El editor de Downcodes se enteró de que un estudio innovador de la Universidad de Yale reveló el secreto del entrenamiento del modelo de IA: la complejidad de los datos no es mayor, mejor, pero existe un estado óptimo de "borde del caos". El equipo de investigación utilizó inteligentemente el modelo de autómata celular para realizar experimentos, exploró el impacto de datos de diferente complejidad en el efecto de aprendizaje del modelo de IA y llegó a conclusiones llamativas.
Un equipo de investigación de la Universidad de Yale publicó recientemente un resultado de investigación innovador, que revela un hallazgo clave en el entrenamiento de modelos de IA: los datos con el mejor efecto de aprendizaje de IA no son más simples ni más complejos, sino que existe un nivel de complejidad óptimo, un estado conocido como borde del caos.
El equipo de investigación realizó experimentos utilizando autómatas celulares elementales (ECA), que son sistemas simples en los que el estado futuro de cada unidad depende únicamente de sí misma y de los estados de dos unidades adyacentes. A pesar de la simplicidad de las reglas, tales sistemas pueden producir diversos patrones que van desde simples hasta muy complejos. Luego, los investigadores evaluaron el desempeño de estos modelos de lenguaje en tareas de razonamiento y predicción de movimientos de ajedrez.
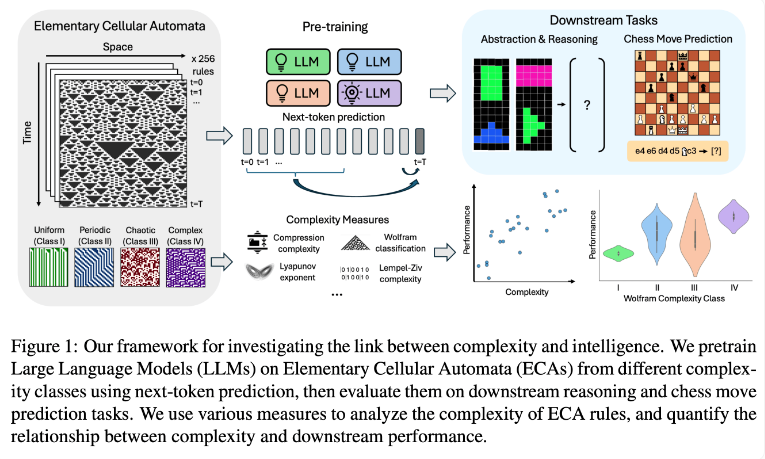
Los resultados de la investigación muestran que los modelos de IA entrenados con reglas ECA más complejas funcionan mejor en tareas posteriores. En particular, los modelos entrenados en ECA de Clase IV en la Clasificación Wolfram mostraron el mejor rendimiento. Los patrones generados por tales reglas no están completamente ordenados ni completamente caóticos, sino que exhiben una complejidad estructurada.
Los investigadores descubrieron que cuando los modelos eran expuestos a patrones demasiado simples, a menudo aprendían sólo soluciones simples. Por el contrario, los modelos entrenados con patrones más complejos desarrollan capacidades de procesamiento más sofisticadas incluso cuando hay soluciones simples disponibles. El equipo de investigación especula que la complejidad de esta representación aprendida es un factor clave en la capacidad del modelo para transferir conocimientos a otras tareas.
Este hallazgo puede explicar por qué los modelos de lenguajes grandes como GPT-3 y GPT-4 son tan eficientes. Los investigadores creen que los datos masivos y diversos utilizados en el entrenamiento de estos modelos pueden haber creado efectos similares a los complejos patrones ECA en su estudio.
Esta investigación proporciona nuevas ideas para el entrenamiento de modelos de IA y una nueva perspectiva para comprender las poderosas capacidades de los grandes modelos de lenguaje. En el futuro, tal vez podamos mejorar aún más el rendimiento y las capacidades de generalización de los modelos de IA controlando con mayor precisión la complejidad de los datos de entrenamiento. El editor de Downcodes cree que el resultado de esta investigación tendrá un profundo impacto en el campo de la inteligencia artificial.