La inteligencia artificial ha logrado avances significativos en el reconocimiento de imágenes en los últimos años, pero la comprensión del vídeo sigue siendo un gran desafío. La dinámica y la complejidad de los datos de vídeo plantean dificultades sin precedentes a la IA. Sin embargo, se espera que el codificador de vídeo VideoPrism desarrollado por el equipo de investigación de Google cambie esta situación. El editor de Downcodes le brindará una comprensión profunda de las potentes funciones, los métodos de capacitación y el profundo impacto de VideoPrism en el campo futuro de la comprensión del video con IA.
En el mundo de la IA, a las máquinas les resulta mucho más difícil entender vídeos que entender imágenes. El vídeo es dinámico, con sonido, movimiento y un montón de escenas complejas. En el pasado, con la IA, ver vídeos era como leer un libro caído del cielo y, a menudo, uno se sentía confundido.
Pero la aparición de VideoPrism puede cambiarlo todo. Este es un codificador de video desarrollado por el equipo de investigación de Google. Puede alcanzar el nivel más moderno con un solo modelo en una variedad de tareas de comprensión de video. Ya sea clasificando videos, posicionándolos, generando subtítulos o incluso respondiendo preguntas sobre videos, VideoPrism puede manejarlo fácilmente.

¿Cómo entrenar VideoPrisma?
El proceso de entrenamiento de VideoPrism es como enseñarle a un niño a observar el mundo. Primero, debes mostrarle una variedad de videos, que van desde la vida cotidiana hasta observaciones científicas. Luego, también lo entrena con algunos pares de subtítulos de video de "alta calidad" y texto paralelo ruidoso (como texto de reconocimiento automático de voz).
Método de preentrenamiento
Datos: VideoPrism utiliza 36 millones de pares de subtítulos de vídeo de alta calidad y 58,2 millones de videoclips con texto paralelo ruidoso.
Arquitectura del modelo: Basado en el transformador visual estándar (ViT), utilizando diseño factorizado en espacio y tiempo.
Algoritmo de entrenamiento: incluye dos etapas: entrenamiento de comparación de video-texto y modelado de video enmascarado.
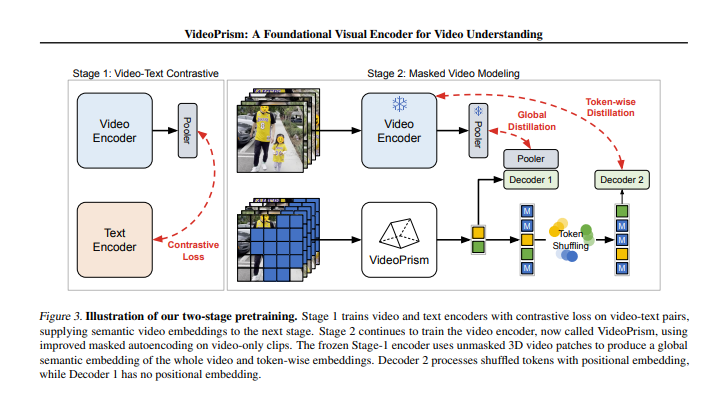
Durante el proceso de formación, VideoPrism pasará por dos etapas. En la primera etapa, aprende la conexión entre video y texto a través del aprendizaje contrastivo y la destilación global-local. En la segunda etapa, mejora aún más la comprensión del contenido de vídeo mediante modelado de vídeo enmascarado.
Los investigadores probaron VideoPrism en múltiples tareas de comprensión de videos y los resultados fueron impresionantes. VideoPrism logra un rendimiento de última generación en 30 de 33 puntos de referencia. Ya sea respondiendo preguntas de vídeo en línea o tareas de visión por computadora en el campo científico, VideoPrism ha demostrado sólidas capacidades.
El nacimiento de VideoPrism ha traído nuevas posibilidades al campo de la comprensión del vídeo con IA. No sólo puede ayudar a la IA a comprender mejor el contenido de vídeo, sino que también puede desempeñar un papel importante en la educación, el entretenimiento, la seguridad y otros campos.
Pero VideoPrism también enfrenta algunos desafíos, como cómo manejar videos largos y cómo evitar introducir sesgos durante el proceso de capacitación. Estas son cuestiones que deben abordarse en futuras investigaciones.
Dirección del artículo: https://arxiv.org/pdf/2402.13217
En definitiva, la aparición de VideoPrism marca un gran avance en el campo de la comprensión del vídeo con IA. Su potente rendimiento y sus amplias perspectivas de aplicación son apasionantes. En el futuro, con el desarrollo continuo de la tecnología, creo que VideoPrism mostrará su valor en más campos y brindará más comodidad a la vida de las personas.