Informes del editor de Downcodes: En los últimos años, la tecnología de animación de imágenes basada en audio se ha desarrollado rápidamente, pero los modelos existentes todavía tienen cuellos de botella en términos de eficiencia y duración. Para resolver este problema, los investigadores han desarrollado una nueva tecnología llamada JoyVASA, que mejora significativamente la calidad y eficiencia de la animación de imágenes basada en audio a través de un ingenioso diseño de dos etapas. JoyVASA no sólo es capaz de generar vídeos animados más largos, sino que también admite animaciones faciales de animales y muestra una buena compatibilidad en varios idiomas, lo que aporta nuevas posibilidades al campo de la producción de animación.
Recientemente, los investigadores propusieron una nueva tecnología llamada JoyVASA, cuyo objetivo es mejorar los efectos de animación de imágenes basados en audio. Con el desarrollo continuo de modelos de difusión y aprendizaje profundo, la animación de retratos basada en audio ha logrado avances significativos en la calidad del video y la precisión de la sincronización de labios. Sin embargo, la complejidad de los modelos existentes aumenta la eficiencia del entrenamiento y la inferencia, al tiempo que limita la duración y la continuidad entre fotogramas de los vídeos.
JoyVASA adopta un diseño de dos etapas. La primera etapa introduce un marco de representación facial desacoplada para separar las expresiones faciales dinámicas de las representaciones faciales estáticas tridimensionales.
Esta separación permite al sistema combinar cualquier modelo facial 3D estático con secuencias de acción dinámicas para generar videos animados más largos. En la segunda fase, el equipo de investigación entrenó un transformador de difusión que puede generar secuencias de acción directamente a partir de señales de audio, un proceso independiente de la identidad del personaje. Finalmente, el generador basado en el entrenamiento de la primera etapa toma la representación facial 3D y la secuencia de acción generada como entrada para generar efectos de animación de alta calidad.
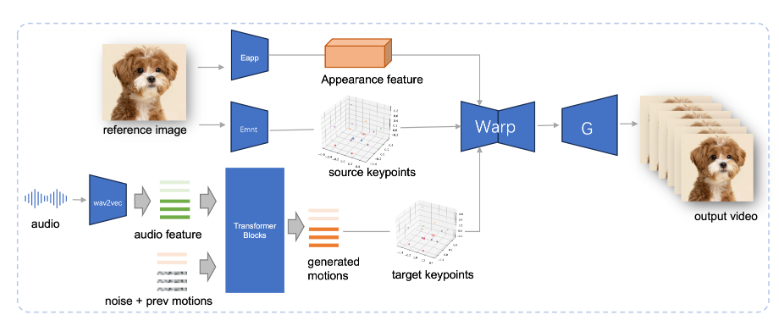
En particular, JoyVASA no se limita a la animación de retratos humanos, sino que también puede animar rostros de animales sin problemas. Este modelo está entrenado en un conjunto de datos mixtos, que combina datos privados en chino y datos públicos en inglés, lo que muestra buenas capacidades de soporte en varios idiomas. Los resultados experimentales demuestran la eficacia de este método. Las investigaciones futuras se centrarán en mejorar el rendimiento en tiempo real y perfeccionar el control de la expresión para ampliar aún más la aplicación de este marco en la animación de imágenes.
La aparición de JoyVASA marca un avance importante en la tecnología de animación basada en audio, promoviendo nuevas posibilidades en el campo de la animación.
Entrada del proyecto: https://jdh-algo.github.io/JoyVASA/
La innovación de la tecnología JoyVASA radica en su eficiente diseño de dos etapas y sus potentes capacidades de soporte en varios idiomas, lo que proporciona una solución más conveniente y eficiente para la producción de animación. En el futuro, con la mejora de la tecnología, se espera que JoyVASA se utilice ampliamente en más campos, brindándonos trabajos de animación más realistas y emocionantes. ¡Esperamos más avances tecnológicos y lideramos un nuevo capítulo en el desarrollo de la industria de la animación!