pytorch openai transformer lm
1.0.0
Esta es una implementación de Pytorch del código TensorFlow proporcionado con el documento de OpenAI "Mejora de la comprensión del lenguaje mediante la pretruación generativa" de Alec Radford, Karthik Narasimhan, Tim Salimans e Ilya Sutskever.
Esta implementación comprende un script para cargar en el modelo Pytorch los pesos previamente entrenados por los autores con la implementación de TensorFlow.
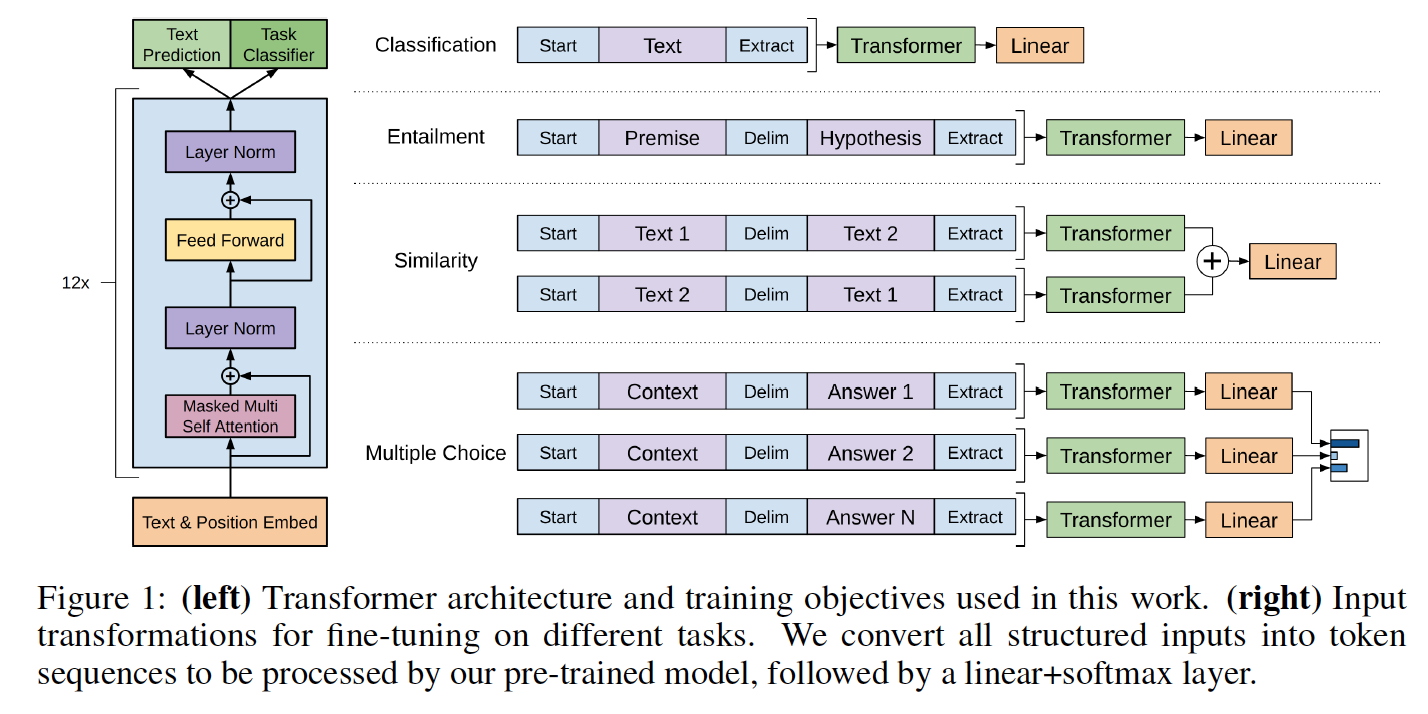
Las clases de modelo y el script de carga se encuentran en model_pytorch.py.
Los nombres de los módulos en el modelo Pytorch siguen los nombres de la variable en la implementación de TensorFlow. Esta implementación intenta seguir el código original lo más cerca posible para minimizar las discrepancias.
Por lo tanto, esta implementación también comprende un algoritmo de optimización de ADAM modificado como se usa en el documento de OpenAI con:
Para usar el modelo IT-Self importando model_pytorch.py, solo necesita:
Para ejecutar el script de entrenamiento del clasificador en Train.py necesitará además:
Puede descargar los pesos de la versión pre-entrenada de Operai clonando el repositorio de Alec Radford y colocando la carpeta model que contiene los pesos previamente capacitados en el repositorio actual.
El modelo se puede utilizar como modelo de lenguaje de transformador con los pesos previamente capacitados de OpenAI de la siguiente manera:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) Este modelo genera los estados ocultos del transformador. Puede usar la clase LMHead en model_pytorch.py para agregar un decodificador atado con los pesos del codificador y obtener un modelo de lenguaje completo. También puede usar la clase ClfHead en model_pytorch.py para agregar un clasificador encima del transformador y obtener un clasificador como se describe en la publicación de OpenAI. (Vea un ejemplo de ambos en la función __main__ de Train.py)
Para usar el codificador posicional del transformador, debe codificar su conjunto de datos utilizando la función encode_dataset() de utils.py. Consulte el comienzo de la función __main__ en Train.py para ver cómo definir correctamente el vocabulario y codificar su conjunto de datos.
Este modelo también se puede integrar en un clasificador como se detalla en el artículo de OpenAI. Un ejemplo de ajuste en la tarea de Cloze de Rocstories se incluye con el código de entrenamiento en Train.py
El conjunto de datos ROCSTORies se puede descargar desde el sitio web asociado.
Al igual que con el código TensorFlow, este código implementa el resultado de la prueba de cloze ROCSTORES informado en el documento que puede reproducirse ejecutándose:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Finizar el modelo Pytorch para 3 épocas en Rocstories tarda 10 minutos en ejecutarse en un solo NVIDIA K-80.
La precisión de la prueba de ejecución única de esta versión de Pytorch es del 85.84%, mientras que los autores informan una precisión media con el código TensorFlow de 85.8%y el documento informa una mejor precisión de la ejecución única del 86.5%.
Las implementaciones de autores usan 8 GPU y, por lo tanto, pueden acomodar un lote de 64 muestras, mientras que la implementación actual es una sola GPU y, en consecuencia, se limita a 20 instancias en un K80 por razones de memoria. En nuestra prueba, aumentar el tamaño del lote de 8 a 20 muestras aumentó la precisión de la prueba en 2.5 puntos. Se puede obtener una mejor precisión utilizando una configuración de múltiples GPU (aún no se ha probado).
El Sota anterior en el conjunto de datos ROCSTORies es el 77.6% ("Modelo de coherencia oculta" de Chaturvedi et al. Publicado en "Comprensión de la historia para predecir lo que sucede Next" EMNLP 2017, que también es un documento muy agradable!


