text embeddings inference
v1.5.1
Una solución de inferencia rápida para los modelos de incrustaciones de texto.
Benchmark para BAAI/BGE-BASE-EN-V1.5 en un Nvidia A10 con una longitud de secuencia de 512 tokens:
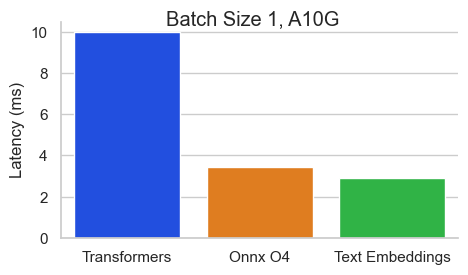
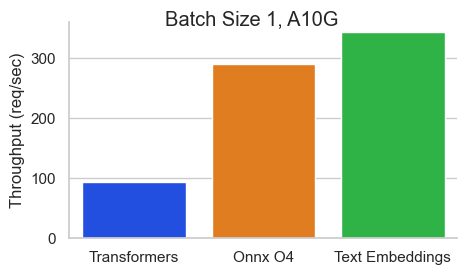
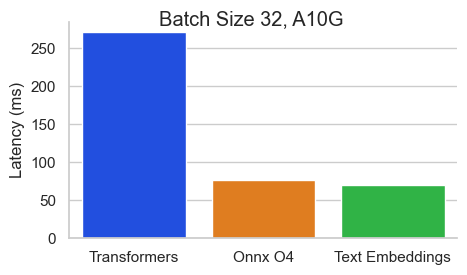
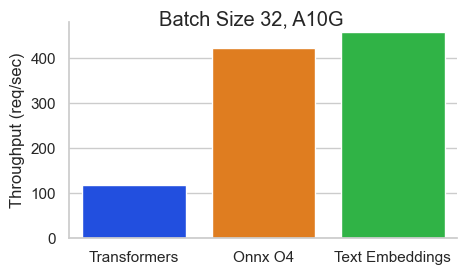
La inferencia de incrustaciones de texto (TEI) es un conjunto de herramientas para implementar y servir incrustaciones de texto de código abierto y modelos de clasificación de secuencia. TEI permite la extracción de alto rendimiento para los modelos más populares, incluidos los flagembedding, Ember, GTE y E5. TEI implementa muchas características como:
Los modelos de incrustaciones de texto actualmente admiten modelos Nomic, Bert, Camembert, XLM-Roberta con posiciones absolutas, modelo Jinabert con posiciones de Alibi y modelos Mistral, Alibaba GTE y QWEN2 con posiciones de cuerda.
A continuación hay algunos ejemplos de los modelos actualmente compatibles:
| Rango mteB | Tamaño del modelo | Tipo de modelo | ID de modelo |
|---|---|---|---|
| 1 | 7b (muy caro) | Mistral | Salesforce/SFR-Embedding-2_R |
| 2 | 7b (muy caro) | Qwen2 | Alibaba-NLP/GTE-Qwen2-7b-Instructo |
| 9 | 1.5b (caro) | Qwen2 | Alibaba-NLP/GTE-Qwen2-1.5B-Instructo |
| 15 | 0.4b | Alibaba GTE | Alibaba-NLP/GTE-Large-En-V1.5 |
| 20 | 0.3b | Bert | WhereISAI/UAE-LARGE-V1 |
| 24 | 0.5b | XLM-Roberta | INTFLOAT/Multilingüe-E5-Large-Instructo |
| N / A | 0.1b | Nomicbert | nomic-ai/nomic-embebido-text-v1 |
| N / A | 0.1b | Nomicbert | nomic-ai/nomic-embebido-text-v1.5 |
| N / A | 0.1b | Jinabert | Jinai/Jina-Embeddings-V2-Base-en |
| N / A | 0.1b | Jinabert | Jinaai/Jina-Embeddings-V2-Base-Code |
Para explorar la lista de modelos de incrustaciones de texto de mejor rendimiento, visite la tabla de clasificación de referencia de incrustación de texto masivo (MTEB).
La inferencia de incrustaciones de texto actualmente admite modelos de clasificación de secuencia XLM-Roberta con posiciones absolutas.
A continuación hay algunos ejemplos de los modelos actualmente compatibles:
| Tarea | Tipo de modelo | ID de modelo |
|---|---|---|
| Reanimación | XLM-Roberta | Baai/BGE-Reranker-Large |
| Reanimación | XLM-Roberta | Baai/BGE-Reranker-Base |
| Reanimación | Gte | Alibaba-NLP/GTE-Multililingüe-Rerker-Base |
| Análisis de sentimientos | Roberta | Samlowe/Roberta-Base-go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelY luego puedes hacer solicitudes como
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json 'Nota: Para usar GPU, debe instalar el kit de herramientas NVIDIA Container. Los controladores NVIDIA en su máquina deben ser compatibles con CUDA versión 12.2 o superior.
Para ver todas las opciones para servir a sus modelos:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
Se envía una inferencia de incrustaciones de texto con múltiples imágenes de Docker que puede usar para apuntar a un backend específico:
| Arquitectura | Imagen |
|---|---|
| UPC | ghcr.io/hugggingface/text-embeddings-inferencia:CPU-1.5 |
| Volta | No compatible |
| Turing (T4, RTX 2000 Serie, ...) | ghcr.io/huggingface/text-embeddings-Inferencia:Turing-1.5 (experimental) |
| Amperio 80 (A100, A30) | ghcr.io/hugggingface/text-embeddings-Inferencia:1.5 |
| Ampere 86 (A10, A40, ...) | ghcr.io/huggingface/Text-embeddings-Inferencia:86-1.5 |
| Ada Lovelace (serie RTX 4000, ...) | ghcr.io/hugggingface/text-embeddings-inferencia:89-1.5 |
| Tolva (H100) | ghcr.io/huggingface/text-embeddings-Inferencia:Hopper-1.5 (experimental) |
ADVERTENCIA : La atención flash se desactiva de forma predeterminada para la imagen de Turing, ya que sufre de problemas de precisión. Puede activar Flash Attence V1 utilizando la variable USE_FLASH_ATTENTION=True Environment.
Puede consultar la documentación de OpenAPI de la API REST text-embeddings-inference utilizando la ruta /docs . La interfaz de usuario de Swagger también está disponible en: https://huggingface.github.io/text-embeddings-inference.
Tiene la opción de utilizar la variable de entorno HF_API_TOKEN para configurar el token empleado por text-embeddings-inference . Esto le permite obtener acceso a recursos protegidos.
Por ejemplo:
HF_API_TOKEN=<your cli READ token>o con Docker:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelPara implementar la inferencia de incrustaciones de texto en un entorno de aire, primero descargue las pesas y luego monte las dentro del contenedor con un volumen.
Por ejemplo:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference V0.4.0 agregó soporte para modelos de clasificación de secuencia Camembert, Roberta, XLM-Roberta y GTE. Los modelos de re-rankers son modelos cruzados de clasificación de secuencia con una sola clase que califica la similitud entre una consulta y un texto.
Vea esta publicación en el blog del equipo de Llamaindex para comprender cómo puede usar modelos de re-rankers en su tubería RAG para mejorar el rendimiento posterior.
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelY luego puede clasificar la similitud entre una consulta y una lista de textos con:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' También puede usar modelos de clasificación de secuencia clásica como SamLowe/roberta-base-go_emotions :
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model Una vez que haya implementado el modelo, puede usar el punto final predict para obtener las emociones más asociadas con una entrada:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'Puede optar por activar la agrupación de fallas para las arquitecturas de Maskedlm de Bert y Distilbert:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade Una vez que haya implementado el modelo, puede usar el punto final /embed_sparse para obtener la escasa incrustación:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' text-embeddings-inference se instrumenta con el rastreo distribuido utilizando OPENTELEMETRY. Puede usar esta función configurando la dirección en un coleccionista OTLP con el argumento --otlp-endpoint .
text-embeddings-inference ofrece una API GRPC como alternativa a la API HTTP predeterminada para implementaciones de alto rendimiento. La definición API ProtoBuf se puede encontrar aquí.
Puede usar la API GRPC agregando la etiqueta -grpc a cualquier imagen TEI Docker. Por ejemplo:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed También puede optar por instalar text-embeddings-inference localmente.
Primera instalación de óxido:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shLuego corre:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalAhora puede iniciar inferencia de incrustaciones de texto en CPU con:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Nota: En algunas máquinas, también puede necesitar las bibliotecas OpenSSL y el GCC. En las máquinas Linux, ejecute:
sudo apt-get install libssl-dev gcc -yLas GPU con capacidades de cómputo CUDA <7.5 no son compatibles (V100, Titan V, GTX 1000 Series, ...).
Asegúrese de tener instalados CUDA y los controladores NVIDIA. Los controladores NVIDIA en su dispositivo deben ser compatibles con CUDA versión 12.2 o superior. También debe agregar los binarios nvidia a su camino:
export PATH= $PATH :/usr/local/cuda/binLuego corre:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresAhora puede iniciar una inferencia de incrustaciones de texto en GPU con:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Puede construir el contenedor de CPU con:
docker build .Para construir los contenedores CUDA, debe conocer el límite de cómputo de la GPU que usará en tiempo de ejecución.
Entonces puede construir el contenedor con:
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capComo se explica aquí, listo para los MPS, la imagen de Docker ARM64, el metal / MPS no es compatible con Docker. Ya que tal inferencia estará unida a CPU y probablemente bastante lenta cuando se usa esta imagen Docker en una CPU ARM M1/M2.
docker build . -f Dockerfile --platform=linux/arm64


