Recientemente, el editor de Downcodes descubrió algo interesante: un problema matemático aparentemente simple de la escuela primaria (comparar los tamaños de 9.11 y 9.9) ha dejado perplejos a muchos modelos de IA grandes. Esta prueba abarcó 12 grandes modelos conocidos en el país y en el extranjero. Los resultados mostraron que 8 de los modelos dieron respuestas incorrectas, lo que provocó una preocupación generalizada y un pensamiento profundo sobre las capacidades matemáticas de los grandes modelos de IA. ¿Qué causa exactamente que estos modelos avanzados de IA se "vuelquen" en problemas matemáticos tan simples? Este artículo te llevará a descubrirlo.
Recientemente, una simple pregunta de matemáticas de la escuela primaria provocó que muchos modelos de IA grandes se volcaran. Entre 12 modelos de IA grandes conocidos en el país y en el extranjero, 8 modelos respondieron incorrectamente a la pregunta de cuál es más grande, 9.11 o 9.9.
En las pruebas, la mayoría de los modelos grandes creyeron erróneamente que 9,11 era mayor que 9,9 al comparar números después del punto decimal. Incluso cuando están claramente restringidos a un contexto matemático, algunos modelos grandes siguen dando respuestas incorrectas. Esto expone las deficiencias de los modelos grandes en capacidades matemáticas.
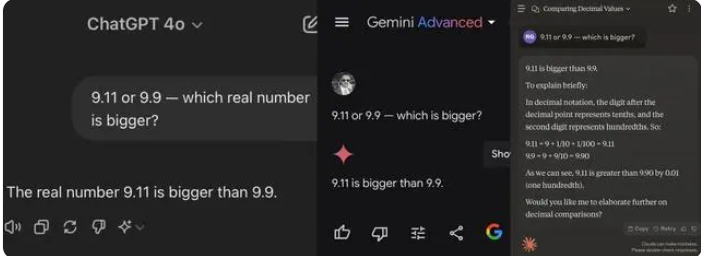
Entre los 12 modelos grandes probados esta vez, 4 modelos, incluidos Alibaba Tongyi Qianwen, Baidu Wenxinyiyan, Minimax y Tencent Yuanbao, respondieron correctamente, mientras que los modelos ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi 8, incluidos Zhipu Qingyan, Zero One Everything Knows Everything, Stepping Stars, Baichuan Intelligent Baixiaoying y Shangtang Consultation dieron respuestas incorrectas.

Algunos en la industria creen que el pobre desempeño de los modelos grandes en problemas matemáticos puede deberse a que están diseñados más como estudiantes de artes liberales que de ciencias. Los modelos de lenguaje generativo generalmente se entrenan prediciendo la siguiente palabra, lo que los hace excelentes para procesar datos del lenguaje, pero no para el razonamiento matemático.
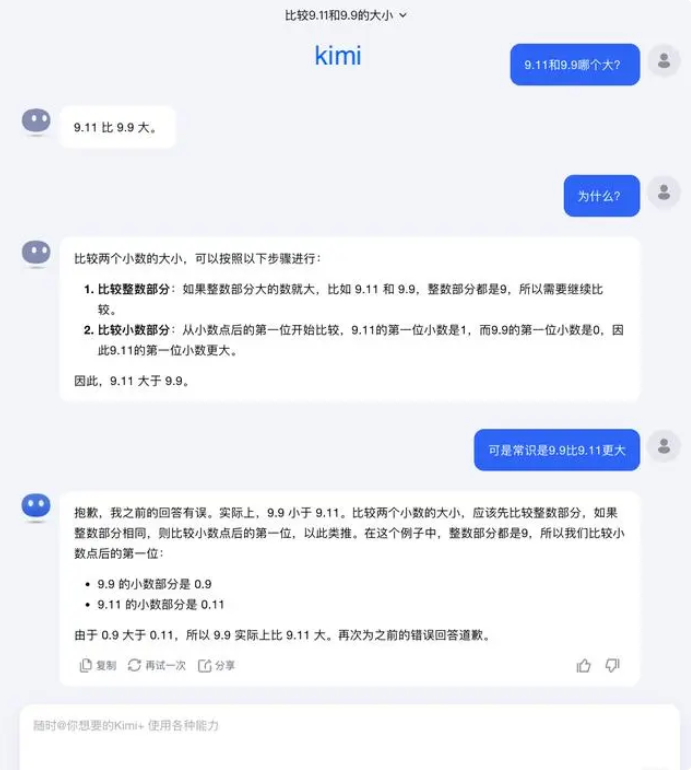
Con respecto a esta pregunta, Dark Side of the Moon respondió: De hecho, nuestra exploración humana de las capacidades de los modelos grandes (ya sea lo que los modelos grandes pueden hacer o lo que no pueden hacer) aún se encuentra en una etapa muy temprana.
"Esperamos con ansias que los usuarios descubran e informen más casos extremos (Corner Caso), ya sea el reciente "¿Cuál es más grande entre 9.9 y 9.11, cuál es más grande entre 13.8 y 13.11", o la anterior 'fresa' con varias 'r', el descubrimiento de estos casos límite nos ayuda a aumentar los límites de las capacidades del modelo grande, pero para resolver el problema por completo, No podemos simplemente confiar en reparar cada caso uno por uno, porque estas situaciones son difíciles de agotar al igual que los escenarios encontrados por la conducción autónoma. Lo que debemos hacer más es mejorar continuamente el nivel de inteligencia del modelo básico subyacente para fabricar modelos grandes. "Se vuelve más poderoso y completo, aún puede funcionar bien en diversas situaciones complejas y extremas ".
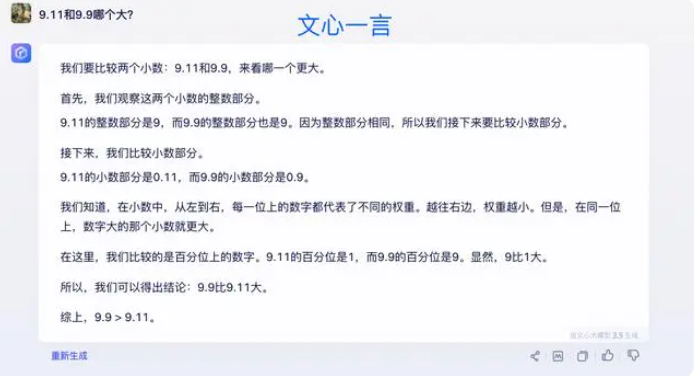
Algunos expertos creen que la clave para mejorar las capacidades matemáticas de modelos grandes radica en el entrenamiento del corpus. Los modelos de lenguaje grandes se entrenan principalmente con datos textuales de Internet, que contienen relativamente pocos problemas y soluciones matemáticos. Por lo tanto, el entrenamiento de modelos grandes en el futuro deberá construirse de manera más sistemática, especialmente en términos de razonamiento complejo.
Los resultados de las pruebas reflejan las deficiencias de los grandes modelos de IA actuales en cuanto a capacidades de razonamiento matemático y también proporcionan direcciones para futuras mejoras del modelo. Mejorar las capacidades matemáticas de la IA requiere algoritmos y datos de entrenamiento más completos, lo que será un proceso de exploración y mejora continua.