Apple ha lanzado una importante actualización de su modelo de inteligencia artificial multimodal MM1 - MM1.5. Esta actualización no es una simple iteración de la versión, sino una mejora integral de las capacidades del modelo, mejorando significativamente su rendimiento en la comprensión de imágenes, el reconocimiento de texto y la ejecución de comandos visuales. El editor de Downcodes explicará en detalle las mejoras de MM1.5 y su importancia en el campo de la inteligencia artificial multimodal.
Apple lanzó recientemente una importante actualización de su modelo de inteligencia artificial multimodal MM1, actualizándolo a la versión MM1.5. Esta actualización no es solo un simple cambio de número de versión, sino una mejora integral de la capacidad, que permite que el modelo muestre un rendimiento más potente en varios campos.
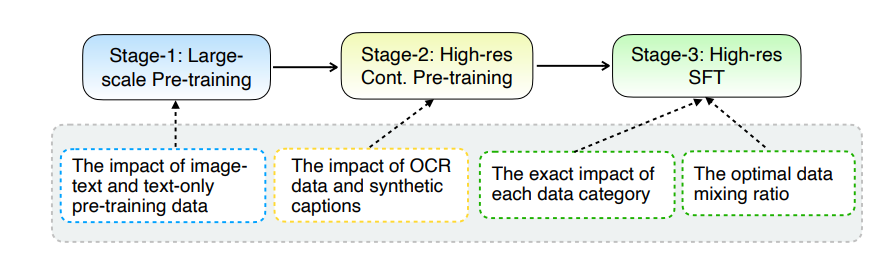
La principal actualización de MM1.5 radica en su innovador método de procesamiento de datos. El modelo adopta un enfoque de entrenamiento centrado en datos y el conjunto de datos de entrenamiento se selecciona y optimiza cuidadosamente. Específicamente, MM1.5 utiliza datos OCR de alta definición y descripciones de imágenes sintéticas, así como instrucciones visuales optimizadas para ajustar la combinación de datos. La introducción de estos datos ha mejorado significativamente el rendimiento del modelo en el reconocimiento de texto, la comprensión de imágenes y la ejecución de instrucciones visuales.

En términos de tamaño del modelo, MM1.5 cubre múltiples versiones que van desde mil millones a 30 mil millones de parámetros, incluidas variantes intensivas y mixtas de expertos (MoE). Vale la pena señalar que incluso los modelos de parámetros de escala más pequeña, de mil millones y 3 mil millones, pueden alcanzar niveles de rendimiento impresionantes con datos y estrategias de capacitación cuidadosamente diseñados.
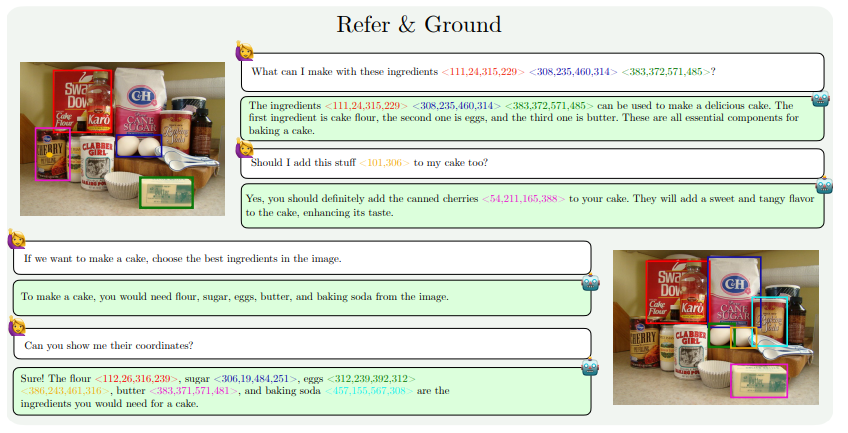
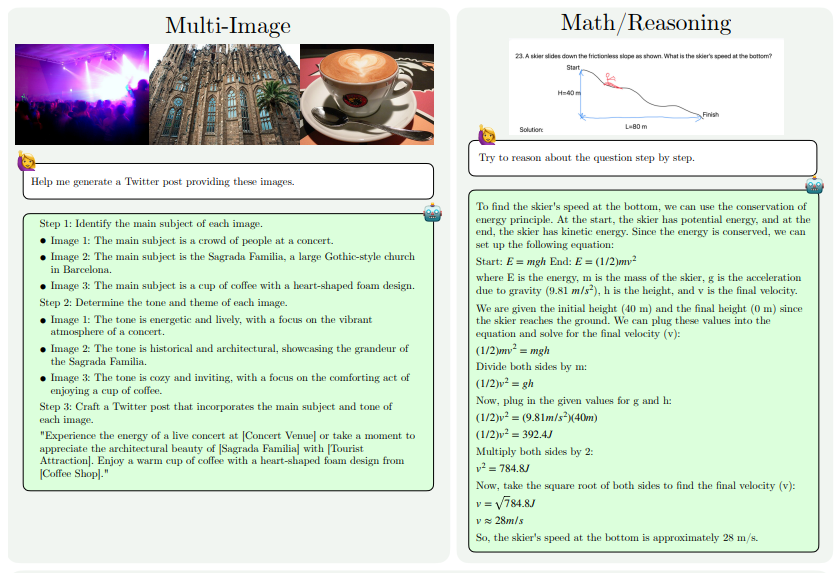
Las mejoras de capacidad de MM1.5 se reflejan principalmente en los siguientes aspectos: comprensión de imágenes con uso intensivo de texto, referencia y posicionamiento visual, razonamiento de múltiples imágenes, comprensión de videos y comprensión de la interfaz de usuario móvil. Estas capacidades permiten que MM1.5 se aplique a una gama más amplia de escenarios, como identificar artistas e instrumentos a partir de fotografías de conciertos, comprender datos de gráficos y responder preguntas relacionadas, localizar objetos específicos en escenas complejas, etc.
Para evaluar el rendimiento de MM1.5, los investigadores lo compararon con otros modelos multimodales avanzados. Los resultados muestran que MM1.5-1B funciona bien en un modelo con una escala de mil millones de parámetros, significativamente mejor que otros modelos del mismo nivel. MM1.5-3B supera a MiniCPM-V2.0 y está a la par con InternVL2 y Phi-3-Vision. Además, el estudio también encontró que ya sea un modelo denso o un modelo MoE, el rendimiento mejorará significativamente a medida que aumenta la escala.
El éxito de MM1.5 no sólo refleja la fuerza de investigación y desarrollo de Apple en el campo de la inteligencia artificial, sino que también señala el camino para el desarrollo futuro de modelos multimodales. Al optimizar los métodos de procesamiento de datos y la arquitectura del modelo, incluso los modelos de menor escala pueden lograr un rendimiento sólido, lo cual es de gran importancia para implementar modelos de IA de alto rendimiento en dispositivos con recursos limitados.
Dirección del artículo: https://arxiv.org/pdf/2409.20566
Con todo, el lanzamiento de MM1.5 marca un avance significativo en la tecnología de inteligencia artificial multimodal. Sus innovaciones en procesamiento de datos y arquitectura de modelos brindan nuevas ideas y direcciones para el desarrollo de futuros modelos de IA. Esperamos que Apple siga aportando más resultados innovadores en el campo de la inteligencia artificial.