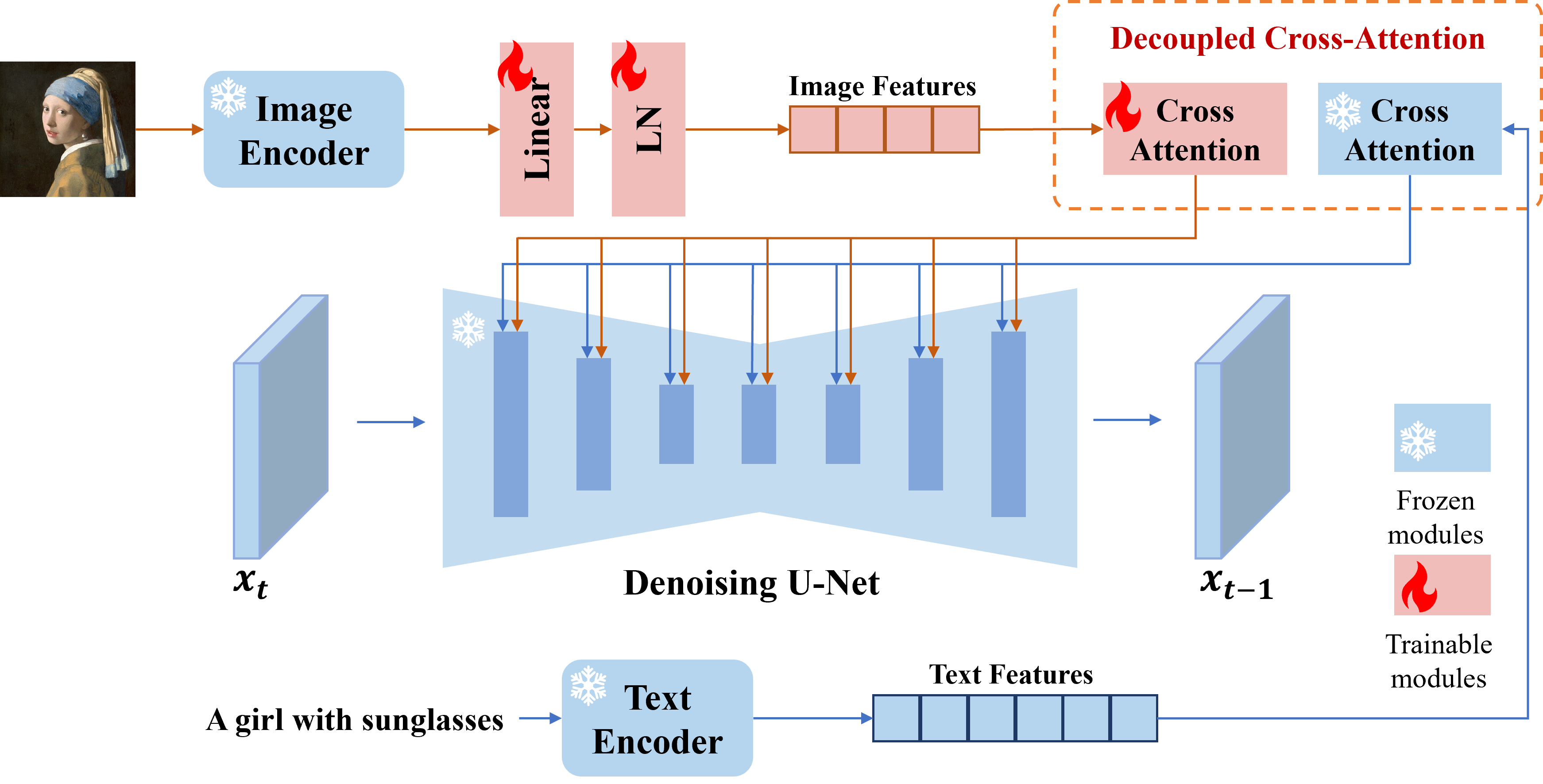
Presentamos el adaptador IP, un adaptador efectivo y liviano para lograr la capacidad de solicitud de imagen para los modelos de difusión de texto a imagen previamente entrenados. Un adaptador IP con solo 22 m de parámetros puede lograr un rendimiento comparable o incluso mejor para un modelo de indicación de imagen sintonizado. El adaptador IP se puede generalizar no solo a otros modelos personalizados ajustados del mismo modelo base, sino también a la generación controlable utilizando herramientas controlables existentes. Además, el mensaje de imagen también puede funcionar bien con la solicitud de texto para lograr la generación de imágenes multimodales.
# install latest diffusers
pip install diffusers==0.22.1
# install ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# download the models
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# then you can use the notebook
Puedes descargar modelos desde aquí. Para ejecutar la demostración, también debe descargar los siguientes modelos:









Mejor práctica
scale=1.0 y text_prompt="" (o algunas indicaciones de texto genéricas, por ejemplo, "mejor calidad", también puede usar cualquier indicador de texto negativo). Si baja la scale , se pueden generar imágenes más diversas, pero pueden no ser tan consistentes con el mensaje de imagen.scale para obtener los mejores resultados. En la mayoría de los casos, scale=0.5 puede obtener buenos resultados. Para la versión de SD 1.5, recomendamos usar modelos comunitarios para generar buenas imágenes.Adaptor IP para imágenes no cuadradas
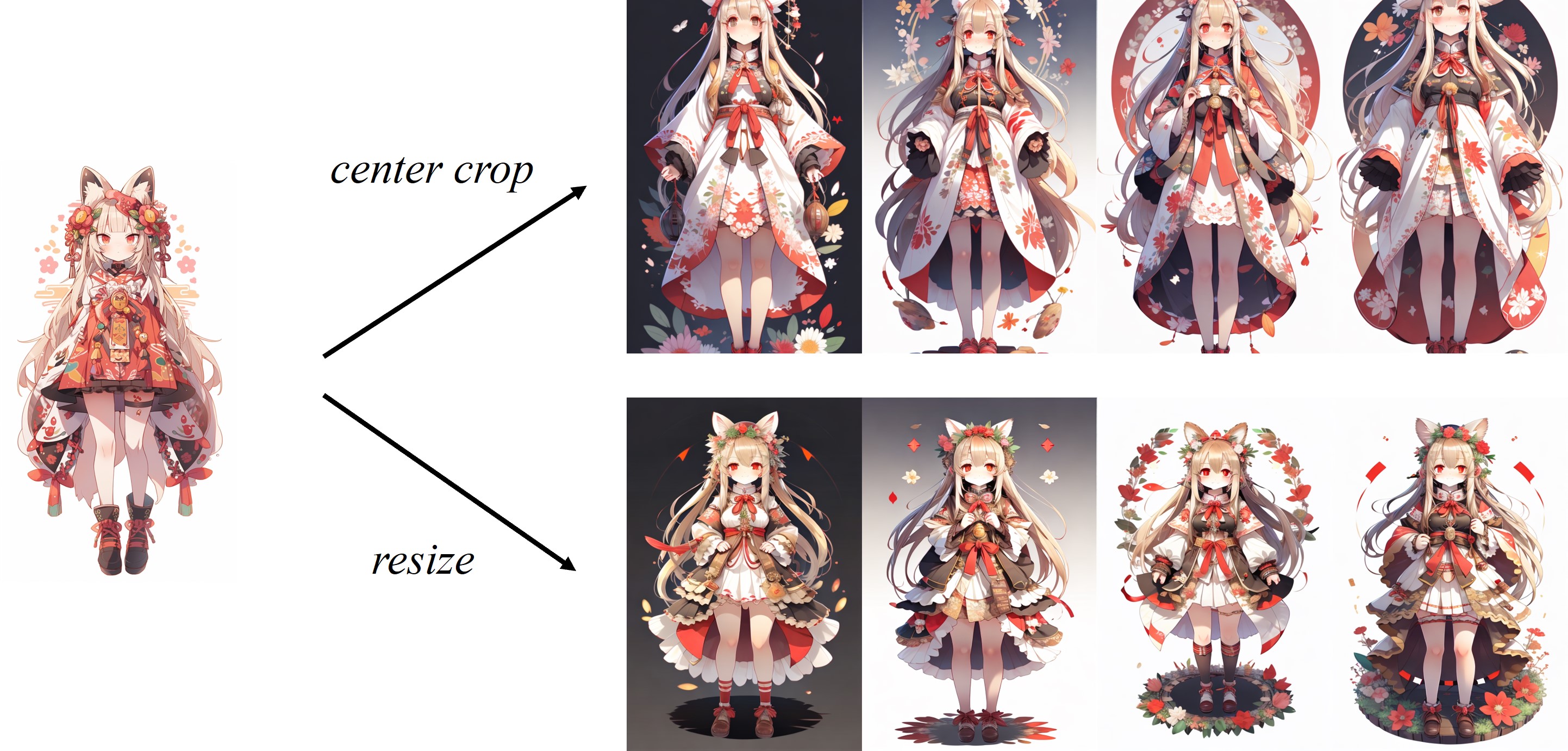
Como la imagen se recorta central en el procesador de imagen predeterminado del clip, el adaptador IP funciona mejor para imágenes cuadradas. Para las imágenes no cuadradas, se perderá la información fuera del centro. Pero puede cambiar el tamaño a 224x224 para imágenes no cuadradas, la comparación es la siguiente:
La comparación de IP-Adapter_XL con Reimagine XL se muestra de la siguiente manera:

Mejoras en la nueva versión (2023.9.8) :
Para la capacitación, debe instalar acelerar y convertir su propio conjunto de datos en un archivo JSON.
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16"
tutorial_train.py
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/"
--image_encoder_path="{image_encoder_path}"
--data_json_file="{data.json}"
--data_root_path="{image_path}"
--mixed_precision="fp16"
--resolution=512
--train_batch_size=8
--dataloader_num_workers=4
--learning_rate=1e-04
--weight_decay=0.01
--output_dir="{output_dir}"
--save_steps=10000
Una vez que se completa el entrenamiento, puede convertir los pesos con el siguiente código:
import torch
ckpt = "checkpoint-50000/pytorch_model.bin"
sd = torch . load ( ckpt , map_location = "cpu" )
image_proj_sd = {}
ip_sd = {}
for k in sd :
if k . startswith ( "unet" ):
pass
elif k . startswith ( "image_proj_model" ):
image_proj_sd [ k . replace ( "image_proj_model." , "" )] = sd [ k ]
elif k . startswith ( "adapter_modules" ):
ip_sd [ k . replace ( "adapter_modules." , "" )] = sd [ k ]
torch . save ({ "image_proj" : image_proj_sd , "ip_adapter" : ip_sd }, "ip_adapter.bin" )Este proyecto se esfuerza por impactar positivamente el dominio de la generación de imágenes impulsada por la IA. A los usuarios se les otorga la libertad de crear imágenes utilizando esta herramienta, pero se espera que cumplan con las leyes locales y las utilizan de manera responsable. Los desarrolladores no asumen ninguna responsabilidad por el mal uso potencial por parte de los usuarios.
Si encuentra útil el adaptador IP para su investigación y aplicaciones, cite con este bibtex:
@article { ye2023ip-adapter ,
title = { IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models } ,
author = { Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei } ,
booktitle = { arXiv preprint arxiv:2308.06721 } ,
year = { 2023 }
}

