En el círculo de la IA, el ganador del Premio Turing Yann Lecun es un caso atípico típico.
Mientras que muchos expertos técnicos creen firmemente que, siguiendo el camino técnico actual, la realización de AGI es sólo una cuestión de tiempo, Yann Lecun ha planteado objeciones repetidamente.
En acalorados debates con sus pares, dijo más de una vez que el camino tecnológico actual no puede llevarnos a AGI, e incluso el nivel actual de IA no es tan bueno como un gato.
Ganador del premio Turing, científico jefe de IA de Meta, profesor de la Universidad de Nueva York, etc. Estos títulos deslumbrantes y una gran experiencia práctica de primera línea hacen que sea imposible para cualquiera de nosotros ignorar las ideas de este experto en IA.

Entonces, ¿qué piensa Yann LeCun sobre el futuro de la IA? En un discurso público reciente, una vez más explicó su punto de vista: la IA nunca podrá alcanzar una inteligencia cercana al nivel humano basándose únicamente en el entrenamiento mediante texto.
Algunas vistas son las siguientes:
1. En el futuro, las personas generalmente usarán gafas inteligentes u otros tipos de dispositivos inteligentes. Estos dispositivos tendrán sistemas de asistencia integrados para formar equipos virtuales personales inteligentes para mejorar la creatividad y la eficiencia personales.
2. El propósito de los sistemas inteligentes no es reemplazar a los humanos, sino mejorar la inteligencia humana para que puedan trabajar de manera más eficiente.
3. Incluso un gato tiene un modelo en su cerebro que es más complejo que el que cualquier sistema de inteligencia artificial puede construir.
4. Básicamente, FAIR ya no se centra en modelos de lenguaje, sino que avanza hacia el objetivo a largo plazo de los sistemas de inteligencia artificial de próxima generación.
5. Los sistemas de IA no pueden lograr una inteligencia cercana al nivel humano entrenándose únicamente con datos de texto.
6. Yann Lecun sugirió abandonar los modelos generativos, los modelos probabilísticos, el aprendizaje contrastivo y el aprendizaje por refuerzo y, en su lugar, adoptar la arquitectura JEPA y los modelos basados en energía, creyendo que es más probable que estos métodos promuevan el desarrollo de la IA.
7. Si bien las máquinas eventualmente superarán la inteligencia humana, serán controladas porque están impulsadas por objetivos.
Curiosamente, hubo un episodio antes de que comenzara el discurso.
Cuando el presentador presentó a LeCun, lo llamó científico jefe de IA del Instituto de Investigación de IA de Facebook (FAIR) .
En este sentido, LeCun aclaró antes del discurso que la "F" de FAIR ya no representa a Facebook, sino que significa " Fundamental ".
El texto original del discurso a continuación fue compilado por APPSO y ha sido editado. Finalmente se adjunta el enlace del vídeo original: https://www.youtube.com/watch?v=4DsCtgtQlZU
La IA no entiende el mundo tan bien como tu gato
Bien, entonces voy a hablar sobre la IA a nivel humano y cómo vamos a llegar allí y por qué no vamos a llegar allí.
En primer lugar, realmente necesitamos una IA a nivel humano.
Porque en el futuro, una es que la mayoría de nosotros usaremos gafas inteligentes u otro tipo de dispositivos. Hablaremos con estos dispositivos y estos sistemas albergarán asistentes, tal vez más de uno, tal vez un conjunto completo de asistentes.
Esto dará como resultado que cada uno de nosotros tenga esencialmente un equipo virtual inteligente trabajando para nosotros.
Por lo tanto, todos se convertirán en "jefes", pero estos "empleados" no son humanos reales. Necesitamos construir sistemas como este, básicamente para aumentar la inteligencia humana y hacer que las personas sean más creativas y eficientes.

Pero para eso necesitamos máquinas que puedan entender el mundo, recordar cosas, tener intuición y sentido común, y razonar y planificar al mismo nivel que los humanos.
Aunque es posible que hayas escuchado a algunos defensores decir que los sistemas de IA actuales no tienen estas capacidades. Por eso necesitamos tomarnos el tiempo para aprender a modelar el mundo, a tener modelos mentales de cómo funciona el mundo.
Prácticamente todos los animales tienen un modelo así. Tu gato debe tener un modelo más complejo que el que cualquier sistema de inteligencia artificial pueda construir o diseñar.

Necesitamos un sistema que tenga una memoria persistente que los modelos de lenguaje actuales (LLM) no tienen, un sistema que pueda planificar secuencias complejas de acciones que los sistemas actuales no pueden realizar y un sistema que sea controlable y seguro.
Por lo tanto, propondré una arquitectura llamada IA basada en objetivos. Escribí un artículo sobre esta visión hace unos dos años y lo publiqué. Mucha gente en FAIR está trabajando arduamente para hacer realidad este plan.
FAIR ha trabajado en más proyectos de aplicaciones en el pasado, pero Meta creó una división de productos llamada Generative AI (Gen AI) hace un año y medio para centrarse en productos de IA.
Realizan investigación y desarrollo aplicados, por lo que ahora FAIR se ha reorientado hacia el objetivo a largo plazo de los sistemas de inteligencia artificial de próxima generación. Básicamente ya no nos centramos en los modelos lingüísticos.
El éxito de la IA, incluidos los grandes modelos de lenguaje (LLM) , y especialmente el éxito de muchos otros sistemas en los últimos cinco o seis años, se basa en una variedad de técnicas, incluido, por supuesto, el aprendizaje autosupervisado.

El núcleo del aprendizaje autosupervisado es entrenar un sistema no para una tarea específica, sino para intentar representar los datos de entrada de una buena manera. Una forma de lograrlo es mediante la recuperación de daños y reconstrucción.
Así que puedes tomar un fragmento de texto y corromperlo eliminando algunas palabras o cambiando otras. Este proceso se puede utilizar para texto, secuencias de ADN, proteínas o cualquier otra cosa, e incluso, hasta cierto punto, imágenes. Luego entrenas una red neuronal masiva para reconstruir la entrada completa, la versión no corrupta.
Este es un modelo generativo porque intenta reconstruir la señal original.
Entonces, el cuadro rojo es como una función de costos, ¿verdad? Calcula la distancia entre la entrada Y y la salida reconstruida y, y este es el parámetro que se minimizará durante el proceso de aprendizaje. En este proceso, el sistema aprende una representación interna de la entrada, que puede usarse para varias tareas posteriores.
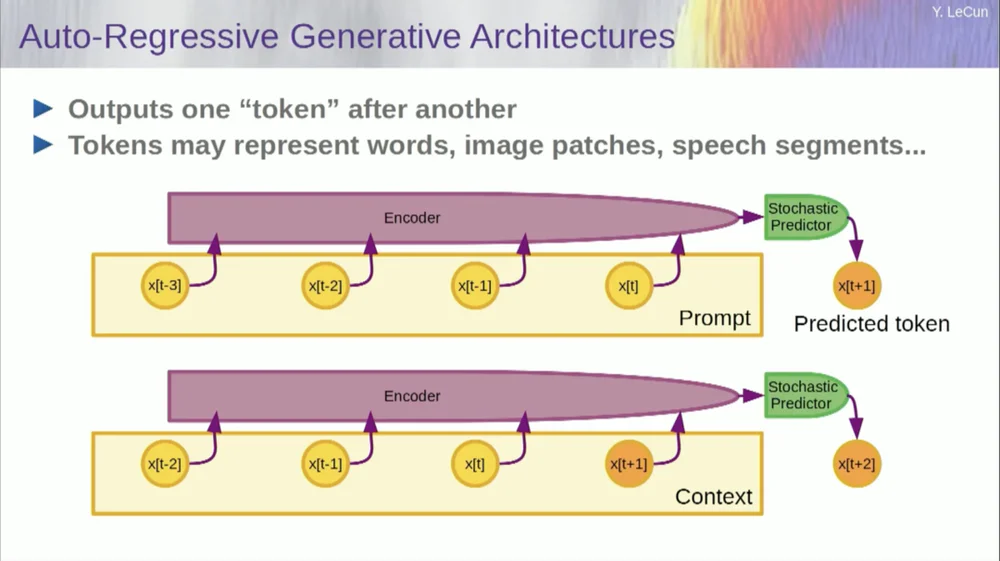
Por supuesto, esto se puede utilizar para predecir palabras en un texto, que es lo que hace la predicción autorregresiva .
Los modelos de lenguaje son un caso especial de esto, donde la arquitectura está diseñada de tal manera que al predecir un elemento, un token o una palabra, solo puede mirar los otros tokens a su izquierda.
No puede mirar hacia el futuro. Si entrena un sistema correctamente, le muestra texto y le pide que prediga la siguiente palabra o el siguiente token en el texto, entonces podrá usar el sistema para predecir la siguiente palabra. Luego agrega la siguiente palabra a la entrada, predice la segunda palabra y la agrega a la entrada, predice la tercera palabra.
Esta es una predicción autorregresiva .
Esto es lo que hacen los LLM, no es un concepto nuevo, ha existido desde la época de Shannon , remontándose a los años 50, que fue hace mucho tiempo, pero el cambio es que ahora tenemos esas arquitecturas de redes neuronales masivas. sobre grandes cantidades de datos y características parecerán surgir de él.
Pero este tipo de predicción autorregresiva tiene algunas limitaciones importantes, y aquí no existe un razonamiento real en el sentido habitual.
Otra limitación más es que esto sólo funciona para datos en forma de objetos discretos, símbolos, tokens, palabras, etc., básicamente cosas que pueden discretizarse.
Todavía nos falta algo importante cuando se trata de alcanzar una inteligencia a nivel humano.
No me refiero necesariamente a la inteligencia a nivel humano, pero incluso tu gato o tu perro pueden lograr algunas hazañas asombrosas que están más allá del alcance de los sistemas de inteligencia artificial actuales.

Cualquier niño de 10 años puede aprender a recoger la mesa y llenar el lavavajillas de una sola vez, ¿verdad? No es necesario practicar ni nada por el estilo, ¿verdad?
Un joven de 17 años necesita unas 20 horas de práctica para aprender a conducir.
Todavía no tenemos coches autónomos de nivel 5 y, desde luego, no tenemos robots domésticos capaces de recoger mesas y llenar lavavajillas.
La IA nunca alcanzará una inteligencia cercana al nivel humano entrenándose únicamente con texto
Así que realmente nos estamos perdiendo algo importante que, de otro modo, podríamos hacer estas cosas con sistemas de inteligencia artificial.
Seguimos encontrándonos con algo llamado la paradoja de Moravec , que es que cosas que nos parecen triviales y que ni siquiera se consideran inteligentes son en realidad muy difíciles de hacer con máquinas, y cosas como la manipulación. El pensamiento abstracto complejo de alto nivel, como el lenguaje, parece ser muy simple para las máquinas, y lo mismo ocurre con cosas como jugar al ajedrez y al Go.
Quizás una de las razones sea ésta.
Un modelo de lenguaje grande (LLM) normalmente se entrena con 20 billones de tokens.
Un token es básicamente tres cuartos de una palabra, en promedio. Por lo tanto, hay 1,5×10^13 palabras en total. Cada token tiene aproximadamente 3B, por lo general, esto requiere 6×1013 bytes.
A cualquiera de nosotros le tomaría unos cientos de miles de años leer esto, ¿verdad? Esto es básicamente todo el texto público en Internet combinado.

Pero pensemos en un niño de cuatro años que ha estado despierto durante un total de 16.000 horas. Tenemos 2 millones de fibras nerviosas ópticas que ingresan a nuestro cerebro. Cada fibra nerviosa transmite datos a aproximadamente 1 B por segundo, tal vez medio byte por segundo. Algunas estimaciones dicen que esto podría ser 3 mil millones por segundo.
No importa, de todos modos es un orden de magnitud.
Esta cantidad de datos es de aproximadamente 10 elevado a 14 bytes de potencia, que es casi el mismo orden de magnitud que LLM. Entonces, en cuatro años, un niño de cuatro años ha visto tantos datos visuales como los modelos de lenguaje más grandes entrenados en texto disponible públicamente en todo Internet.
Usando los datos como punto de partida, esto nos dice varias cosas.
En primer lugar, esto nos dice que nunca alcanzaremos una inteligencia cercana al nivel humano simplemente entrenándonos con texto. Esto simplemente no va a suceder.
En segundo lugar, la información visual es muy redundante. Cada fibra del nervio óptico transmite 1 billón de información por segundo, que ya está comprimida 100 a 1 en comparación con los fotorreceptores de la retina.
Hay aproximadamente entre 60 y 100 millones de fotorreceptores en nuestra retina. Estos fotorreceptores están comprimidos en 1 millón de fibras nerviosas por neuronas en la parte frontal de la retina. Entonces ya hay una compresión de 100 a 1. Luego, cuando llega al cerebro, la información se ha ampliado unas 50 veces.
Entonces lo que estoy midiendo es información comprimida, pero sigue siendo muy redundante. Y la redundancia es en realidad lo que requiere el aprendizaje autosupervisado. El aprendizaje autosupervisado solo aprenderá cosas útiles a partir de datos redundantes. Si los datos están muy comprimidos, lo que significa que se convierten en ruido aleatorio, entonces no se puede aprender nada.
Necesitas redundancia para aprender cualquier cosa. Necesita aprender la estructura subyacente de los datos. Por lo tanto, debemos entrenar el sistema para que aprenda sentido común y física viendo videos o viviendo en el mundo real.
El orden de mis palabras puede resultar un poco confuso. Principalmente quiero decirles qué es esta arquitectura de inteligencia artificial basada en objetivos. Es muy diferente de los LLM o las neuronas de retroalimentación en que el proceso de inferencia no pasa simplemente por una serie de capas de una red neuronal, sino que en realidad ejecuta un algoritmo de optimización.
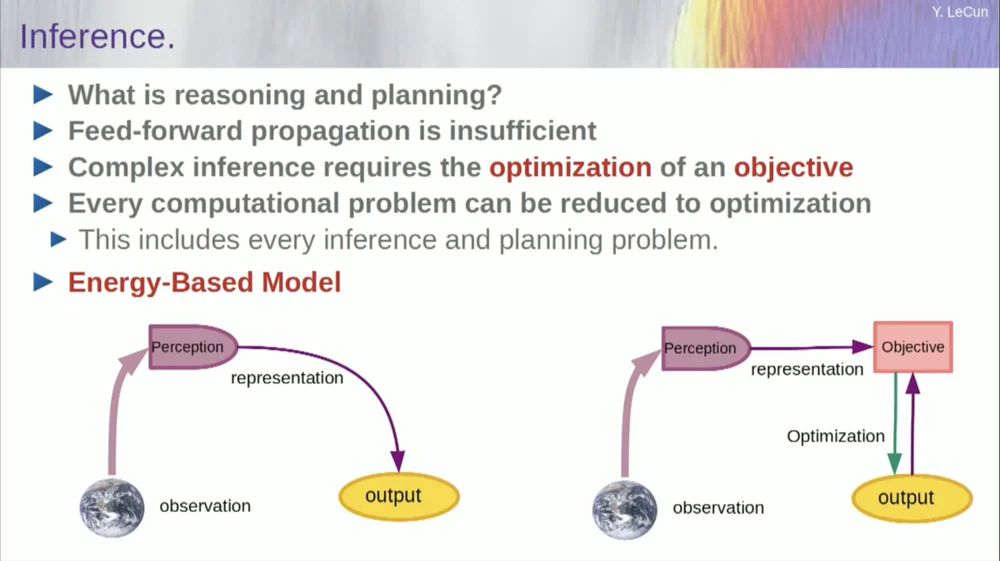
Conceptualmente, se ve así.
Un proceso de avance es aquel en el que las observaciones pasan a través de un sistema de percepción. Por ejemplo, si tiene una serie de capas de red neuronal y produce una salida, entonces para cualquier entrada, solo puede tener una salida, pero en muchos casos, para una percepción, puede haber múltiples interpretaciones de salida posibles. Necesita un proceso de mapeo que no solo calcule la funcionalidad, sino que proporcione múltiples resultados para una sola entrada. La única forma de lograrlo es mediante funciones implícitas.
Básicamente, el cuadro rojo en el lado derecho de este marco de objetivos representa una función que básicamente mide la compatibilidad entre una entrada y su salida propuesta, y luego calcula la salida encontrando el valor de salida que es más compatible con la entrada. Puedes imaginar que este objetivo es algún tipo de función energética y que estás minimizando esta energía con la salida como variable.
Es posible que tenga múltiples soluciones y que tenga alguna forma de manejar esas múltiples soluciones. Esto es cierto para el sistema de percepción humano. Si tienes múltiples interpretaciones de una percepción particular, tu cerebro alternará automáticamente entre esas interpretaciones. Entonces hay alguna evidencia de que este tipo de cosas suceden.
Pero déjenme volver a la arquitectura. Así que aproveche este principio de razonamiento por optimización. Aquí están las suposiciones, por así decirlo, sobre la forma en que funciona la mente humana. Haces observaciones en el mundo. El sistema de percepción te da una idea del estado actual del mundo. Pero claro, sólo te da una idea del estado del mundo que puedes percibir actualmente.
Es posible que recuerde algunas ideas sobre el estado del resto del mundo. Esto puede combinarse con los contenidos de la memoria y alimentarse de un modelo del mundo.
¿Qué es un modelo? Un modelo mundial es un modelo mental de cómo te comportas en el mundo, por lo que puedes imaginar una secuencia de acciones que podrías realizar, y tu modelo mundial te permitirá predecir el impacto de esas secuencias de acciones en el mundo.
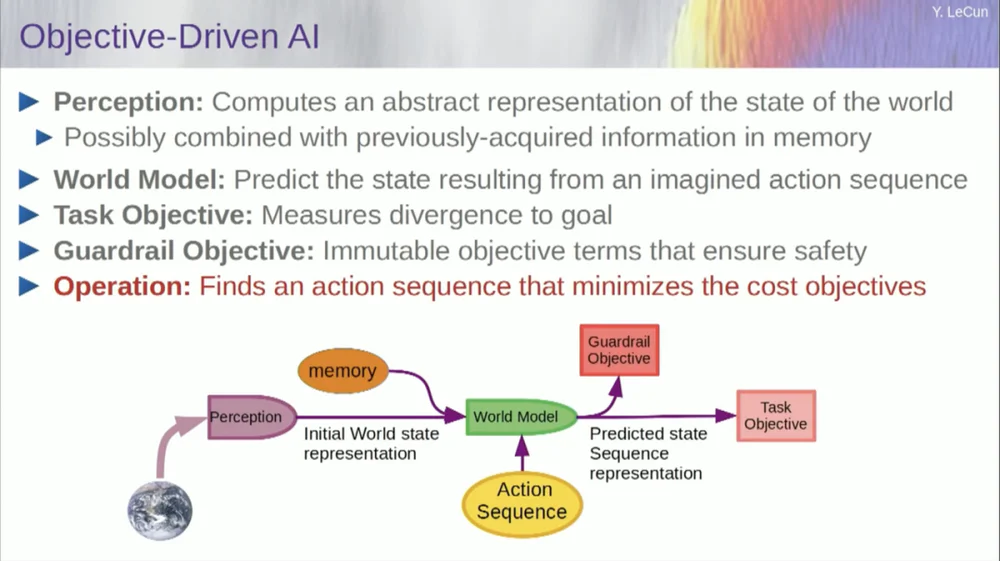
Entonces, el cuadro verde representa el modelo mundial en el que se introduce una secuencia hipotética de acciones que predice cuál será el estado final del mundo, o toda la trayectoria que se predice que sucederá en el mundo.
Combinas eso con un conjunto de funciones objetivas. Un objetivo es medir qué tan bien se logra el objetivo, si se completa la tarea y tal vez un conjunto de otros objetivos que sirvan como márgenes de seguridad, básicamente midiendo hasta qué punto la trayectoria seguida o la acción realizada no representa ningún peligro para el robot. o personas alrededor de la máquina, etc. esperen.
Así que ahora el proceso de razonamiento (aún no he hablado de aprendizaje) es sólo razonamiento y consiste en encontrar secuencias de acciones que minimicen estos objetivos, encontrar secuencias de acciones que minimicen estos objetivos. Este es el proceso de razonamiento.
Así que no es sólo un proceso de avance. Podrías hacerlo buscando opciones discretas, pero eso no es eficiente. Un mejor enfoque es garantizar que todos estos cuadros sean diferenciables; puede propagar el gradiente hacia atrás a través de ellos y luego actualizar la secuencia de acciones mediante el descenso del gradiente.

Ahora bien, esta idea en realidad no es nueva y existe desde hace más de 60 años, tal vez incluso más. Primero, permítanme hablar sobre las ventajas de utilizar un modelo mundial para este tipo de razonamiento. La ventaja es que puedes completar nuevas tareas sin necesidad de aprender.
Hacemos esto de vez en cuando. Cuando nos enfrentamos a una situación nueva, pensamos en ella, imaginamos las consecuencias de nuestras acciones y luego tomamos una secuencia de acciones que lograrán nuestro objetivo (sea cual sea) . No necesitamos aprender a realizar esa tarea. , podemos planificar. Eso es básicamente planificación.
Puede reducir la mayoría de las formas de razonamiento a la optimización. Por lo tanto, el proceso de inferencia mediante optimización es intrínsecamente más poderoso que simplemente ejecutar múltiples capas de una red neuronal. Como dije, esta idea de razonamiento mediante optimización existe desde hace más de 60 años.
En el campo de la teoría del control óptimo, esto se denomina control predictivo de modelos.
Tienes un modelo de un sistema que quieres controlar, como un cohete, un avión o un robot. Puedes imaginarte usando tu modelo mundial para calcular los efectos de una serie de comandos de control.
Luego optimizas esta secuencia para que el movimiento logre los resultados deseados. Toda la planificación del movimiento en la robótica clásica se realiza de esta manera y no es nada nuevo. La novedad aquí es que aprenderemos un modelo del mundo y el sistema perceptivo extraerá una representación abstracta apropiada.
Ahora, antes de entrar en un ejemplo de cómo ejecutar este sistema, puedes construir un sistema de IA general con todos estos componentes: un modelo mundial, una función de costos que se puede configurar para la tarea en cuestión, un módulo de optimización (es decir, verdaderamente optimizando, encontrando el módulo dado que determina la secuencia óptima de acciones para el modelo mundial) , memoria a corto plazo, sistema de percepción, etc.
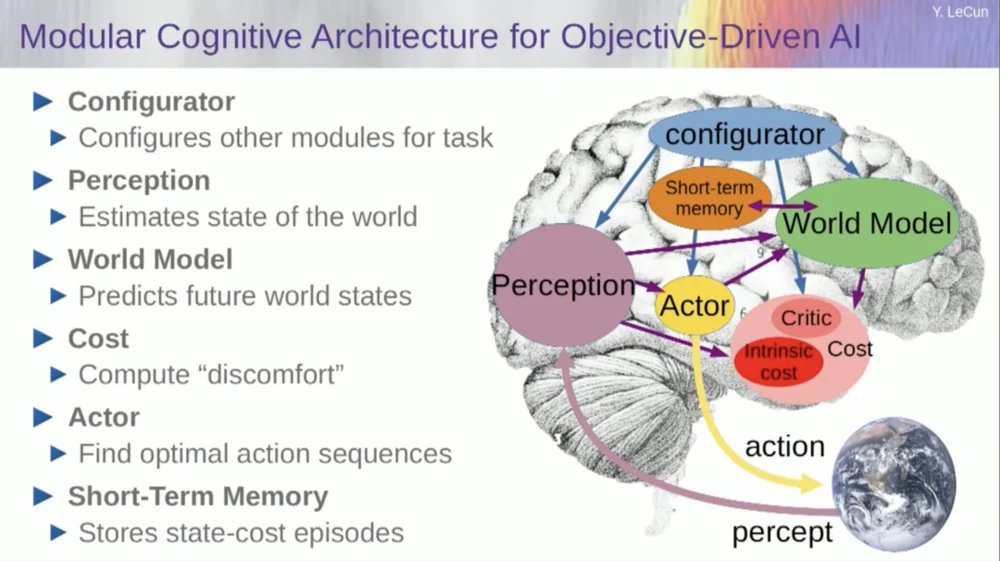
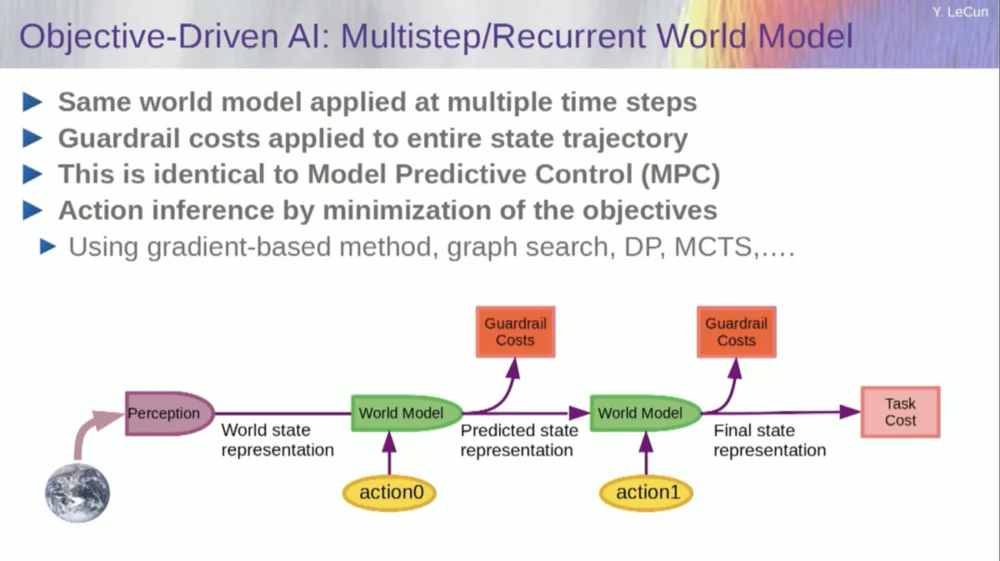
Entonces, ¿cómo funciona esto? Si su acción no es una acción única, sino una secuencia de acciones, y su modelo mundial es en realidad un sistema que le dice, dado el estado mundial en el momento T y las posibles acciones, predecir el estado mundial en el momento T+1.
Quiere predecir qué efecto tendrá una secuencia de dos acciones en esta situación. Puede ejecutar su modelo mundial varias veces para lograr esto.
Obtenga la representación del estado mundial inicial, ingrese la suposición de cero para la acción, use el modelo para predecir el siguiente estado, luego realice la acción uno, calcule el siguiente estado, calcule el costo y luego use métodos de optimización basados en gradientes y retropropagación para Descubra qué minimizará el costo de dos acciones. Este es el control predictivo del modelo.
Ahora bien, el mundo no es completamente determinista, por lo que hay que utilizar variables latentes para ajustarse a su modelo del mundo. Las variables latentes son básicamente variables que pueden intercambiarse dentro de un conjunto de datos o extraerse de una distribución, y representan el cambio de un modelo del mundo entre múltiples predicciones que son compatibles con las observaciones.
Lo que es aún más interesante es que los sistemas inteligentes actualmente no pueden hacer algo que los humanos e incluso los animales pueden hacer, que es la planificación jerárquica.
Por ejemplo, si estuvieras planeando un viaje de Nueva York a París, podrías usar tu comprensión del mundo, tu cuerpo y quizás tu idea de toda la configuración para llegar de aquí a París para planificar todo tu viaje con tu control muscular de bajo nivel.
¿Bien? Si sumas el número de pasos de control muscular por cada diez milisegundos de todas las cosas que tienes que hacer antes de ir a París, es un número enorme. Entonces, lo que se hace es planificar de manera jerárquica, donde se comienza en un nivel muy alto y se dice, está bien, para llegar a París, primero tengo que ir al aeropuerto y tomar un avión.
¿Cómo llego al aeropuerto? Digamos que estoy en la ciudad de Nueva York y tengo que bajar y tomar un taxi. ¿Cómo puedo bajar las escaleras? Tengo que levantarme de la silla, abrir la puerta, caminar hasta el ascensor, apretar el botón, etc. ¿Cómo me levanto de una silla?
En algún momento tendrás que expresar las cosas como acciones de control muscular de bajo nivel, pero no estamos planificando todo en un nivel bajo, sino que estamos haciendo una planificación jerárquica.

Cómo hacer esto utilizando sistemas de inteligencia artificial aún está completamente sin resolver y no tenemos ni idea.
Este parece ser un requisito importante para el comportamiento inteligente.
Entonces, ¿cómo aprendemos modelos mundiales que sean capaces de realizar una planificación jerárquica, capaces de trabajar en diferentes niveles de abstracción? Nadie ha mostrado nada parecido a esto. Este es un gran desafío. La imagen muestra el ejemplo que acabo de mencionar.
Entonces, ¿cómo entrenamos ahora este modelo mundial? Porque este es realmente un gran problema.
Intento averiguar a qué edad los bebés aprenden conceptos básicos sobre el mundo. ¿Cómo aprenden física intuitiva, intuición física y todo eso? Esto sucede mucho antes de que comiencen a aprender cosas como el lenguaje y la interacción.
Por lo tanto, capacidades como el seguimiento facial aparecen muy pronto. El movimiento biológico, la distinción entre objetos animados e inanimados, también aparece temprano. Lo mismo ocurre con la constancia del objeto, que se refiere al hecho de que un objeto persiste cuando es ocluido por otro objeto.
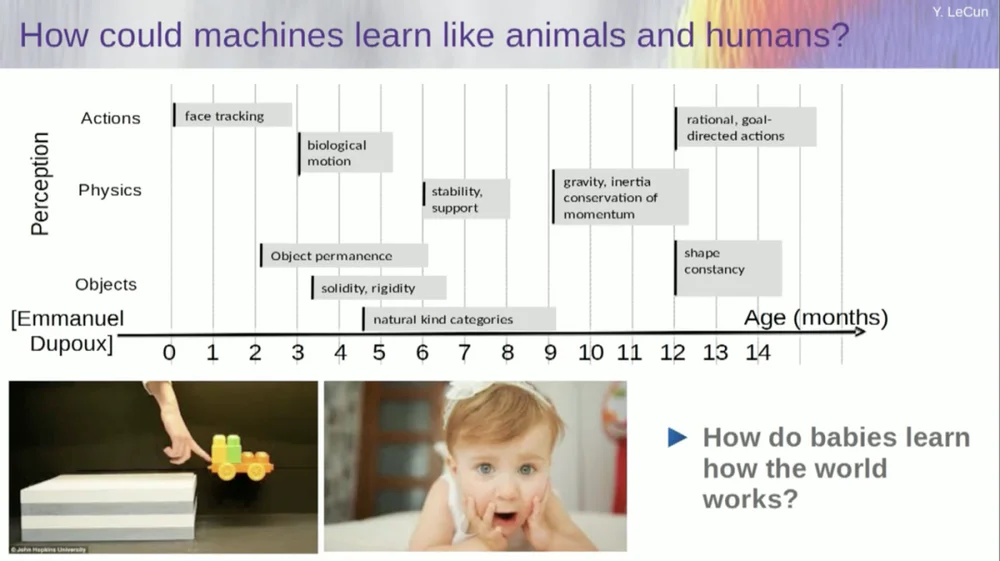
Y los bebés aprenden de forma natural, no es necesario que les pongas nombres a las cosas. Sabrán que las sillas, las mesas y los gatos son diferentes. En cuanto a conceptos como estabilidad y apoyo, como gravedad, inercia, conservación e impulso, en realidad no aparecen hasta los nueve meses de edad aproximadamente.
Esto lleva mucho tiempo. Entonces, si le muestra a un bebé de seis meses el escenario de la izquierda, donde el carrito está sobre una plataforma, y lo empuja fuera de la plataforma, parece flotar en el aire. Un bebé de seis meses lo notará, mientras que un bebé de diez meses sentirá que esto no debería suceder y que el objeto debería caer.
Cuando sucede algo inesperado, significa que tu "modelo del mundo" está equivocado. Así que presta atención porque podría matarte.
Entonces, el tipo de aprendizaje que debe ocurrir aquí es muy similar al tipo de aprendizaje que discutimos anteriormente.
Tome la entrada, corrompela de alguna manera y entrene una gran red neuronal para predecir las partes faltantes. Si entrenas un sistema para predecir lo que sucederá en un video, tal como entrenamos redes neuronales para predecir lo que sucederá en un texto, tal vez esos sistemas puedan aprender sentido común.
Desafortunadamente, llevamos diez años intentándolo y ha sido un completo fracaso. Nunca nos hemos acercado a un sistema que realmente pueda aprender conocimientos generales simplemente tratando de predecir píxeles en un video.
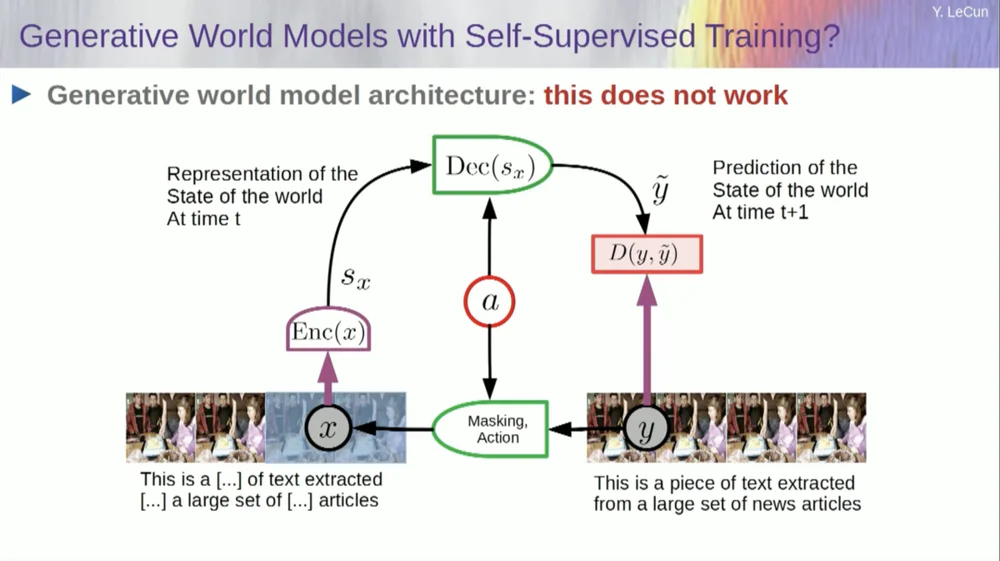
Puedes entrenar un sistema para predecir videos que se vean bien. Hay muchos ejemplos de sistemas de generación de vídeo, pero internamente no son buenos modelos del mundo físico. No podemos hacer esto con ellos.
Bien, entonces la idea de que vamos a utilizar modelos generativos para predecir lo que les sucederá a los individuos y que el sistema comprenderá mágicamente la estructura del mundo es un completo fracaso.
Durante la última década hemos probado muchos enfoques.
Fracasa porque hay muchos futuros posibles. En un espacio discreto como el texto, donde puedes predecir qué palabra seguirá a una cadena de palabras, puedes generar una distribución de probabilidad sobre las palabras posibles en un diccionario. Pero cuando se trata de cuadros de video, no tenemos una buena manera de representar la distribución de probabilidad de los cuadros de video. De hecho, esta tarea es completamente imposible.

Tomé un video de esta habitación, ¿verdad? Tomé la cámara y filmé esa parte y luego detuve el video. Le pregunté al sistema qué pasaría después. Podría predecir las habitaciones restantes. Habrá una pared, habrá gente sentada en ella y la densidad probablemente será similar a la de la izquierda, pero es absolutamente imposible predecir con precisión a nivel de píxeles todos los detalles de cómo se verá cada uno de ustedes. , la textura del mundo y el tamaño exacto de la habitación.
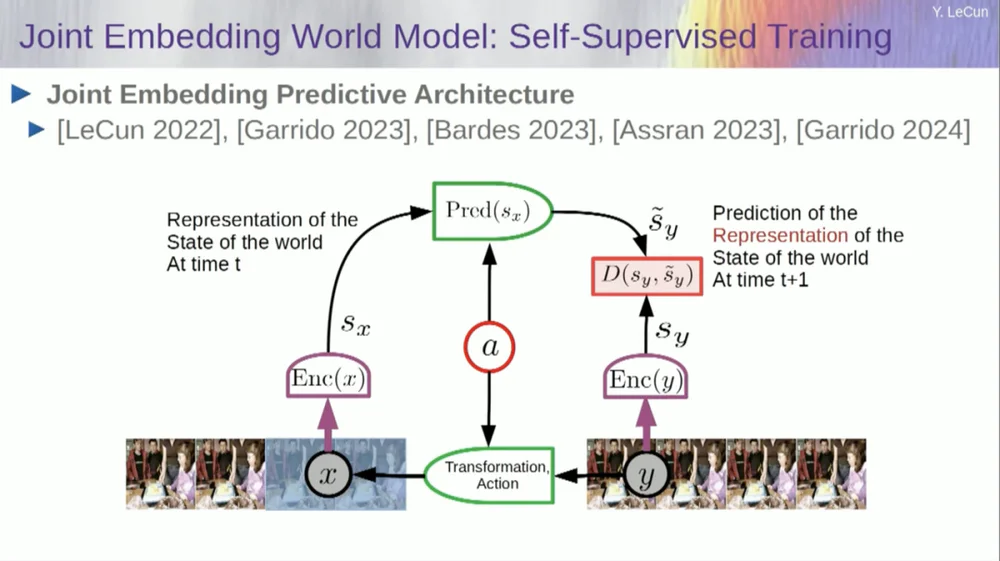
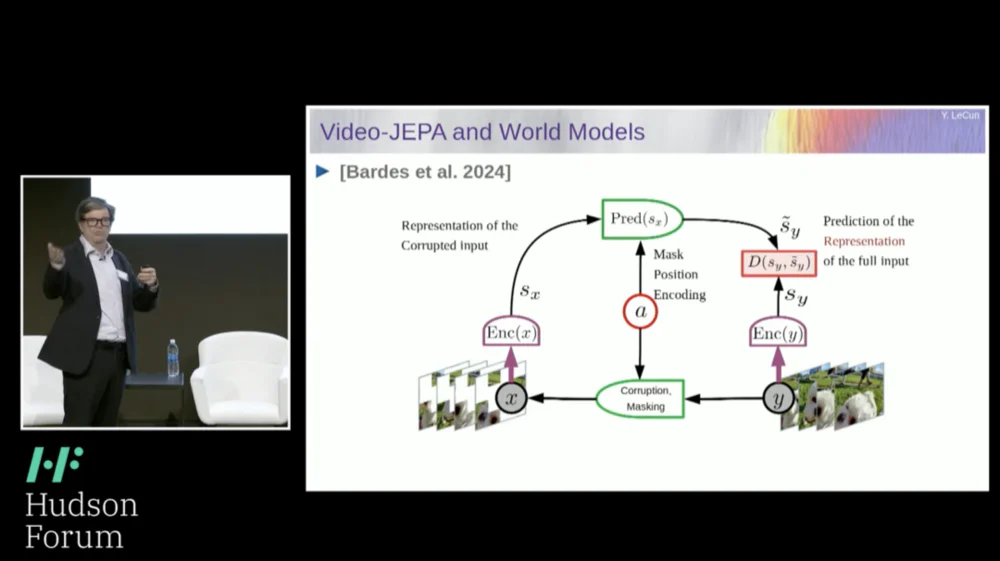
Entonces, mi solución propuesta es la Arquitectura de predicción de incrustación conjunta (JEPA) .
La idea es dejar de predecir píxeles y, en cambio, aprender una representación abstracta de cómo funciona el mundo y luego hacer predicciones dentro de este espacio de representación. Esa es la arquitectura, la arquitectura de predicción de incorporación conjunta. Estas dos incrustaciones toman X (la versión corrupta) e Y respectivamente, son procesadas por el codificador y luego se entrena al sistema para predecir la representación de Y en función de la representación de X.
Ahora el problema es que si entrenas un sistema de este tipo simplemente usando el descenso de gradiente y la retropropagación para minimizar el error de predicción, colapsará. Podría aprender una representación constante de modo que las predicciones se vuelvan muy simples, pero poco informativas.
Entonces, lo que quiero que recuerden es la diferencia entre codificadores automáticos, arquitecturas generativas, codificadores automáticos enmascarados, etc., que intentan reconstruir predicciones, versus arquitecturas de integración conjunta que hacen predicciones en el espacio de representación.
Creo que el futuro está en estas arquitecturas de integración conjunta, y tenemos mucha evidencia empírica de que la mejor manera de aprender buenas representaciones de imágenes es utilizar arquitecturas de edición conjunta.
Todos los intentos de aprender representaciones de imágenes mediante la reconstrucción han sido deficientes y no funcionan bien, y aunque hay muchos proyectos grandes que afirman que funcionan, no lo hacen, y el mejor rendimiento se obtiene con la arquitectura de la derecha.
Ahora bien, si lo pensamos bien, de esto se trata realmente nuestra inteligencia: encontrar una buena representación de un fenómeno para que podamos hacer predicciones, de eso se trata realmente la ciencia.
real. Piénselo, si quiere predecir la trayectoria de un planeta, un planeta es un objeto muy complejo, es enorme, tiene todo tipo de características como clima, temperatura y densidad.
Aunque es un objeto complejo, para predecir la trayectoria de un planeta solo necesitas saber 6 números: 3 coordenadas de posición y 3 vectores de velocidad, listo, no necesitas hacer nada más. Este es un ejemplo muy importante que realmente muestra que la esencia del poder predictivo radica en encontrar una buena representación de las cosas que observamos.

Entonces, ¿cómo entrenamos un sistema así?
Entonces desea evitar que el sistema falle. Una forma de hacer esto es utilizar algún tipo de función de costo que mida el contenido de información de la representación generada por el codificador e intente maximizar el contenido de información y minimizar la información negativa. Su sistema de entrenamiento debe extraer simultáneamente tanta información como sea posible de la entrada y al mismo tiempo minimizar el error de predicción en ese espacio de representación.
El sistema encontrará algún equilibrio entre extraer tanta información como sea posible y no extraer información impredecible. Obtendrá un buen espacio de representación en el que se pueden realizar predicciones.
Ahora bien, ¿cómo se mide la información? Aquí es donde las cosas se ponen un poco raras. Me saltaré esto.
Las máquinas superarán la inteligencia humana y serán seguras y controlables
En realidad, existe una manera de entender esto matemáticamente mediante entrenamiento, modelos basados en energía y funciones energéticas, pero no tengo tiempo para profundizar en ello.
Básicamente, les estoy diciendo algunas cosas diferentes aquí: abandonar los modelos generativos en favor de esas arquitecturas JEPA, abandonar los modelos probabilísticos en favor de esos modelos basados en energía, abandonar los métodos de aprendizaje contrastivo y el aprendizaje por refuerzo. He estado diciendo esto durante 10 años.
Y estos son los cuatro pilares más populares del aprendizaje automático en la actualidad. Probablemente no soy muy popular en este momento.
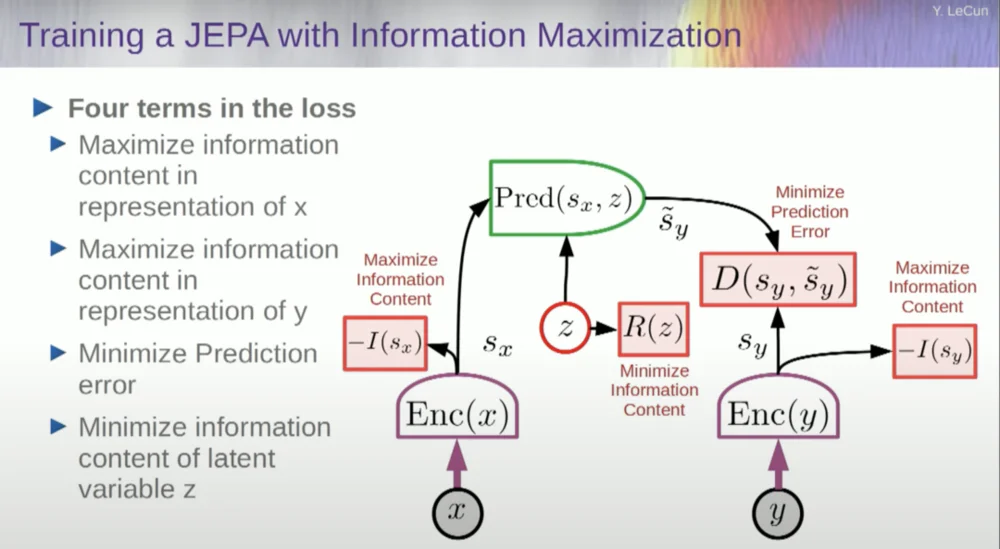
Un enfoque consiste en estimar el contenido de la información, midiendo el contenido de la información procedente del codificador.
Actualmente existen seis formas diferentes de lograrlo. En realidad, hay un método llamado MCR, de mis colegas de la Universidad de Nueva York, que consiste en evitar que el sistema falle y produzca constantes.
Tome las variables del codificador y asegúrese de que tengan una desviación estándar distinta de cero. Podría poner esto en una función de costo y asegurarse de que se busquen los pesos y que las variables no colapsen y se vuelvan constantes. Esto es relativamente simple.
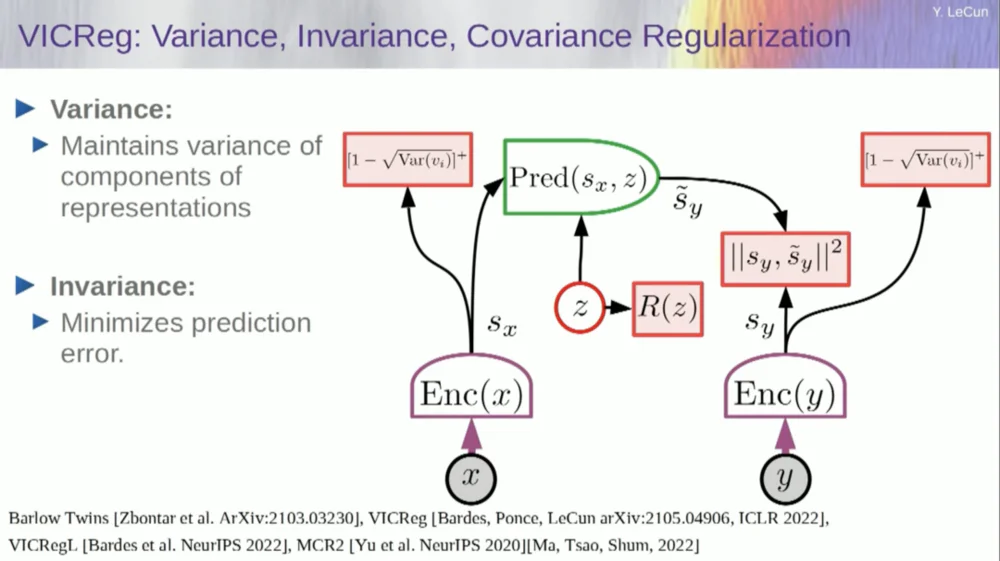
El problema ahora es que el sistema puede "hacer trampa" y hacer que todas las variables sean iguales o estén altamente correlacionadas. Por lo tanto, es necesario agregar otro término, el término fuera de la diagonal necesario para minimizar la matriz de covarianza de estas variables, para garantizar que estén relacionadas.
Por supuesto, esto no es suficiente, ya que las variables pueden seguir siendo dependientes, pero no relacionadas. Por lo tanto, adoptamos otro método para extender las dimensiones de SX a un espacio dimensional superior VX y aplicamos regularización de varianza-covarianza en este espacio para garantizar que se cumplan los requisitos.
Hay otro truco aquí, porque lo que estoy maximizando es el límite superior del contenido de información. Quiero que el contenido de la información real siga mi maximización del límite superior. Lo que necesito es un límite inferior para que empuje el límite inferior y la información aumente. Desafortunadamente, no tenemos información sobre los límites inferiores, o al menos no sabemos cómo calcularlos.
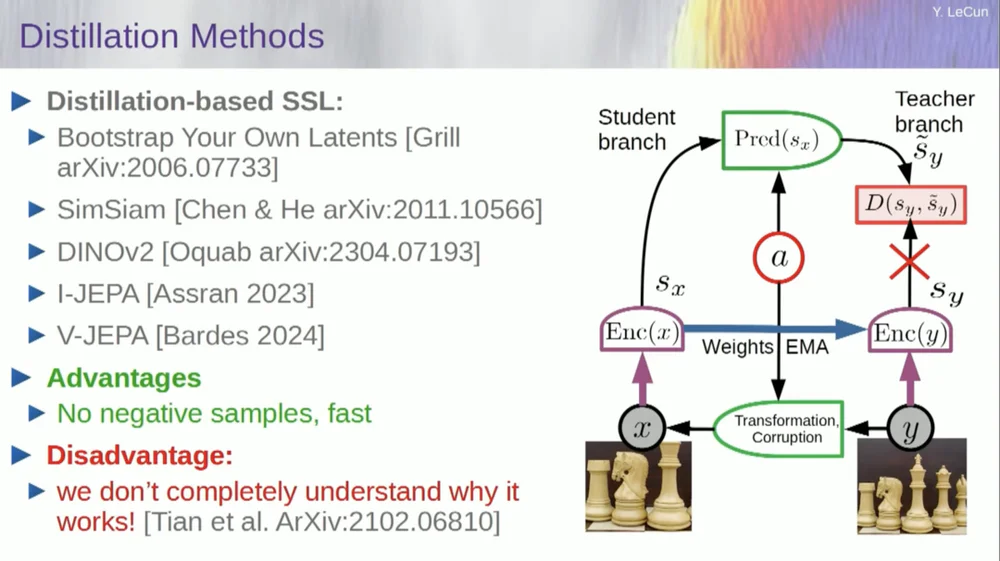
Existe un segundo conjunto de métodos llamado "método del estilo de destilación".
Este método funciona de maneras misteriosas. Si quieres saber exactamente quién está haciendo qué, deberías preguntarle al tipo sentado aquí en el Grill.
Tiene un ensayo personal sobre esto que lo define muy bien. Su idea central es actualizar solo una parte del modelo sin propagar gradientes hacia atrás en la otra parte y compartir los pesos de una manera interesante. También hay muchos artículos sobre este aspecto.
Este enfoque funciona bien si desea entrenar un sistema totalmente autosupervisado para generar buenas representaciones de imágenes. La destrucción de imágenes se realiza mediante enmascaramiento, y algunos trabajos recientes que hemos realizado para videos nos permiten entrenar un sistema para extraer buenas representaciones de video para usar en tareas posteriores, como videos de reconocimiento de acciones, etc. Puede ver que enmascarar una gran parte de un video y hacer predicciones a través de este proceso utiliza este truco de destilación en el espacio de representación para evitar el colapso. Esto funciona muy bien.
Entonces, si tenemos éxito en este proyecto y terminamos con sistemas que puedan razonar, planificar y comprender el mundo físico, así serán todas nuestras interacciones en el futuro.
Se necesitarán años, tal vez incluso una década, para que todo funcione correctamente. Mark Zuckerberg sigue preguntándome cuánto tiempo llevará. Si logramos hacerlo, tendremos sistemas que mediarán en todas nuestras interacciones con el mundo digital. Ellos responderán a todas nuestras preguntas.
Estarán con nosotros durante mucho tiempo y esencialmente formarán un depósito de todo el conocimiento humano. Esto parece una cuestión de infraestructura, como Internet. Esto es menos un producto y más una infraestructura.
Estas plataformas de IA deben ser de código abierto. IBM y Meta participan en un grupo llamado Artificial Intelligence Alliance que promueve plataformas de inteligencia artificial de código abierto. Necesitamos que estas plataformas sean de código abierto porque necesitamos diversidad en estos sistemas de IA.

Necesitamos que comprendan todos los idiomas, todas las culturas, todos los sistemas de valores del mundo, y eso no se conseguirá con un solo sistema producido por una empresa de la costa oeste o la costa este de los Estados Unidos. Estados. Esta debe ser una contribución de todo el mundo.
Por supuesto, formar modelos financieros es muy caro, por lo que sólo unas pocas empresas son capaces de hacerlo. Si empresas como Meta pueden proporcionar el modelo subyacente como código abierto, entonces el mundo podrá ajustarlo para sus propios fines. Ésta es la filosofía adoptada por Meta e IBM.

Así que la IA de código abierto no es sólo una buena idea, sino que es necesaria para la diversidad cultural y quizás incluso para la preservación de la democracia.
La capacitación y el perfeccionamiento se realizarán mediante crowdsourcing o mediante un ecosistema de startups y otras empresas.
Esa es una de las cosas que está impulsando el crecimiento del ecosistema de startups de IA: la disponibilidad de estos modelos de IA de código abierto. ¿Cuánto tiempo llevará llegar a la inteligencia artificial generalizada? No lo sé, podrían pasar años o décadas.

Ha habido muchos cambios a lo largo del camino y todavía quedan muchos problemas por resolver. Es casi seguro que esto será más difícil de lo que pensamos. Esto no sucede en un día, sino que es una evolución gradual e incremental.
Así que no es que un día descubramos el secreto de la inteligencia artificial general, encendamos la máquina y al instante tengamos superinteligencia, y todos seremos aniquilados por la superinteligencia, no, ese no es el caso.
Las máquinas superarán la inteligencia humana, pero estarán bajo control porque están impulsadas por objetivos. Les fijamos objetivos y ellos los cumplen. Como muchos de nosotros aquí somos líderes en la industria o el mundo académico.
Trabajamos con personas más inteligentes que nosotros y ciertamente yo también. El hecho de que haya muchas personas más inteligentes que yo no significa que quieran dominar o hacerse cargo, esa es la verdad del asunto. Por supuesto, hay riesgos detrás de esto, pero lo dejaré para discutirlo más adelante, muchas gracias.