OneForAll
1.0.0
Documento: https://arxiv.org/abs/2310.00149
Autores: Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, Muhan Zhang
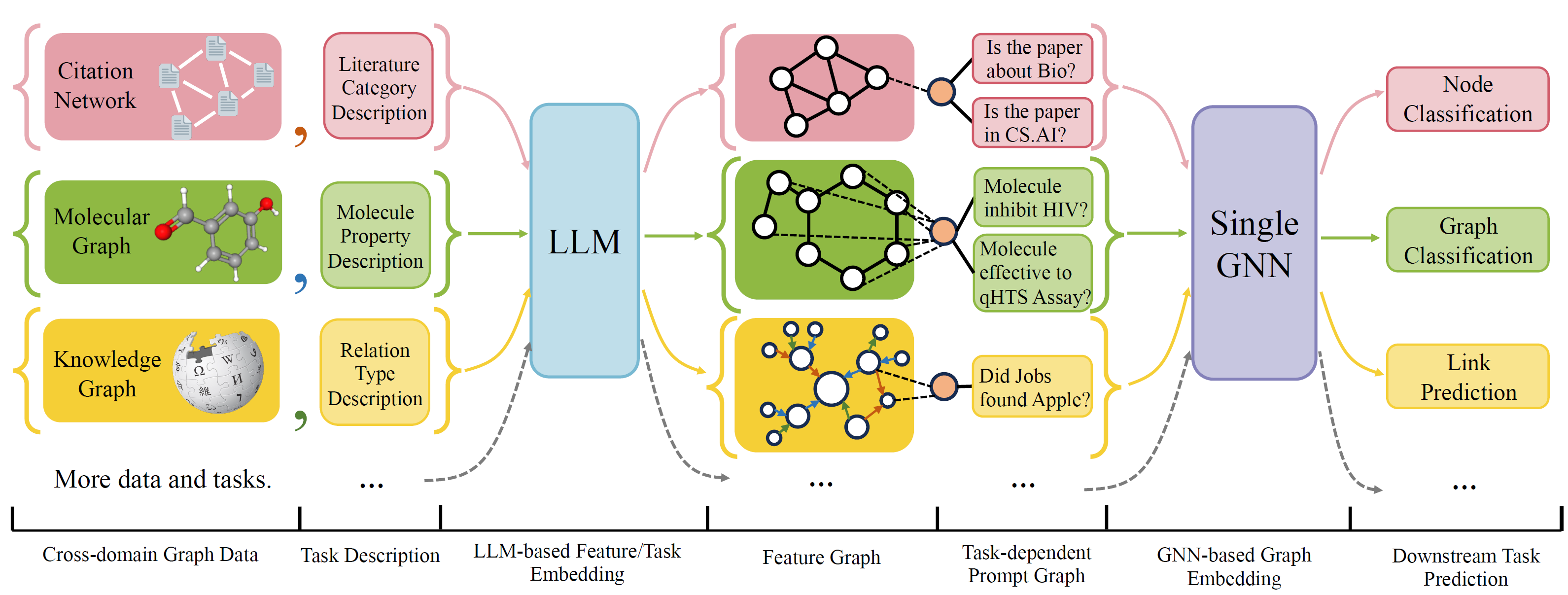
OFA es un marco general de clasificación de gráficos que puede resolver una amplia gama de tareas de clasificación de gráficos con un solo modelo y un solo conjunto de parámetros. Las tareas son el dominio cruzado (por ejemplo, la red de citas, gráfico molecular, ...) y las tareas cruzadas (por ejemplo, pocos disparos, disparos cero, nivel gráfico, nodo-leve, ...)
Ofa usa idiomas naturales para describir todos los gráficos y usa un LLM para incorporar toda la descripción en el mismo espacio de incrustación, lo que permite el entrenamiento de dominio cruzado usando un solo modelo.
OFA propone un paradiagm de incorporación de que toda la información de la tarea se convierte en gráfico indicado. Por lo tanto, el modelo de subsecuencia puede leer la información de las tareas y predecir el objetivo de relavado en consecuencia, sin tener que ajustar los parámetros y la arquitectura del modelo. Por lo tanto, un solo modelo puede ser una tarea cruzada.
OFA seleccionó una lista de conjuntos de datos de gráficos de diferentes fuentes y dominios y describe nodos/bordes en los gráficos con un protocolo de decricación sistemática. Agradecemos trabajos anteriores, incluidos, OGB, Gimlet, Moleculenet, Graphllm y Villmow por proporcionar maravillosos datos de gráficos/texto en bruto que hacen posible nuestro trabajo.
OneForall se sometió a una revisión importante, donde limpiamos el código y solucionamos varios errores reportados. Las principales actualizaciones son:
Si utilizó anteriormente nuestro repositorio, extraiga y elimine los antiguos archivos de características/texto generadas y regenerar. Lo siento por los inconvenientes ocasionados.
Para instalar requisitos para el proyecto usando conda:
conda env create -f environment.yml
Para experimentos conjuntos de extremo a extremo en todos los conjuntos de datos recopilados, ejecute
python run_cdm.py --override e2e_all_config.yaml
Todos los argumentos pueden ser cambiados por valores separados por espacio como
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
Los usuarios pueden modificar la variable task_names en ./e2e_all_config.yaml para controlar qué conjuntos de datos se incluyen durante la capacitación. La longitud de task_names , d_multiple y d_min_ratio debería ser la misma. También se pueden especificar en los argumentos de la línea de comandos mediante valores separados por comas.
p.ej
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
Ofa-Ind se puede especificar por
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
Para ejecutar los experimentos de pocos disparos y cero disparos
python run_cdm.py --override lr_all_config.yaml
Definimos configuraciones para cada tarea, cada configuración de tareas contiene varias configuraciones de conjuntos de datos.
Las configuraciones de tareas se almacenan en ./configs/task_config.yaml . Una tarea generalmente consiste en varias divisiones de conjuntos de datos (no necesariamente los mismos conjuntos de datos). Por ejemplo, una tarea regular de clasificación de nodo Cora de extremo a extremo tendrá la división de tren del conjunto de datos CORA como conjunto de datos del tren, la división válida del conjunto de datos CORA como uno de los conjuntos de datos válidos, y también para la división de prueba. También puede tener más validación/prueba especificando la división del tren de la Cora como uno de los conjuntos de datos de validación/prueba. Específicamente, se ve una configuración de tareas como
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train split Las configuraciones del conjunto de datos se almacenan en ./configs/task_config.yaml . Una configuración del conjunto de datos define cómo se construye un conjunto de datos. Específicamente,
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 Si está implementando un conjunto de datos como Cora/PubMed/ARXIV, recomendamos agregar un directorio de sus datos $ Customized_Data $ en Data/single_graph/$ Customized_data $ e implementar gen_data.py en el directorio, puede usar datos/cora/gen_data. Py como ejemplo.
Después de construir los datos, debe registrar el nombre de su conjunto de datos aquí e implementar un divisor como aquí. Si está haciendo tareas de cero disparo/pocos disparos, también puede construir una división de pocos disparos/pocos disparos aquí.
Por último, registre una entrada de configuración en configs/data_config.yaml. Por ejemplo, para la clasificación de nodo de extremo a extremo
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$Process_label_func convierte la etiqueta de destino a la etiqueta binaria y la incrustación de la clase de transformación si la tarea es cero disparo/pocos disparos, donde el número de nodo de clase no se fija. Aquí está una lista de Avalailable Process_Label_Func. Toma todas las clases incrustando y la etiqueta correcta. La salida es una tupla: (etiqueta, class_node_embedding, etiqueta binaria/única).
Si desea más flexibilidad, entonces agregar conjuntos de datos personalizados requiere la implementación de una subclase personalizada de OfapygDataSet. Una plantilla está aquí:
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

