lang2sql
1.0.0
Este repositorio proporciona una guía paso a paso y una plantilla para configurar un generador de código de lenguaje natural a SQL con la API OPNEAI.
El tutorial también está disponible en medio.
Última actualización: 7 de enero, 2024
El rápido desarrollo de modelos de lenguaje natural, especialmente modelos de lenguaje grande (LLMS), ha presentado numerosas posibilidades para varios campos. Una de las aplicaciones más comunes es el uso de LLM para la codificación. Por ejemplo, el CHATGPT de OpenAI y el código de código de Meta son LLM que ofrecen lenguaje natural de última generación a generadores de código. Un caso de uso potencial es un lenguaje natural para el generador de código SQL, que podría ayudar a los profesionales no técnicos con solicitudes de datos simples y, con suerte, permitir que los equipos de datos se centren en tareas más intensivas en datos. Este tutorial se centra en configurar un idioma para el generador de código SQL utilizando la API de OpenAI.
Una posible aplicación es un chatbot que puede responder a las consultas de los usuarios con datos relevantes (Figura 1). El chatbot se puede integrar con un canal de holgura utilizando una aplicación Python que realiza los siguientes pasos:
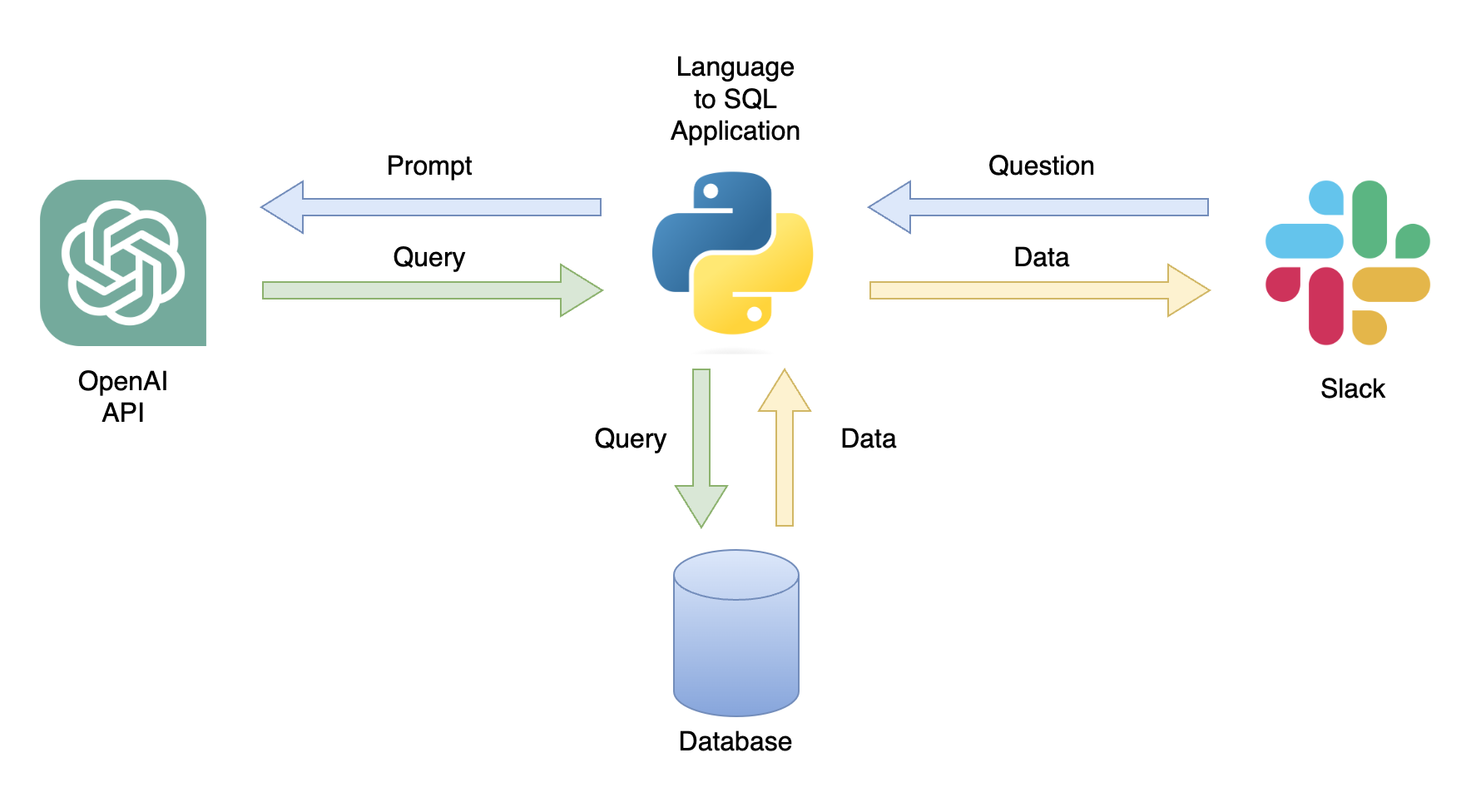
En este tutorial, construiremos una aplicación Python paso a paso que convierta las preguntas de los usuarios en consultas SQL.
Este tutorial proporciona una guía paso a paso sobre cómo configurar una aplicación de Python que convierta las preguntas generales en consultas SQL utilizando la API de OpenAI. Que incluye la siguiente funcionalidad:
La Figura 2 a continuación describe la arquitectura general de un lenguaje simple para el generador de código SQL.
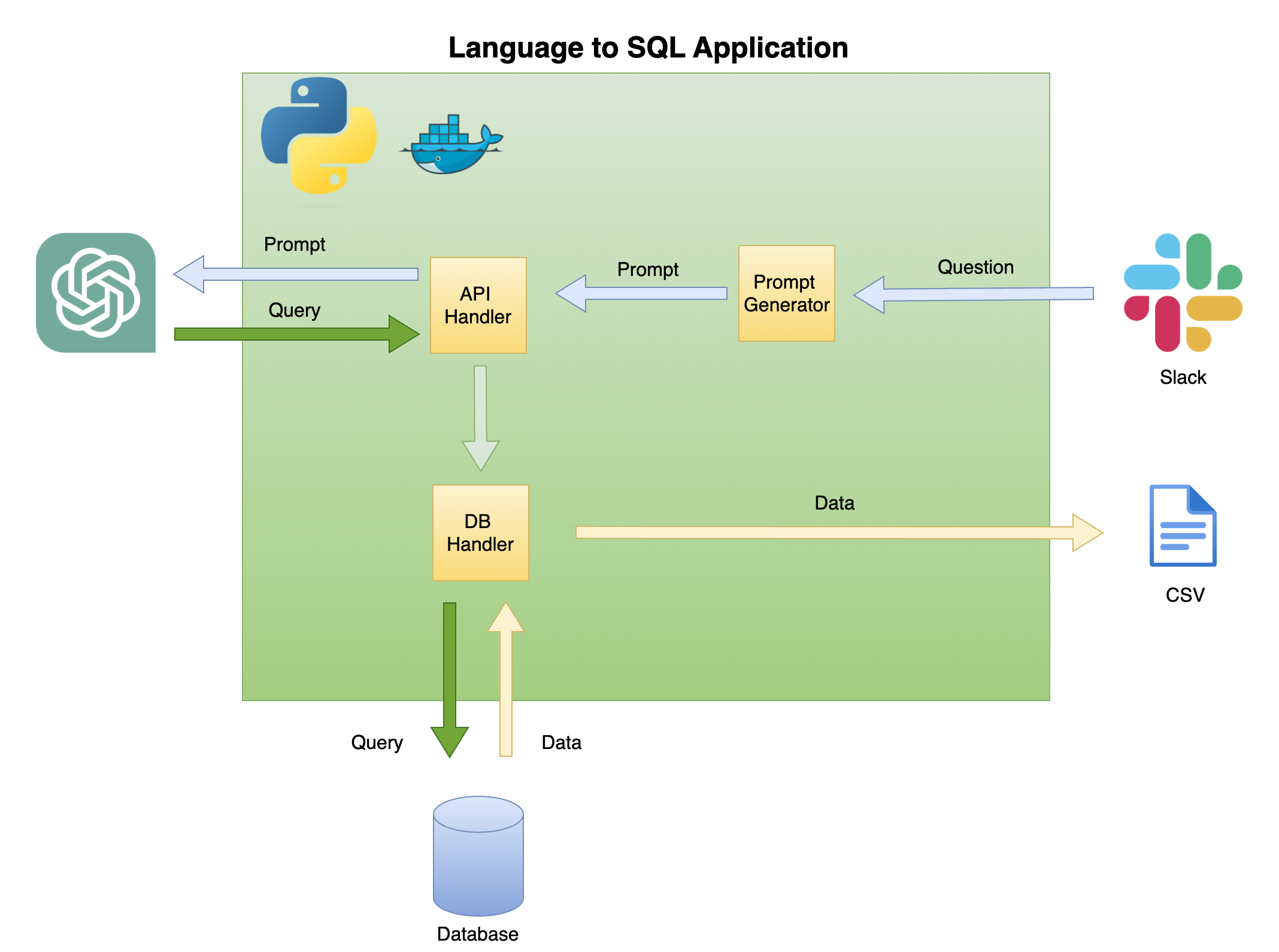
El alcance y el enfoque de este tutorial están en la caja verde: construir la siguiente funcionalidad:
Pregunta para solicitar : transformar la pregunta en un formato de inmediato:
API Handler : una función que funciona con la API de OpenAI:
DB Handler : una función que envía la consulta SQL a la base de datos y devuelve los datos requeridos
El principal requisito previo para este tutorial es el conocimiento básico de Python. Que incluye la siguiente funcionalidad:
Además, se requieren conocimientos básicos de SQL y acceso a la API de OpenAI.
Si bien no es necesario, es útil tener un conocimiento básico de Docker, ya que el tutorial se creó en un entorno dockerizado utilizando la extensión de contenedores Dev de VScode. Si no tiene experiencia con Docker o la extensión, aún puede ejecutar el tutorial creando un entorno virtual e instalando las bibliotecas requeridas (como se describe a continuación). El conocimiento de la ingeniería rápida y la API de OpenAI también es beneficioso.
Creé un tutorial detallado sobre la configuración de un entorno dockerizado de Python con VScode y la extensión de contenedores de desarrollo:
https://github.com/ramikrispin/vscode-python
Para configurar un lenguaje natural para la generación de código SQL, utilizaremos las siguientes bibliotecas de Python:
pandas : para procesar datos durante todo el procesoduckdb - para simular el trabajo con la base de datosopenai - para trabajar con la API de Operaitime y os : para cargar archivos CSV y campos de formatoEste repositorio contiene la configuración necesaria para iniciar un entorno dockerizado con los requisitos tutoriales en VScode y la extensión de contenedores de desarrollo. Hay más detalles disponibles en la siguiente sección.
Alternativamente, puede configurar un entorno virtual e instalar los requisitos del tutorial siguiendo las instrucciones a continuación utilizando las instrucciones en la sección de entorno virtual.
Este tutorial se construyó dentro de un entorno dockerizado con VScode y la extensión de contenedores de desarrollo. Para ejecutarlo con VScode, deberá instalar la extensión de contenedores de Dev y hacer que Docker Desktop (o equivalente) sea abierto. La configuración del entorno está disponible en la carpeta .devcontainer :
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
devcontainer.json tiene las instrucciones de compilación y la configuración de VScode para este entorno documentado:
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
Donde el argumento build define el método docker build y establece los argumentos para la compilación. En este caso, establecemos la versión de Python en 3.10 , y el entorno virtual Conda en ang2sql . El argumento METHOD define el tipo de entorno: ya sea openai para instalar las bibliotecas de requisitos para este tutorial utilizando la API o transformers de OpenAI para establecer el entorno para HuggingFaces API (que está fuera de alcance para este tutorial).
El argumento remoteEnv permite establecer variables de entorno. Lo usaremos para establecer la tecla API OpenAI. En este caso, configuré la variable localmente como OPENAI_KEY , y la estoy cargando usando el argumento localEnv .
Si desea obtener más información sobre cómo configurar un entorno de desarrollo de Python con VScode y Docker, consulte este tutorial.
Si no está utilizando el entorno dockerized tutorial, puede crear un entorno virtual local a partir de la línea de comandos utilizando el script a continuación:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
Nota: Utilicé conda y también debería funcionar con cualquier otro método de entorno virutal.
Utilizamos las variables ENV_NAME y PYTHON_VER para establecer el entorno virtual y la versión de Python, respectivamente.
Para confirmar que su entorno está configurado correctamente, use la conda list para confirmar que se instalan las bibliotecas de Python requeridas. Debe esperar la siguiente salida:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
Utilizaremos la API de OpenAI para acceder a ChatGPT usando el motor Text-Davinci-003. Esto requirió una cuenta activa de OpenAI y una clave API. Es sencillo establecer una cuenta de cuenta y API siguiendo las instrucciones en el siguiente enlace:
https://openai.com/product
Una vez que establezca el acceso a la API y una clave, le recomiendo agregar la clave como una variable de entorno a su archivo .zshrc (o cualquier otro formato que esté utilizando para almacenar variables de entorno en su sistema de shell). Almacené mi tecla API bajo la variable de entorno OPENAI_KEY . Por razones convincentes, le recomiendo que use la misma convención de nombres.
Para establecer la variable en el archivo .zshrc (o equivalente), agregue la línea a continuación al archivo:
export OPENAI_KEY= " YOUR_API_KEY " Si usa VScode o se ejecuta desde el terminal, debe reiniciar su sesión después de agregar la variable al archivo .zshrc .
Para simular la funcionalidad de la base de datos, utilizaremos el conjunto de datos de crimen de Chicago. Este conjunto de datos proporciona información en profundidad sobre los crímenes registrados en la ciudad de Chicago desde 2001. Con cerca de 8 millones de registros y 22 columnas, el conjunto de datos incluye información como la clasificación del crimen, ubicación, tiempo, resultado, etc. Los datos están disponibles para descargar desde el portal de datos de Chicago. Dado que almacenamos los datos localmente como marco de datos de Pandas y usamos DuckDB para simular la consulta SQL, descargaremos un subconjunto de los datos utilizando los últimos tres años.
Puede extraer los datos de la API o descargar un archivo CSV. Para evitar llamar a la API cada vez que ejecuto el script, descargo los archivos y los almaceno en la carpeta de datos. A continuación se presentan los enlaces a los conjuntos de datos por año:
Para descargar los datos, use el botón Export en la parte superior derecha, seleccione la opción CSV y haga clic en el botón Download , como se ve en la Figura 4.
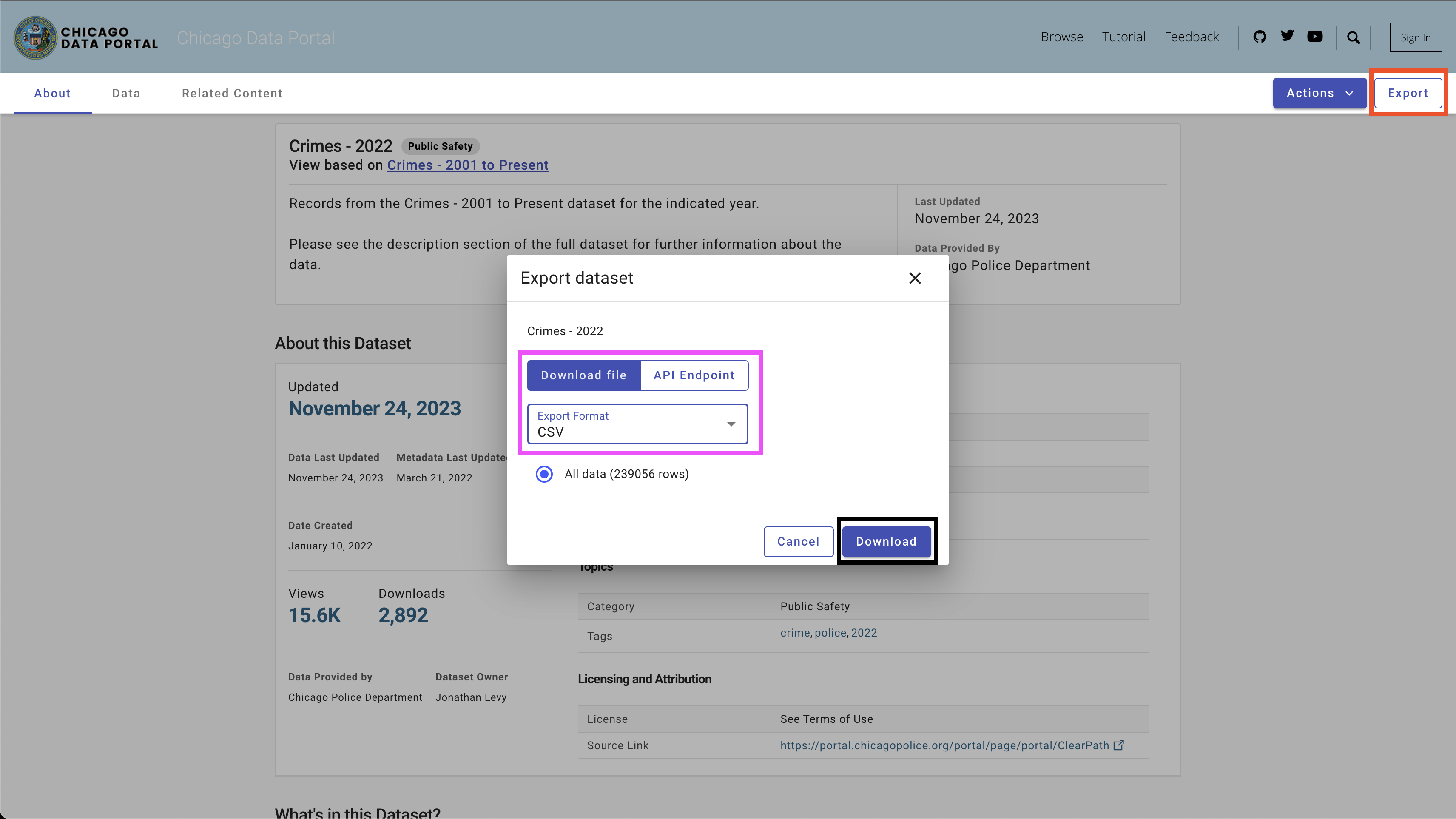
Utilicé la siguiente convención de nombres: Chicago_crime_year.csv y guardé los archivos en la carpeta data . Cada tamaño de archivo está cerca de 50 MB. Por lo tanto, los agregué al archivo Git Ignore en la carpeta data , y no están disponibles en este repositorio. Después de descargar los archivos y configurar sus nombres, debe tener los siguientes archivos en la carpeta:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
Nota: En el momento de crear este tutorial, los datos para 2023 aún se están actualizando. Por lo tanto, puede recibir resultados ligeramente diferentes al ejecutar algunas de las consultas en la siguiente sección.
Pasemos a la parte emocionante, que está configurando un generador de código SQL. En esta sección, crearemos una función de Python que recibe la pregunta de un usuario, la tabla SQL asociada y la clave API OpenAI y emite la consulta SQL que responde a la pregunta del usuario.
Comencemos cargando el conjunto de datos de crimen de Chicago y las bibliotecas de Python requeridas.
Lo primero es lo primero: cargemos las bibliotecas de Python requeridas:
import pandas as pd
import duckdb
import openai
import time
import osUtilizaremos el sistema operativo y las bibliotecas de tiempo para cargar archivos CSV y reformatear ciertos campos. Los datos se procesarán utilizando la biblioteca Pandas , y simularemos los comandos SQL con la biblioteca DuckDB . Por último, estableceremos una conexión con la API de OpenAI utilizando la Biblioteca Operai .
A continuación, cargaremos los archivos CSV en la carpeta de datos. El siguiente código lee todos los archivos CSV disponibles en la carpeta de datos:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]Si descargó los archivos correspondientes para los años 2021 a 2023 y usó la misma convención de nomenclatura, debe esperar la siguiente salida:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]A continuación, leeremos y cargaremos todos los archivos y los agregaremos en un marco de datos de Pandas:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headSi cargó correctamente los archivos, debe esperar la siguiente salida:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) Nota: Al crear este tutorial, estaban disponibles datos parciales para 2023. Agregar los tres archivos daría como resultado más filas de las que se muestran (648830 filas).
Antes de entrar en el código de Python, hagamos una pausa y revisemos cómo funciona la ingeniería rápida y cómo podemos ayudar a ChatGPT (y generalmente cualquier LLM) a generar los mejores resultados. Usaremos en esta sección la interfaz web CHATGPT.
Un factor importante en los modelos estadísticos y de aprendizaje automático es que la calidad de salida depende de la calidad de entrada. Como dice la famosa frase: basura, basura . Del mismo modo, la calidad de la salida LLM depende de la calidad de la solicitud.
Por ejemplo, supongamos que queremos contar el número de casos que terminaron con un arresto.
Si usamos el siguiente mensaje:
Create an SQL query that counts the number of records that ended up with an arrest.
Aquí está el resultado de chatgpt:
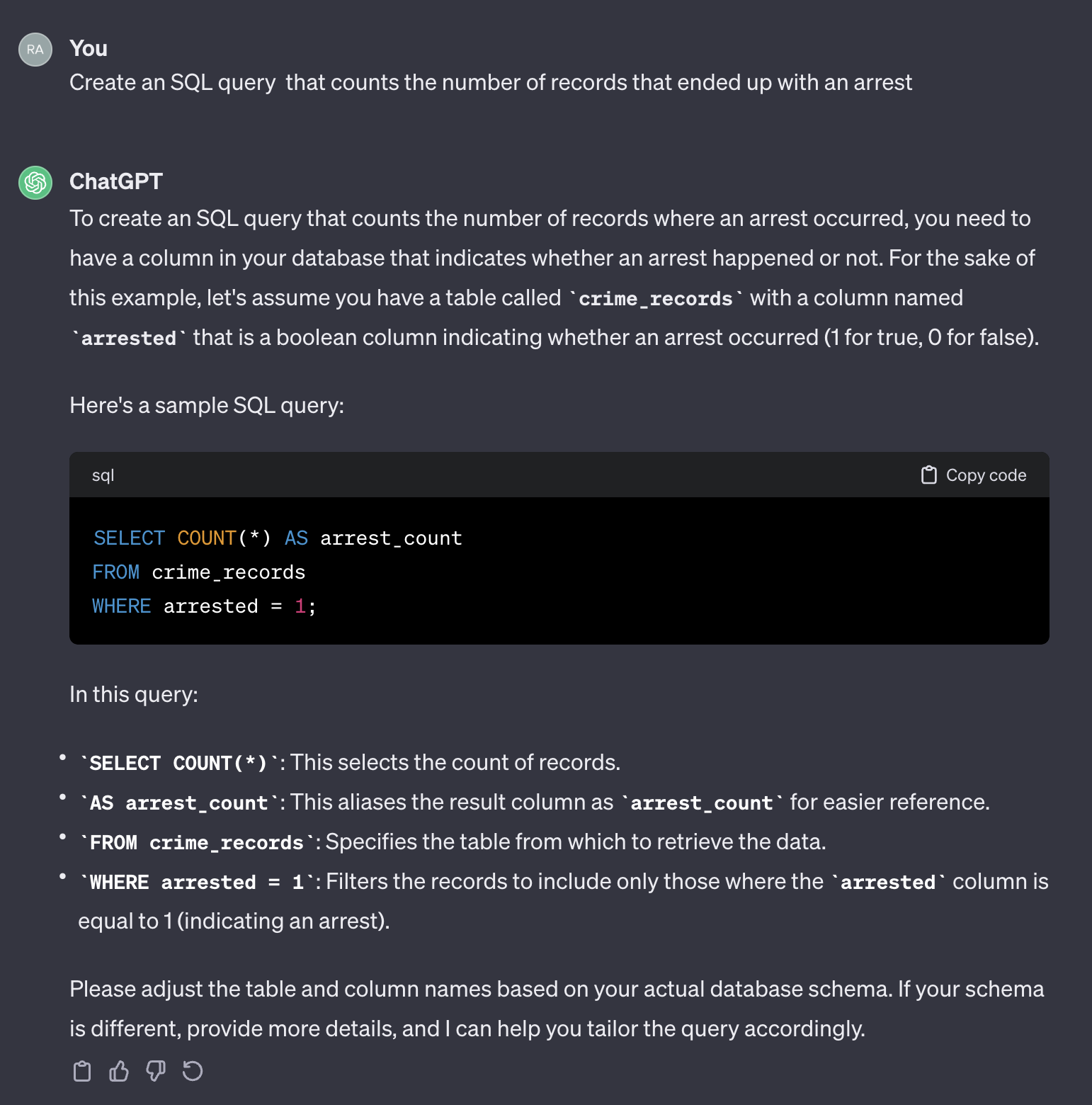
Vale la pena señalar que ChatGPT proporciona una respuesta genérica. Aunque generalmente es correcto, puede no ser práctico usarlo en un proceso automatizado. En primer lugar, los nombres de campo en la respuesta no coinciden con los de la tabla real que necesitamos consultar. En segundo lugar, el campo que representa el resultado del arresto es un booleano ( true o false ) en lugar de un entero ( 0 o 1 ).
Chatgpt, en ese sentido, actúa como un humano. Es poco probable que reciba una respuesta más precisa de un humano al publicar la misma pregunta en un formulario de codificación como Stack Overflow o cualquier otra plataforma similar. Dado que no proporcionamos ningún contexto o información adicional sobre las características de la tabla, esperando que ChatGPT adivine los nombres de campo y sus valores no serían razonables. El contexto es un factor crucial en cualquier aviso. Para ilustrar este punto, veamos cómo ChatGPT maneja el siguiente mensaje:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
Aquí está el resultado de chatgpt:
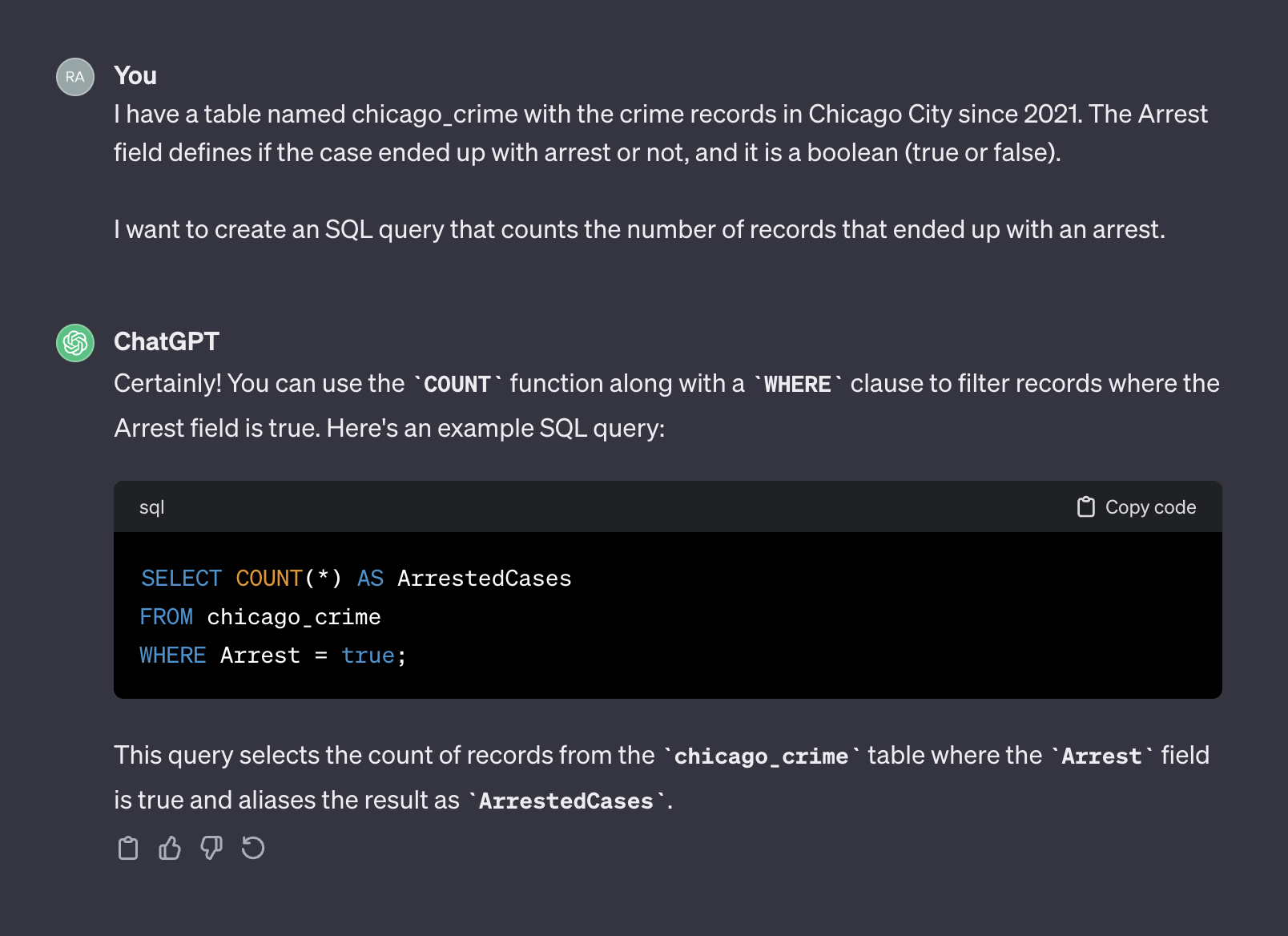
Esta vez, después de agregar contexto, ChatGPT devolvió una consulta correcta que podemos usar como es. En general, cuando se trabaja con un generador de texto, el mensaje debe incluir dos componentes: contexto y solicitud. En el aviso anterior, el primer párrafo representa el contexto del aviso:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
Donde el segundo párrafo representa la solicitud:
I want to create an SQL query that counts the number of records that ended up with an arrest.
La API de OpenAI se refiere al contexto como un system y solicita como user .
La documentación de la API de OpenAI proporciona una recomendación sobre cómo establecer el system y los componentes user en un mensaje al solicitar que genere un código SQL:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
En la siguiente sección, usaremos el ejemplo de OpenAI anterior y lo generalizaremos en una plantilla de propósito general.
En la sección anterior, discutimos la importancia de la ingeniería rápida y cómo proporcionar un buen contexto puede mejorar la precisión de la respuesta de LLM. Además, vimos la estructura rápida recomendada de OpenAI para la generación de código SQL. En esta sección, nos centraremos en generalizar el proceso de creación de indicaciones para la generación SQL en función de esos principios. El objetivo es construir una función de Python que reciba un nombre de tabla y una pregunta del usuario y crea el mensaje en consecuencia. Por ejemplo, para la tabla de chicago_crime que cargamos antes y la pregunta que hicimos en la sección anterior, la función debe crear el siguiente mensaje:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
Comencemos con la estructura rápida. Adoptaremos el formato OpenAI y usaremos la siguiente plantilla:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" Donde el system_template recibió dos elementos:
Para este tutorial, utilizaremos la biblioteca DuckDB para manejar el marco de datos de los pandas, ya que era una tabla SQL y extraeremos los nombres y atributos de la tabla utilizando la función duckdb.sql . Por ejemplo, usemos el comando DESCRIBE SQL para extraer la información de campos de tabla de chicago_crime :
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )Que debería devolver la tabla a continuación:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘Nota: La información que necesitamos: el nombre de la columna y su atributo están disponibles en las dos primeras columnas. Por lo tanto, necesitaremos analizar esas columnas y combinarlas con el siguiente formato:
Column_Name Column_Attribute
Por ejemplo, la columna Case Number debe transferirse al siguiente formato:
Case Number VARCHAR
La función create_message a continuación orquesta el proceso de tomar el nombre de la tabla y la pregunta y generar el indicador utilizando la lógica anterior:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m La función crea la plantilla de solicitud y devuelve el system de solicitud y los componentes user y los nombres y atributos de las columnas. Por ejemplo, ejecutemos el número de preguntas de arresto:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )Esto volverá:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object La salida de la función create_message fue diseñada para adaptarse a los argumentos de la función OpenAI API ChatCompletion.create , que revisaremos en la siguiente sección.
Esta sección se centra en la funcionalidad de la Biblioteca OpenAi Python. La biblioteca OpenAI permite un acceso sin problemas a la API REST de OpenAI. Utilizaremos la biblioteca para conectarse a la API y enviar solicitudes GET con nuestro mensaje.
Comencemos conectándonos a la API alimentando nuestra API a la función openai.api_key :
openai . api_key = os . getenv ( 'OPENAI_KEY' ) Nota: Utilizamos la función getenv desde la biblioteca os para cargar la variable de entorno OpenAI_Key. Alternativamente, puede alimentar directamente su clave API:
openai . api_key = "YOUR_OPENAI_API_KEY"La API de OpenAI proporciona acceso a una variedad de LLM con diferentes funcionalidades. Puede usar la función OpenAI.Model.List para obtener una lista de los modelos disponibles:
openai . Model . list () Para transformarlo en un formato agradable, puede envolverlo en un marco de datos pandas :
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headY debe esperar la siguiente salida:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
Para nuestro caso de uso, generación de texto, utilizaremos el modelo gpt-3.5-turbo , que es una mejora del modelo GPT3. El modelo gpt-3.5-turbo representa una serie de modelos que se siguen actualizando, y de manera predeterminada, si no se especifica la versión del modelo, la API señalará la versión estable más reciente. Al crear este tutorial, el modelo 3.5 predeterminado fue gpt-3.5-turbo-0613 , utilizando 4,096 tokens, y entrenado con datos hasta septiembre de 2021.
Para enviar una solicitud GET con nuestro aviso, utilizaremos la función ChatCompletion.create . La función tiene muchos argumentos, y usaremos los siguientes:
model : la ID del modelo para usar, una lista completa disponible aquímessages : una lista de mensajes que comprenden la conversación hasta ahora (por ejemplo, el aviso)temperature : gestione la aleatoriedad o el determinismo de la salida del proceso estableciendo el nivel de temperatura de muestreo. El nivel de temperatura acepta valores entre 0 y 2. Cuando el valor del argumento es más alto, la salida se vuelve más aleatoria. Por el contrario, cuando el valor del argumento está más cerca de 0, la salida se vuelve más determinista (reproducible)max_tokens : el número máximo de tokens para generar en la finalizaciónLa lista completa de los argumentos de función disponibles en la API DocumentAiton.
En el siguiente ejemplo, utilizaremos el mismo indicador que el utilizado en la interfaz web ChatGPT (es decir, la Figura 5), esta vez usando la API. Generaremos la solicitud con la función create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) Transformemos el indicador anterior en la estructura del argumento messages funciones de la función ChatCompletion.create .
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] A continuación, enviaremos el mensaje (es decir, el objeto message ) a la API usando la función ChatCompletion.create :
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) Estableceremos el argumento temperature en 0 para garantizar una alta reproducibilidad y limitaremos el número de tokens en la finalización del texto a 256. La función devuelve un objeto JSON con la finalización del texto, los metadatos y otra información:
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}Usando las indies de respuesta, podemos extraer la consulta SQL:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' Usando la función duckdb.sql para ejecutar el código SQL:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘En la siguiente sección, generalizaremos y funcionalizaremos todos los pasos.
En las secciones anteriores, introdujimos el formato de solicitud, establecemos la función create_message y revisamos la funcionalidad de la función ChatCompletion.create . En esta sección lo unimos todo.
Una cosa a tener en cuenta sobre el código SQL devuelto del ChatCompletion.create la función es que la variable no regresa con las cotizaciones. Eso podría ser un problema cuando el nombre de la variable en la consulta combina dos o más palabras. Por ejemplo, usar una variable como Case Number o Primary Type del chicago_crime dentro de una consulta sin usar cotizaciones dará como resultado un error.
Usaremos la función de ayuda a continuación para agregar citas a las variables en la consulta si la consulta devuelta no tiene una:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) Las entradas de la función son la consulta y los nombres de la columna de la tabla correspondiente. Supera los nombres de la columna y agrega citas si encuentra una coincidencia dentro de la consulta. Por ejemplo, podemos ejecutarlo con la consulta SQL que analizamos desde el ChatCompletion.create Función Salida:
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Puede notar que agregó citas a la variable Arrest .
Ahora podemos introducir la función lang2sql que aprovecha las tres funciones que presentamos hasta ahora: create_message , ChatCompletion.create y add_quotes para traducir una pregunta de usuario a un código SQL:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output La función recibe, como entradas, la tecla API de OpenAI, el nombre de la tabla y los parámetros centrales de la función ChatCompletion.create y devuelve un objeto con la solicitud, la respuesta API y la consulta analizada. Por ejemplo, intentemos volver a ejecutar la misma consulta que utilizamos en la sección anterior con la función lang2sql :
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )Podemos extraer la consulta SQL del objeto de salida:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;Podemos probar la salida con respecto a los resultados que recibimos en la sección anterior:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Ahora agregamos complejidad adicional a la pregunta y solicitemos casos que terminaron con un arresto durante 2022:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) Como puede ver, el modelo identificó correctamente el campo relevante como Year y generó la consulta correcta:
print ( response . sql )El código SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;Prueba de la consulta en la tabla:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘Aquí hay un ejemplo de una pregunta simple que requirió una agrupación por una variable específica:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Puede ver en la salida de respuesta que el código SQL en este caso es correcto:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "Esta es la salida de la consulta:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘Por último, pero no menos importante, el LLM puede identificar el contexto (por ejemplo, qué variable) incluso cuando proporcionamos un nombre de variable parcial:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Devuelve el siguiente código SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;Esta es la salida de la consulta:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘En este tutorial, hemos demostrado cómo construir un generador de código SQL con algunas líneas de código Python y utilizar la API de OpenAI. Hemos visto que la calidad del aviso es crucial para el éxito del código SQL resultante. Además del contexto proporcionado por el mensaje, los nombres de campo también deben proporcionar información sobre las características del campo para ayudar a la LLM a identificar la relevancia del campo para la pregunta del usuario.
Aunque este tutorial se limitó a trabajar con una sola tabla (por ejemplo, no se unen entre tablas), algunos LLM, como los disponibles en OpenAI, pueden manejar casos más complejos, incluido el trabajo con múltiples tablas e identificando las operaciones de unión correctas. Ajustar la función Lang2SQL para manejar varias tablas podría ser un buen paso siguiente.
Este tutorial tiene licencia bajo una licencia internacional de atribución creativa de los Comunes Commons-sharealike 4.0.


