scratchplot story generation
1.0.0
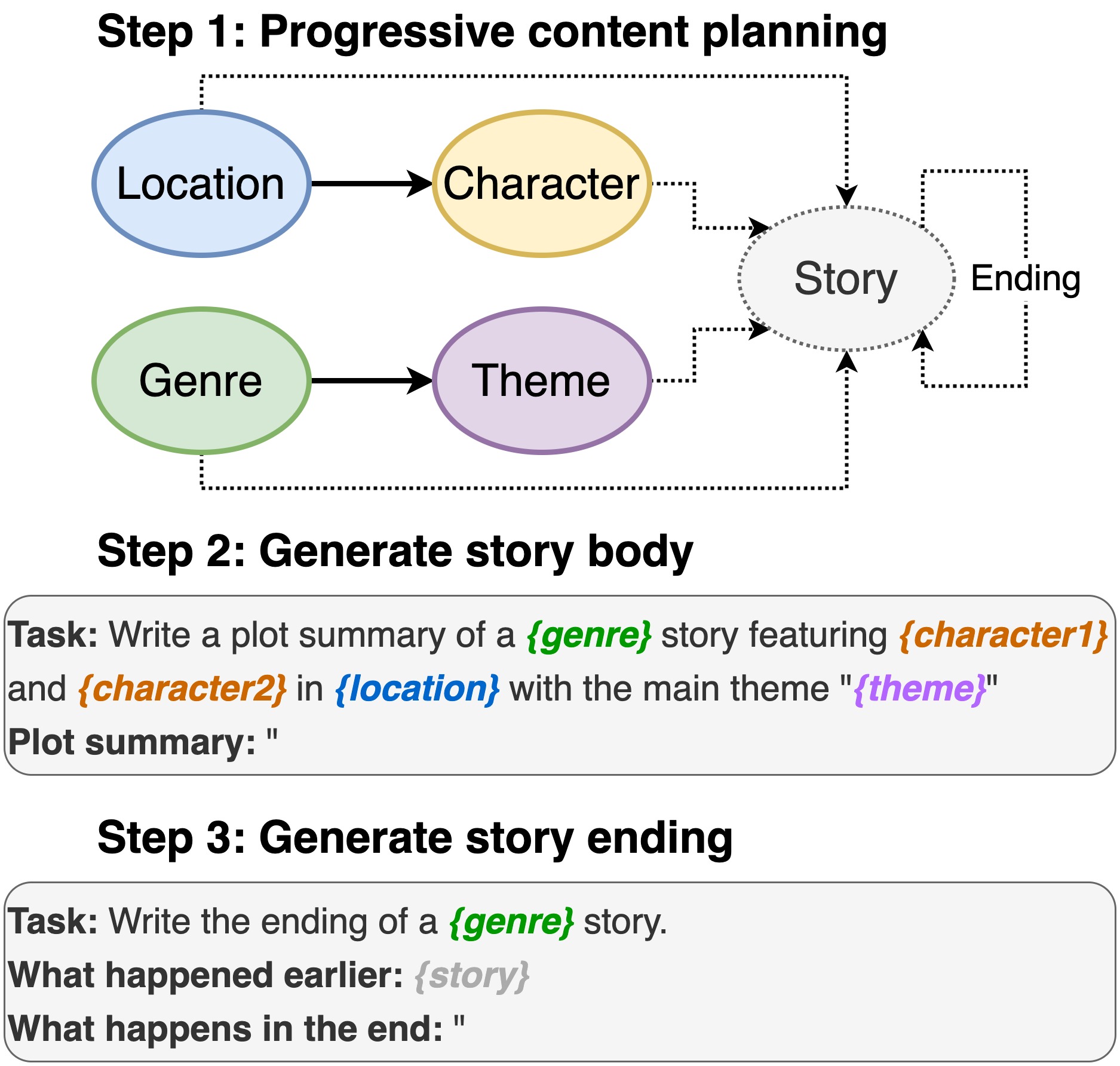
Este repositorio contiene el código para la escritura de la trama de los modelos de lenguaje previamente capacitados , para aparecer en INLG 2022. El documento introduce un método para pedirle a un PLM para componer un plan de contenido. Luego, generamos el cuerpo de la historia y el final condicionado en el plan de contenido. Además, adoptamos un enfoque de generación y rango mediante el uso de PLM adicionales para clasificar los pares generados (historia, finalización).
Este repositorio depende en gran medida de Dino. Como hicimos algunos cambios menores, incluimos el código completo para facilitar el uso.
Incluyendo ubicación, reparto, género y tema.
sh run_plot_static_gpu.shLos elementos del plan de contenido se generan una vez y se almacenan. Al generar las historias, el sistema muestra de los elementos de la trama generados fuera de línea.
sh run_plot_dynamic_gpu_single.shsh run_plot_dynamic_gpu_batch.sh--no_cuda a todos los comandos que llaman a dino.pyRequiere python3. Probado en Python 3.6 y 3.8.
pip3 install -r requirements.txt import nltk
nltk . download ( 'punkt' )
nltk . download ( 'stopwords' )Si utiliza el código en este repositorio, cite el siguiente documento:
@inproceedings{jin-le-2022-plot,
title = "Plot Writing From Pre-Trained Language Models",
author = "Jin, Yiping and Kadam, Vishakha and Wanvarie, Dittaya",
booktitle = "Proceedings of the 15th International Natural Language Generation conference",
year = "2022",
address = "Maine, USA",
publisher = "Association for Computational Linguistics"
}
Si usa Dino para otras tareas, también cita el siguiente documento:
@article{schick2020generating,
title={Generating Datasets with Pretrained Language Models},
author={Timo Schick and Hinrich Schütze},
journal={Computing Research Repository},
volume={arXiv:2104.07540},
url={https://arxiv.org/abs/2104.07540},
year={2021}
}


