En los últimos años, el modelo Transformer y su mecanismo de atención han logrado avances significativos en el campo de los modelos de lenguaje grande (LLM), pero siempre ha existido el problema de ser susceptible a interferencias de información irrelevante. El editor de Downcodes le interpretará un artículo más reciente, que propone un nuevo modelo llamado Transformador diferencial (Transformador DIFF), que tiene como objetivo resolver el problema del ruido de atención en el modelo Transformador y mejorar la eficiencia y precisión del modelo. El modelo filtra eficazmente información irrelevante a través de un innovador mecanismo de atención diferencial, lo que permite que el modelo se centre más en información clave, logrando así mejoras significativas en múltiples aspectos, incluido el modelado del lenguaje, el procesamiento de textos largos, la recuperación de información clave y la reducción de la ilusión del modelo, etc. .
Los modelos de lenguaje grande (LLM) se han desarrollado rápidamente recientemente, en los que el modelo Transformer juega un papel importante. El núcleo de Transformer es el mecanismo de atención, que actúa como un filtro de información y permite que el modelo se centre en las partes más importantes de la oración. Pero incluso un transformador poderoso se verá interferido por información irrelevante, al igual que usted está tratando de encontrar un libro en la biblioteca, pero está abrumado por una pila de libros irrelevantes y la eficiencia es naturalmente baja.
La información irrelevante generada por este mecanismo de atención se denomina ruido de atención en el artículo. Imagine que desea encontrar una información clave en un archivo, pero la atención del modelo Transformer está dispersa en varios lugares irrelevantes, como una persona miope que no puede ver los puntos clave.
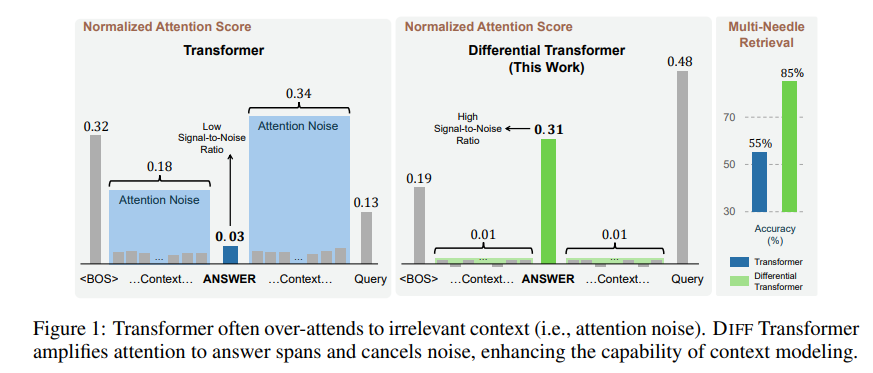
Para solucionar este problema, este artículo propone un Transformador Diferencial (Transformador DIFF). El nombre es muy avanzado, pero el principio es en realidad muy simple. Al igual que los auriculares con cancelación de ruido, el ruido se elimina mediante la diferencia entre dos señales.
El núcleo de Differential Transformer es el mecanismo de atención diferencial. Divide la consulta y los vectores clave en dos grupos, calcula dos mapas de atención respectivamente y luego resta estos dos mapas para obtener la puntuación de atención final. Este proceso es como fotografiar el mismo objeto con dos cámaras y luego superponer las dos fotografías y se resaltarán las diferencias.
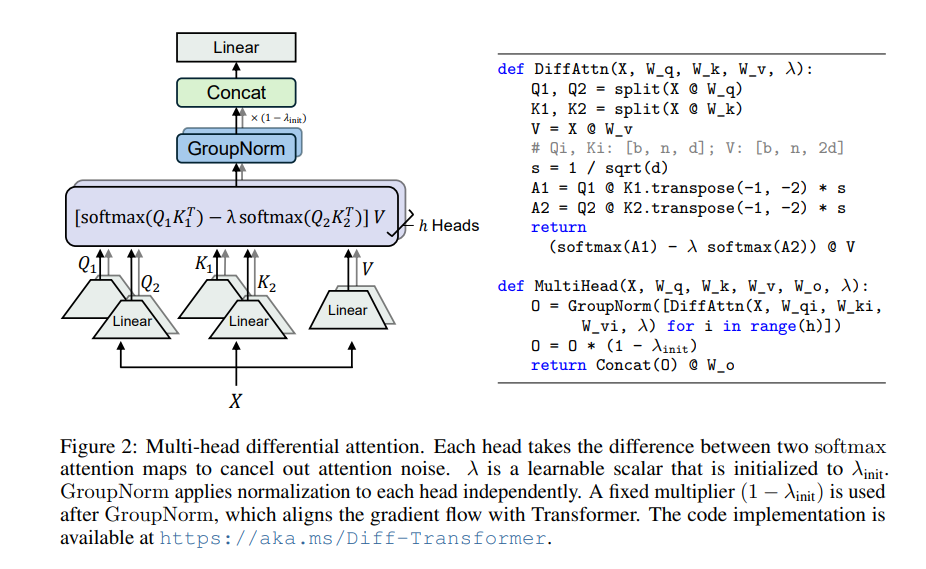
De esta manera, el transformador diferencial puede eliminar eficazmente el ruido de atención y permitir que el modelo se centre más en la información clave. Al igual que cuando te pones unos auriculares con cancelación de ruido, el ruido circundante desaparece y podrás escuchar el sonido que deseas con mayor claridad.
En el artículo se realizaron una serie de experimentos para demostrar la superioridad del transformador diferencial. En primer lugar, funciona bien en el modelado de lenguajes y solo requiere el 65% del tamaño del modelo o los datos de entrenamiento de Transformer para lograr resultados similares.
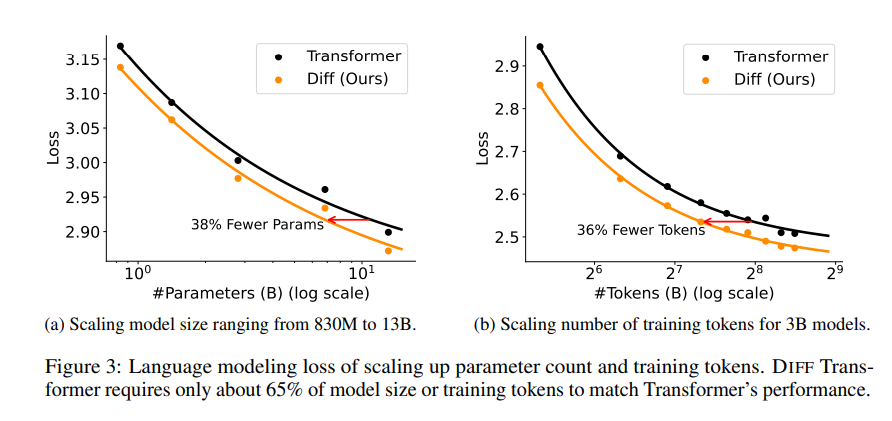
En segundo lugar, Differential Transformer también es mejor en el modelado de textos largos y puede utilizar eficazmente información contextual más larga.
Más importante aún, el transformador diferencial muestra ventajas significativas en la recuperación de información clave, la reducción de la ilusión del modelo y el aprendizaje del contexto.
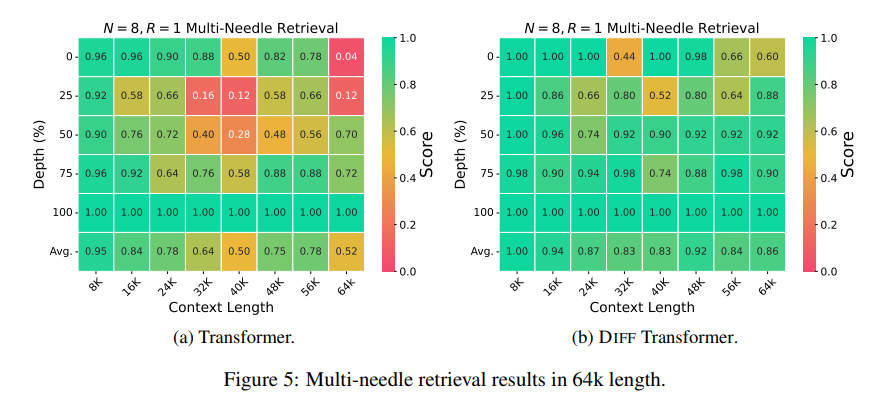
En términos de recuperación de información clave, Differential Transformer es como un motor de búsqueda preciso que puede encontrar con precisión lo que desea en cantidades masivas de información. Puede mantener una alta precisión incluso en escenarios con información extremadamente compleja.
En términos de reducir las alucinaciones del modelo, Differential Transformer puede evitar eficazmente las "tonterías" del modelo y generar resúmenes de texto y resultados de preguntas y respuestas más precisos y confiables.
En términos de aprendizaje contextual, Differential Transformer es más como un maestro del aprendizaje, capaz de aprender rápidamente nuevos conocimientos a partir de una pequeña cantidad de muestras y el efecto de aprendizaje es más estable, a diferencia de Transformer, que no se ve afectado fácilmente por el orden de las muestras. .
Además, el transformador diferencial también puede reducir eficazmente los valores atípicos en los valores de activación del modelo, lo que significa que es más fácil de cuantificar el modelo y puede lograr una cuantificación de bits más bajos, mejorando así la eficiencia del modelo.
Con todo, Differential Transformer resuelve eficazmente el problema del ruido de atención del modelo Transformer a través del mecanismo de atención diferencial y logra mejoras significativas en múltiples aspectos. Proporciona nuevas ideas para el desarrollo de modelos de lenguaje grandes y desempeñará un papel importante en más campos en el futuro.
Dirección del artículo: https://arxiv.org/pdf/2410.05258
Con todo, Differential Transformer proporciona un método eficaz para resolver el problema del ruido de atención del modelo Transformer. Su excelente rendimiento en múltiples campos indica su importante posición en el desarrollo de grandes modelos de lenguaje en el futuro. El editor de Downcodes recomienda a los lectores leer el artículo completo para obtener una comprensión profunda de sus detalles técnicos y perspectivas de aplicación. ¡Esperamos que Differential Transformer traiga más avances en el campo de la inteligencia artificial!