En los últimos años, el coste de formación de modelos lingüísticos a gran escala sigue siendo elevado, lo que se ha convertido en un factor importante que restringe el desarrollo de la IA. Cómo reducir los costos de capacitación y mejorar la eficiencia se ha convertido en el foco de la industria. El editor de Downcodes le ofrece una interpretación del último artículo de investigadores de la Universidad de Harvard y la Universidad de Stanford. Este artículo propone una regla de escala "consciente de la precisión" que reduce efectivamente los costos de capacitación al ajustar la precisión del entrenamiento del modelo, incluso en algunos casos. En este caso, también puede mejorar el rendimiento del modelo. Echemos un vistazo más de cerca a esta apasionante investigación.
En el campo de la inteligencia artificial, una mayor escala parece significar mayores capacidades. En la búsqueda de modelos de lenguaje más potentes, las principales empresas de tecnología están acumulando frenéticamente parámetros de modelos y datos de entrenamiento, sólo para descubrir que los costos también están aumentando. ¿No existe una forma rentable y eficiente de entrenar modelos lingüísticos?
Investigadores de las universidades de Harvard y Stanford publicaron recientemente un artículo en el que descubrieron que la precisión del entrenamiento modelo es como una clave oculta que puede desbloquear el "código de costo" del entrenamiento modelo lingüístico.
¿Qué es la precisión del modelo? En pocas palabras, se refiere a los parámetros del modelo y la cantidad de dígitos utilizados en el proceso de cálculo. Los modelos tradicionales de aprendizaje profundo suelen utilizar números de coma flotante de 32 bits (FP32) para el entrenamiento, pero en los últimos años, con el desarrollo del hardware, se utilizan tipos de números de menor precisión, como números de coma flotante de 16 bits (FP16) o números de coma flotante de 8 bits. bits enteros (INT8) El entrenamiento ya es posible.
Entonces, ¿qué impacto tendrá la reducción de la precisión del modelo en el rendimiento del modelo? Ésta es exactamente la pregunta que este artículo quiere explorar. A través de una gran cantidad de experimentos, los investigadores analizaron los cambios de costo y rendimiento del entrenamiento y la inferencia de modelos con diferente precisión y propusieron un nuevo conjunto de reglas de escala "conscientes de la precisión".
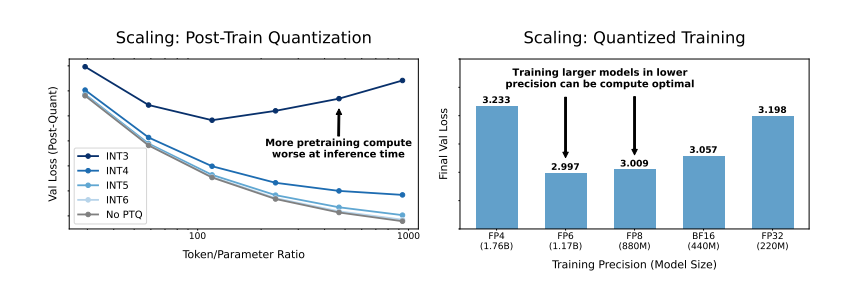
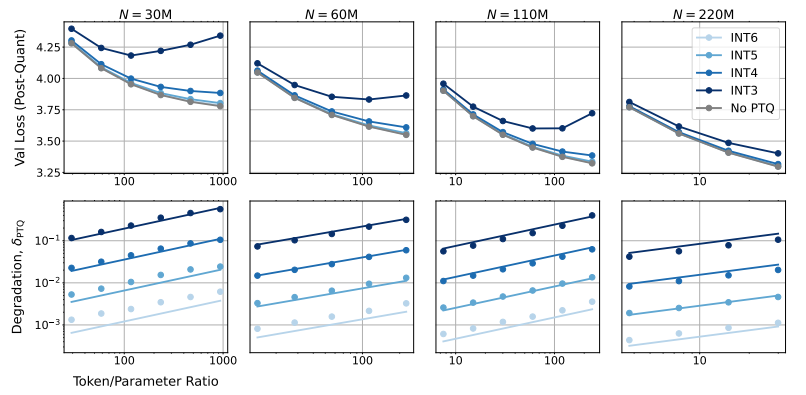
Descubrieron que entrenar con menor precisión reduce efectivamente el "número efectivo de parámetros" del modelo, reduciendo así la cantidad de cálculo requerido para el entrenamiento. Esto significa que, con el mismo presupuesto computacional, podemos entrenar modelos a mayor escala, o a la misma escala, usar una precisión menor puede ahorrar muchos recursos computacionales.
Aún más sorprendente es que los investigadores también descubrieron que, en algunos casos, entrenar con menor precisión puede mejorar el rendimiento del modelo. Por ejemplo, para aquellos que requieren "cuantización posterior al entrenamiento". Si el modelo utiliza una menor precisión durante la etapa de entrenamiento, el modelo será más robusto a la reducción de la precisión después de la cuantificación, mostrando así un mejor rendimiento durante la etapa de inferencia.
Entonces, ¿qué precisión deberíamos elegir para entrenar el modelo? Al analizar sus reglas de escala, los investigadores llegaron a algunas conclusiones interesantes:
El entrenamiento de precisión tradicional de 16 bits puede no ser óptimo. Su investigación sugiere que una precisión de 7 a 8 dígitos puede ser una opción más rentable.
Tampoco es aconsejable seguir ciegamente un entrenamiento de precisión ultrabaja (como 4 dígitos). Porque con una precisión extremadamente baja, la cantidad de parámetros efectivos del modelo disminuirá drásticamente. Para mantener el rendimiento, necesitamos aumentar significativamente el tamaño del modelo, lo que a su vez conducirá a mayores costos computacionales.
La precisión óptima del entrenamiento puede variar para modelos de diferentes tamaños. Para aquellos modelos que requieren mucho "sobreentrenamiento", como las series Llama-3 y Gemma-2, entrenar con mayor precisión puede resultar más rentable.
Esta investigación proporciona una nueva perspectiva sobre la comprensión y optimización de la formación en modelos lingüísticos. Nos dice que la elección de la precisión no es estática, sino que debe sopesarse en función del tamaño del modelo específico, el volumen de datos de entrenamiento y los escenarios de aplicación.
Por supuesto, existen algunas limitaciones para este estudio. Por ejemplo, el modelo que utilizaron es de escala relativamente pequeña y es posible que los resultados experimentales no sean directamente generalizables a modelos de mayor escala. Además, solo se centraron en la función de pérdida del modelo y no evaluaron el desempeño del modelo en tareas posteriores.
No obstante, esta investigación todavía tiene implicaciones importantes. Revela la compleja relación entre la precisión del modelo, el rendimiento del modelo y el costo de capacitación, y nos proporciona información valiosa para diseñar y entrenar modelos de lenguaje más potentes y económicos en el futuro.
Documento: https://arxiv.org/pdf/2411.04330
En definitiva, esta investigación proporciona nuevas ideas y métodos para reducir el costo del entrenamiento de modelos de lenguaje a gran escala y proporciona un valor de referencia importante para el futuro desarrollo de la IA. El editor de Downcodes espera seguir avanzando en la investigación de la precisión de los modelos y contribuir a la construcción de modelos de IA más rentables.