El editor de Downcodes se enteró de que los equipos de investigación del Instituto de Tecnología de Illinois y otras universidades lanzaron conjuntamente Robin3D, un nuevo modelo de lenguaje grande de escena 3D. El modelo se entrenó en un conjunto de datos masivo que contenía millones de instrucciones y logró un rendimiento de vanguardia en cinco puntos de referencia de aprendizaje multimodal 3D de uso común. La innovación de Robin3D radica en su motor de datos RIG, que puede generar datos de instrucción contradictorios y diversificados, mejorando así las capacidades de discriminación, comprensión y generalización del modelo, superando las capacidades de generalización insuficientes y los problemas de sobreajuste del modelo de lenguaje grande 3D existente. También integra tecnologías como el Proyector de aumento de relaciones (RAP) y el Enlace de características de identificación (IFB) para mejorar la comprensión del modelo de escenas y objetos.
El modelo se entrenó en un conjunto de datos a gran escala que contiene un millón de instrucciones a seguir y logró un rendimiento de vanguardia en cinco puntos de referencia de aprendizaje multimodal 3D de uso común, lo que marca un paso importante en la construcción de un 3D universal. en dirección a agentes inteligentes.
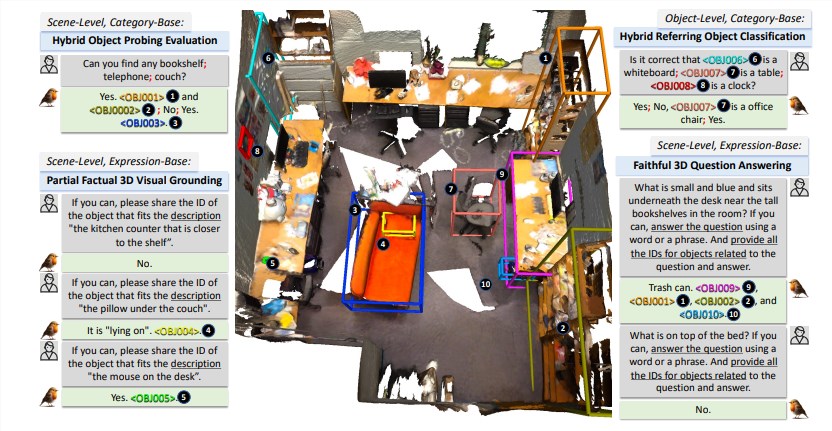
El éxito de Robin3D se debe a su innovador motor de datos RIG (Robust Institution Generation). El motor RIG está diseñado para generar dos tipos de datos de comandos clave: datos de cumplimiento de comandos adversarios y datos de cumplimiento de comandos diversos.
Los datos de seguimiento contradictorios mejoran la comprensión discriminativa del modelo al mezclar muestras positivas y negativas, mientras que los datos de seguimiento diversos contienen varios estilos de instrucción para mejorar la capacidad de generalización del modelo.
Los investigadores señalaron que los modelos de lenguaje grande 3D existentes se basan principalmente en pares de lenguaje visual 3D frontal e instrucciones basadas en plantillas para el entrenamiento, lo que conduce a capacidades de generalización insuficientes y al riesgo de sobreajuste. Robin3D supera eficazmente estas limitaciones al introducir datos de instrucción diversos y contradictorios.
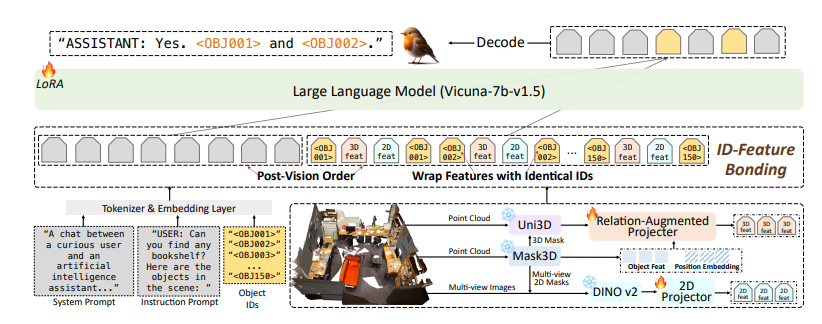
El modelo Robin3D también integra capacidades de posicionamiento y referencia de enlace de características de identificación de proyector aumentado de relación (RAP). El módulo RAP mejora las funciones centradas en objetos con rica información contextual y de ubicación a nivel de escena, mientras que el módulo IFB fortalece las conexiones entre cada ID vinculándolas a sus funciones correspondientes.
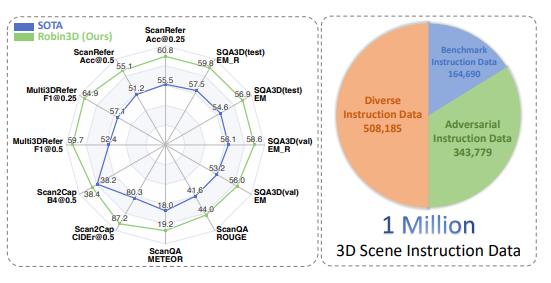
Los resultados experimentales muestran que Robin3D supera a los mejores métodos anteriores en cinco puntos de referencia, incluidos ScanRefer, Multi3DRefer, Scan2Cap, ScanQA y SQA3D, sin la necesidad de realizar ajustes para tareas específicas.
Especialmente en la evaluación de Multi3DRefer, incluido el caso de objetivo cero, Robin3D logró mejoras significativas del 7,8 % y 7,3 % en los indicadores [email protected] y [email protected] respectivamente.
El lanzamiento de Robin3D marca un progreso significativo en la inteligencia espacial de modelos 3D de lenguaje grande, sentando una base sólida para construir agentes 3D más versátiles y potentes en el futuro.
Dirección del artículo: https://arxiv.org/pdf/2410.00255
Sin duda, la aparición de Robin3D ha traído nuevos avances en los campos de la visión 3D y la inteligencia artificial. Vale la pena esperar su poderoso rendimiento y sus amplias perspectivas de aplicación. Creo que en el futuro, Robin3D desempeñará un papel en más campos y promoverá el rápido desarrollo de la inteligencia 3D. El editor de Downcodes seguirá atento a las últimas novedades en este campo.