El equipo de investigación de IA de Apple lanzó una nueva generación de la familia de modelos de lenguaje grande multimodal MM1.5, que puede integrar múltiples tipos de datos, como texto e imágenes, y ha demostrado un rendimiento poderoso en tareas como respuesta visual a preguntas, generación de imágenes y multi- capacidad de interpretación de datos modales. MM1.5 supera las dificultades de los modelos multimodales anteriores en el procesamiento de imágenes ricas en texto y tareas visuales detalladas. A través de un enfoque innovador centrado en datos, utiliza datos OCR de alta resolución y descripciones de imágenes sintéticas para mejorar significativamente el rendimiento del modelo. . Comprensión. El editor de Downcodes le brindará una comprensión profunda de las innovaciones de MM1.5 y su excelente rendimiento en múltiples pruebas comparativas.
Recientemente, el equipo de investigación de IA de Apple lanzó su nueva generación de familia de modelos de lenguaje grande multimodal (MLLM): MM1.5. Esta serie de modelos puede combinar múltiples tipos de datos, como texto e imágenes, lo que nos muestra la nueva capacidad de la IA para comprender tareas complejas. Tareas como la respuesta visual a preguntas, la generación de imágenes y la interpretación de datos multimodales se pueden resolver mejor con la ayuda de estos modelos.
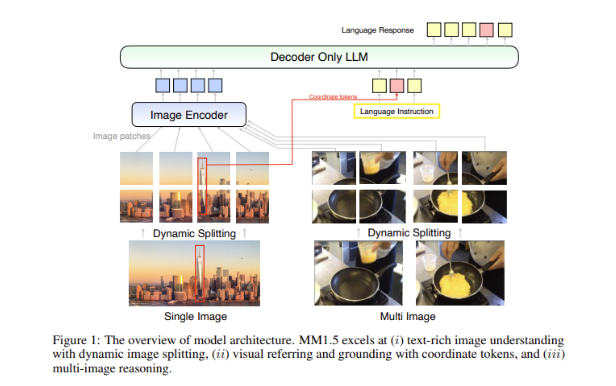
Un gran desafío en los modelos multimodales es cómo lograr una interacción efectiva entre diferentes tipos de datos. Los modelos anteriores a menudo tenían problemas con imágenes ricas en texto o tareas de visión detalladas. Por lo tanto, el equipo de investigación de Apple introdujo un método innovador centrado en datos en el modelo MM1.5, utilizando datos OCR de alta resolución y descripciones de imágenes sintéticas para fortalecer las capacidades de comprensión del modelo.
Este método no solo permite que MM1.5 supere a los modelos anteriores en comprensión visual y tareas de posicionamiento, sino que también lanza dos versiones especializadas del modelo: MM1.5-Video y MM1.5-UI, que se utilizan para comprensión y posicionamiento de video respectivamente. Análisis de interfaz móvil.
El entrenamiento del modelo MM1.5 se divide en tres etapas principales.
La primera etapa es un entrenamiento previo a gran escala, que utiliza 2 mil millones de pares de datos de imagen y texto, 600 millones de documentos de imagen y texto entrelazados y 2 billones de tokens de solo texto.
La segunda etapa consiste en mejorar aún más el rendimiento de las tareas de imágenes enriquecidas con texto mediante un entrenamiento previo continuo de 45 millones de datos OCR de alta calidad y 7 millones de descripciones sintéticas.
Finalmente, en la etapa de ajuste fino supervisado, el modelo se optimiza utilizando datos de una sola imagen, varias imágenes y solo texto cuidadosamente seleccionados para mejorar la referencia visual detallada y el razonamiento de varias imágenes.
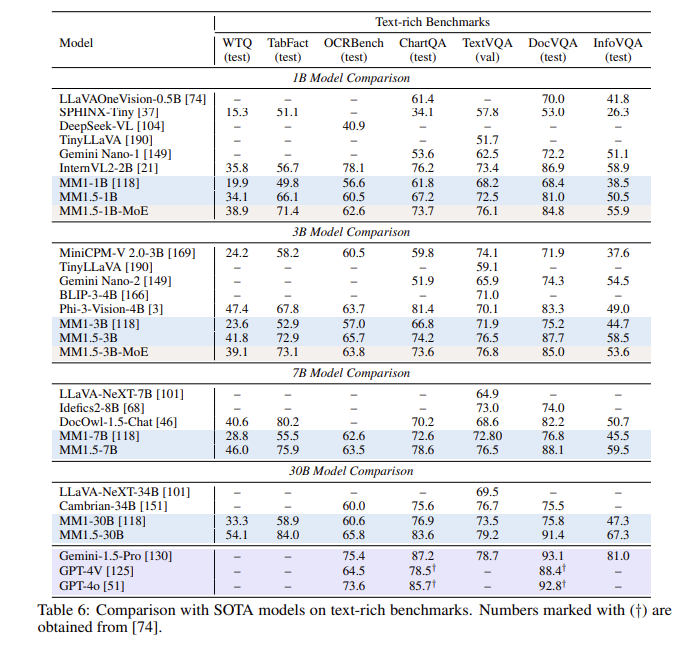
Después de una serie de evaluaciones, el modelo MM1.5 tuvo un buen desempeño en múltiples pruebas comparativas, especialmente cuando se trata de comprensión de imágenes ricas en texto, con una mejora de 1,4 puntos con respecto al modelo anterior. Además, incluso MM1.5-Video, que está diseñado específicamente para la comprensión de videos, ha alcanzado el nivel líder en tareas relacionadas con sus poderosas capacidades multimodales.
La familia de modelos MM1.5 no solo establece un nuevo punto de referencia para los modelos de lenguajes grandes multimodales, sino que también demuestra su potencial en una variedad de aplicaciones, desde la comprensión general del texto de imágenes hasta el análisis de videos y de interfaces de usuario, todo con un rendimiento sobresaliente.
Destacar:
**Variantes de modelo**: Incluye modelos densos y modelos MoE con parámetros de mil millones a 30 mil millones, lo que garantiza escalabilidad y implementación flexible.
? **Datos de entrenamiento**: Utilizando 2 mil millones de pares de imagen y texto, 600 millones de documentos de imagen y texto entrelazados y 2 billones de tokens de solo texto.
**Mejora del rendimiento**: en una prueba comparativa centrada en la comprensión de imágenes con texto enriquecido, se logró una mejora de 1,4 puntos en comparación con el modelo anterior.
Con todo, la familia de modelos MM1.5 de Apple ha logrado avances significativos en el campo de los modelos de lenguajes grandes multimodales, y sus métodos innovadores y excelente rendimiento brindan una nueva dirección para el futuro desarrollo de la IA. Esperamos que MM1.5 muestre su potencial en más escenarios de aplicación.