super json mode
1.0.0
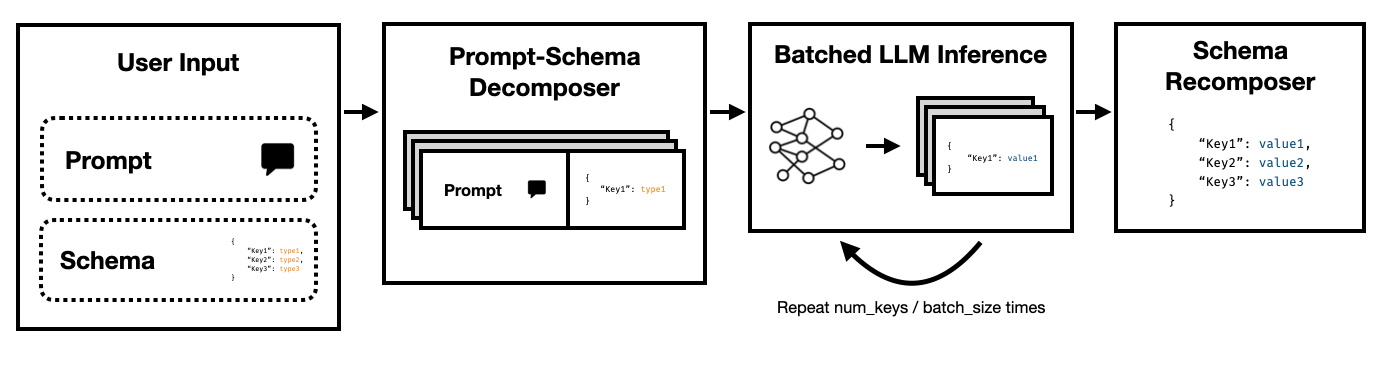
El modo Super JSON es un marco de Python que permite la creación eficiente de la salida estructurada de un LLM dividiendo un esquema objetivo en componentes atómicos y luego realizar generaciones en paralelo.
Admite ambos LLM de estado de última generación a través de la API Legacy Finalations de Openai y LLMS de código abierto, como a través de abrazando transformadores faciales y VLLM . ¡Más LLM serán compatibles pronto!
En comparación con una tubería de generación JSON ingenua que depende de la solicitud y los transformadores HF, encontramos que el modo Super JSON puede generar salidas hasta 10 veces más rápido . También es más determinista y es menos probable que se encuentre con problemas de análisis en comparación con la generación ingenua.
La instalación es simple: pip install super-json-mode
Los formatos de salida estructurados, como JSON o YAML, tienen una estructura paralela o jerárquica inherente.
Considere el siguiente pasaje no estructurado (generado por GPT-4):
Bienvenido a 123 Azure Lane, una impresionante residencia de San Francisco con un fantástico diseño contemporáneo, ahora en el mercado por $ 2,500,000. Extendiéndose sobre lujosos 3.000 pies cuadrados, esta propiedad combina sofisticación y comodidad para crear una experiencia de vida verdaderamente única.
Un hogar idílico para familias o profesionales, nuestra residencia exclusiva está equipada con cinco espaciosas habitaciones, cada una de las cosas que rezuman la calidez y la elegancia moderna. Las habitaciones están cuidadosamente planificadas para permitir una amplia luz natural y un espacio de almacenamiento generoso. Con tres baños completos elegantemente diseñados, la residencia garantiza la comodidad y la privacidad para sus residentes.
La gran entrada lo lleva a una espaciosa sala de estar, proporcionando un excelente ambiente para reuniones o una noche tranquila junto al fuego. La cocina del chef incluye electrodomésticos de última generación, gabinetes personalizados y hermosas encimeras de granito, lo que lo convierte en un sueño para cualquiera que le encanta cocinar.
Si queremos extraer address , square footage , number of bedrooms , number of bathrooms y price utilizando un LLM, podríamos pedirle al modelo que complete un esquema de acuerdo con la descripción.
Un posible esquema (como uno generado a partir de un objeto pydántico) podría verse así:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
Y una salida válida podría verse algo así:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
El enfoque obvio es anidar el esquema en el aviso y pedirle al modelo que lo complete. Así es como la mayoría de los equipos extraen actualmente la salida estructurada del texto no estructurado utilizando LLMS.
Sin embargo, esto es ineficiente por tres razones.
Observe cómo cada una de estas claves son independientes entre sí. El modo Super JSON aprovecha el paralelismo rápido al tratar cada par de valores clave en el esquema como una investigación separada. ¡Por ejemplo, podemos extraer los num_baths sin haber generado la address !
Solicitar un modelo para generar JSON desde cero consume innecesariamente tokens (y por el tiempo) en la sintaxis predecible, como los nombres de llaves y llaves, que ya se esperan en la salida. Este es un prior fuerte en la generación que deberíamos poder usar para mejorar las latencias.
Los LLM son vergonzosamente paralelos y ejecutar consultas en lotes es mucho más rápido que en un orden en serie. Por lo tanto, podemos dividir el esquema en múltiples consultas. El LLM completará el esquema para cada clave independiente en paralelo y emitirá muchas menos fichas en un solo pase, lo que permite tiempos de inferencia mucho más rápidos.
Ejecute el siguiente comando:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
Hemos tratado de hacer que Super JSON Mode sea muy fácil de usar. Vea la carpeta examples para obtener más ejemplos y uso de vLLM .
Uso de OpenAI y gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Uso de Mistral 7B con Huggingface Transformers:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } Hay muchas características que pueden mejorar el modo SUPER JSON. Aquí hay algunas ideas.
Análisis de salida cualitativa : ejecutamos puntos de referencia de rendimiento, pero deberíamos encontrar un enfoque más riguroso para juzgar los resultados cualitativos del modo super JSON.
Muestreo estructurado : idealmente, debemos enmascarar los logits de la LLM para imponer restricciones de tipo, similar a JSONFormer. Hay algunos paquetes que ya hacen esto, y ya sea que deberían integrar nuestra tubería de generación JSON paralela o deberíamos incorporarlo en modo super JSON.
Soporte del gráfico de dependencia : el modo Super JSON tiene un caso de falla muy obvio: cuando una clave tiene una dependencia de otra clave. Considere una mancha JSON con dos claves, thought y response . Este tipo de salida deseada es común para la cadena de pensamiento con modelos de idiomas grandes, y está muy claro que la response depende del thought . Deberíamos poder transmitir un gráfico de dependencias y indicaciones por lotes de una manera que las salidas de los padres se completen y pasen a los elementos de esquema infantil.
Soporte del modelo local : el modo Super JSON funciona mejor en situaciones locales donde el tamaño de lotes es generalmente 1. Puede explotar el lote para reducir la latencia, similar a la decodificación especulativa. Llama.cpp es el principal marco para modelos locales + inferencia de CPU. Me encantaría implementar esto usando Ollama si es posible.
Soporte de TRT-LLM : VLLM es excelente y fácil de usar, pero idealmente nos integramos con un marco mucho más desempeñado como TRT-LLM.
Agradecemos si desea citar este repositorio si encontró la biblioteca útil para su trabajo:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
Este proyecto fue creado para CS 229: Sistemas para el aprendizaje automático. Muchas gracias al equipo de enseñanza y a TAS por su orientación a lo largo de este proyecto.


