En el campo de la generación y comprensión de imágenes de IA, los modelos existentes a menudo enfrentan el desafío de equilibrar las capacidades de comprensión y generación. Son ineficientes y dependen de una gran cantidad de componentes previamente entrenados. El marco JanusFlow lanzado por DeepSeek AI proporciona una nueva idea para resolver este problema. El editor de Downcodes le brindará una comprensión profunda de cómo JanusFlow logra la unificación de la comprensión y generación de imágenes a través de un diseño arquitectónico innovador y logra resultados notables.
A pesar del rápido progreso en el campo de la generación y comprensión de imágenes impulsadas por la IA, persisten desafíos importantes que obstaculizan el desarrollo de un enfoque unificado y fluido.
Actualmente, los modelos centrados en la comprensión de imágenes tienden a tener un rendimiento deficiente a la hora de generar imágenes de alta calidad, y viceversa. Esta arquitectura de tareas separadas no solo aumenta la complejidad, sino que también limita la eficiencia, lo que hace que sea engorroso manejar tareas que requieren tanto comprensión como generación. Además, muchos modelos existentes dependen demasiado de modificaciones arquitectónicas o componentes previamente entrenados para realizar cualquier función de manera efectiva, lo que genera compensaciones de rendimiento y desafíos de integración.
Para resolver estos problemas, DeepSeek AI lanzó JanusFlow, un potente marco de IA diseñado para unificar la comprensión y generación de imágenes. JanusFlow resuelve las ineficiencias mencionadas anteriormente integrando la comprensión y generación de imágenes en una arquitectura unificada. Este novedoso marco presenta un diseño minimalista que combina modelos de lenguaje autorregresivos con flujo rectificado, un enfoque de modelado generativo de última generación.
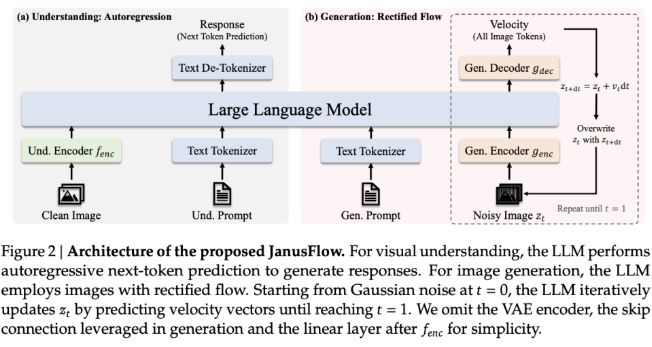
Al eliminar la necesidad de LLM y componentes de generación separados, JanusFlow permite una integración funcional más estrecha al tiempo que reduce la complejidad arquitectónica. Introduce una estructura dual codificador-decodificador, desacopla las tareas de comprensión y generación y garantiza la coherencia del rendimiento en un esquema de entrenamiento unificado mediante la alineación de representaciones.
En términos de detalles técnicos, JanusFlow integra flujo correctivo y modelos de lenguaje grandes de una manera liviana y eficiente. La arquitectura incluye codificadores visuales independientes para tareas de comprensión y generación. Durante el entrenamiento, estos codificadores se alinean entre sí para mejorar la coherencia semántica, lo que permite que el sistema funcione bien en las tareas de generación de imágenes y comprensión visual.
Este desacoplamiento de codificadores evita la interferencia entre tareas, mejorando así las capacidades de cada módulo. El modelo también emplea guía sin clasificador (CFG) para controlar la alineación entre las imágenes generadas y las condiciones textuales, mejorando así la calidad de la imagen. En comparación con los sistemas unificados tradicionales que utilizan modelos de difusión como herramientas externas, JanusFlow proporciona un proceso de generación más simple y directo con menos limitaciones. La eficacia de esta arquitectura queda demostrada por su capacidad para igualar o superar el rendimiento de muchos modelos de tareas específicas en múltiples puntos de referencia.
La importancia de JanusFlow radica en su eficiencia y versatilidad, llenando un vacío crítico en el desarrollo de modelos multimodales. Al eliminar la necesidad de módulos independientes de generación y comprensión, JanusFlow permite a los investigadores y desarrolladores aprovechar un marco único para múltiples tareas, lo que reduce significativamente la complejidad y el uso de recursos.
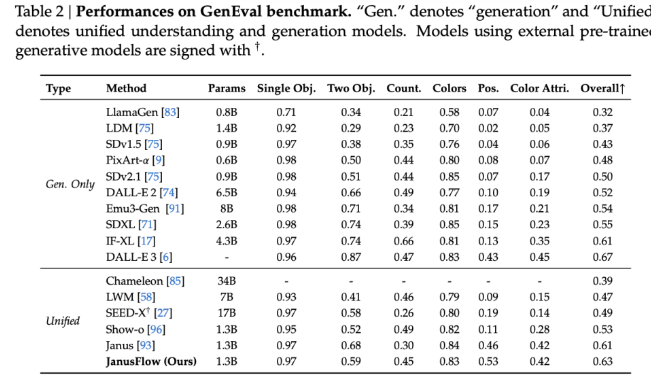
Los resultados de las pruebas comparativas muestran que JanusFlow supera a muchos modelos unificados existentes con puntuaciones de 74,9, 70,5 y 60,3 en MMBench, SeedBench y GQA respectivamente. En términos de generación de imágenes, JanusFlow superó a SDv1.5 y SDXL, con una puntuación de 9,51 para MJHQ FID-30k y una puntuación de 0,63 para GenEval. Estas métricas demuestran su excelente capacidad para generar imágenes de alta calidad y manejar tareas multimodales complejas con solo 1,3 mil millones de parámetros.
En conclusión, JanusFlow ha dado un paso importante hacia el desarrollo de un modelo de IA unificado capaz de comprender y generar imágenes simultáneamente. Su enfoque minimalista, centrado en integrar capacidades autorregresivas con flujos correctivos, no solo mejora el rendimiento sino que también simplifica la arquitectura del modelo, haciéndola más eficiente y accesible.
Al desacoplar el codificador visual y alinear las representaciones durante el entrenamiento, JanusFlow une con éxito la comprensión y la generación de imágenes. A medida que la investigación de la IA continúa superando los límites de las capacidades del modelo, JanusFlow representa un hito importante hacia la creación de sistemas de IA multimodales más versátiles y versátiles.
Modelo: https://huggingface.co/deepseek-ai/JanusFlow-1.3B
Documento: https://arxiv.org/abs/2411.07975
Con todo, JanusFlow ha demostrado un gran potencial en el campo de la IA multimodal con su arquitectura eficiente y excelente rendimiento, lo que señala una nueva dirección para el desarrollo de futuros modelos de IA. ¡Esperamos que JanusFlow desempeñe un papel en más escenarios de aplicaciones!