Con el rápido desarrollo de la tecnología de inteligencia artificial, la demanda de modelos de lenguaje visual crece día a día, pero sus altos requisitos de recursos informáticos limitan su aplicación en dispositivos comunes. El editor de Downcodes le presentará hoy un modelo de lenguaje visual liviano llamado SmolVLM, que puede ejecutarse de manera eficiente en dispositivos con recursos limitados, como computadoras portátiles y GPU de consumo. La aparición de SmolVLM ha brindado a más usuarios la oportunidad de experimentar tecnología de inteligencia artificial avanzada, ha reducido el umbral de uso y también ha brindado a los desarrolladores herramientas de investigación más convenientes.
En los últimos años, ha habido una demanda creciente de la aplicación de modelos de aprendizaje automático en tareas de visión y lenguaje, pero la mayoría de los modelos requieren enormes recursos informáticos y no pueden ejecutarse de manera eficiente en dispositivos personales. Los dispositivos especialmente pequeños, como ordenadores portátiles, GPU de consumo y dispositivos móviles, se enfrentan a enormes desafíos a la hora de procesar tareas de lenguaje visual.
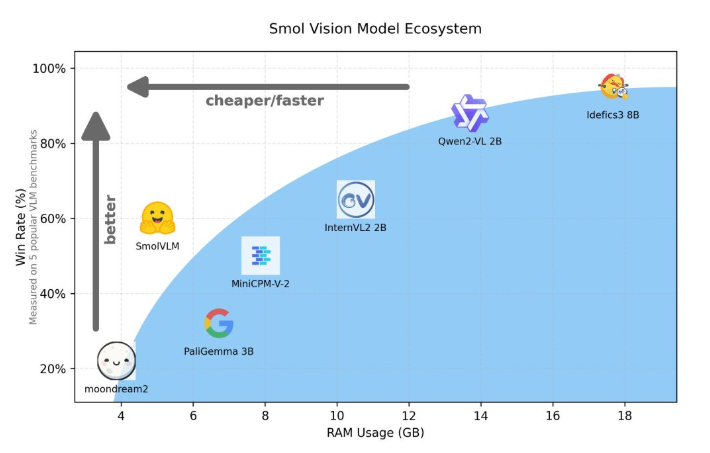
Tomando como ejemplo Qwen2-VL, aunque tiene un rendimiento excelente, tiene altos requisitos de hardware, lo que limita su usabilidad en aplicaciones en tiempo real. Por lo tanto, desarrollar modelos livianos para funcionar con menores recursos se ha convertido en una necesidad importante.
Hugging Face lanzó recientemente SmolVLM, un modelo de lenguaje visual de parámetros 2B especialmente diseñado para el razonamiento del lado del dispositivo. SmolVLM supera a otros modelos similares en términos de uso de memoria de GPU y velocidad de generación de tokens. Su característica principal es la capacidad de ejecutarse de manera eficiente en dispositivos más pequeños, como computadoras portátiles o GPU de consumo, sin sacrificar el rendimiento. SmolVLM encuentra un equilibrio ideal entre rendimiento y eficiencia, resolviendo problemas que eran difíciles de superar en modelos similares anteriores.
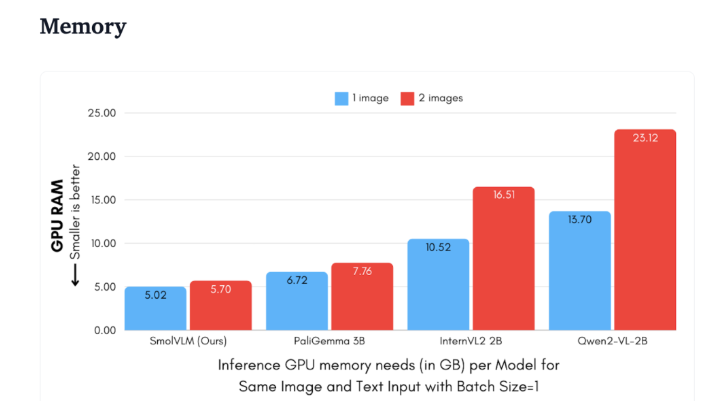
En comparación con Qwen2-VL2B, SmolVLM genera tokens entre 7,5 y 16 veces más rápido, gracias a su arquitectura optimizada, que hace posible una inferencia ligera. Esta eficiencia no sólo aporta beneficios prácticos a los usuarios finales, sino que también mejora enormemente la experiencia del usuario.
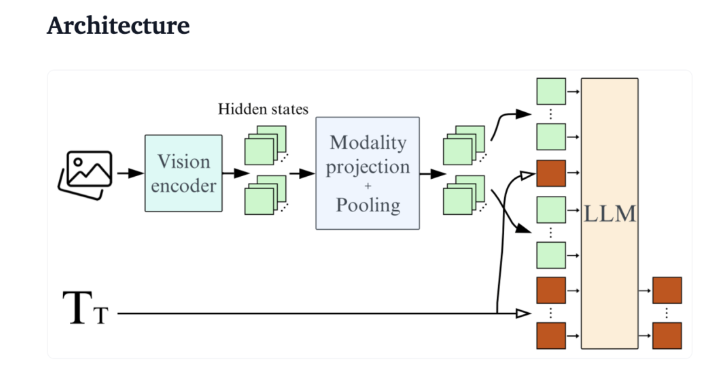
Desde una perspectiva técnica, SmolVLM tiene una arquitectura optimizada que admite una inferencia eficiente del lado del dispositivo. Los usuarios pueden incluso realizar ajustes fácilmente en Google Colab, lo que reduce considerablemente el umbral de experimentación y desarrollo.
Debido a su pequeña huella de memoria, SmolVLM puede funcionar sin problemas en dispositivos que antes no podían albergar modelos similares. Al probar un vídeo de YouTube de 50 fotogramas, SmolVLM obtuvo un buen rendimiento, con una puntuación del 27,14 %, y superó a los dos modelos que consumen más recursos en términos de consumo de recursos, lo que demuestra su gran adaptabilidad y flexibilidad.
SmolVLM es un hito importante en el campo de los modelos de lenguaje visual. Su lanzamiento permite ejecutar tareas complejas de lenguaje visual en dispositivos cotidianos, llenando un vacío importante en las herramientas de inteligencia artificial actuales.
SmolVLM no sólo destaca por su velocidad y eficiencia, sino que también proporciona a los desarrolladores e investigadores una potente herramienta para facilitar el procesamiento del lenguaje visual sin costosos gastos de hardware. A medida que la tecnología de IA siga volviéndose más popular, modelos como SmolVLM harán que las poderosas capacidades de aprendizaje automático sean más accesibles.
demostración: https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
Con todo, SmolVLM ha establecido un nuevo punto de referencia para los modelos de lenguaje visual livianos. Su rendimiento eficiente y su uso conveniente promoverán en gran medida la popularización y el desarrollo de la tecnología de inteligencia artificial. Esperamos más innovaciones similares en el futuro, que permitan que la tecnología de IA beneficie a más personas.