El editor de Downcodes se enteró de que Groq lanzó recientemente un increíble motor LLM, cuya velocidad de procesamiento supera con creces las expectativas de la industria, brindando a los desarrolladores una experiencia interactiva de modelo de lenguaje a gran escala sin precedentes. Este motor se basa en el código abierto LLama3-8b-8192LLM de Meta y es compatible con otros modelos. Su velocidad de procesamiento llega a 1256,54 puntos por segundo, lo que está significativamente por delante de los chips GPU de empresas como Nvidia. Este innovador desarrollo no solo atrajo una amplia atención por parte de los desarrolladores, sino que también brindó una experiencia de aplicación LLM más rápida y flexible a los usuarios comunes.
Groq lanzó recientemente un motor LLM ultrarrápido en su sitio web, que permite a los desarrolladores realizar consultas rápidas y ejecución de tareas directamente en modelos de lenguaje grandes.
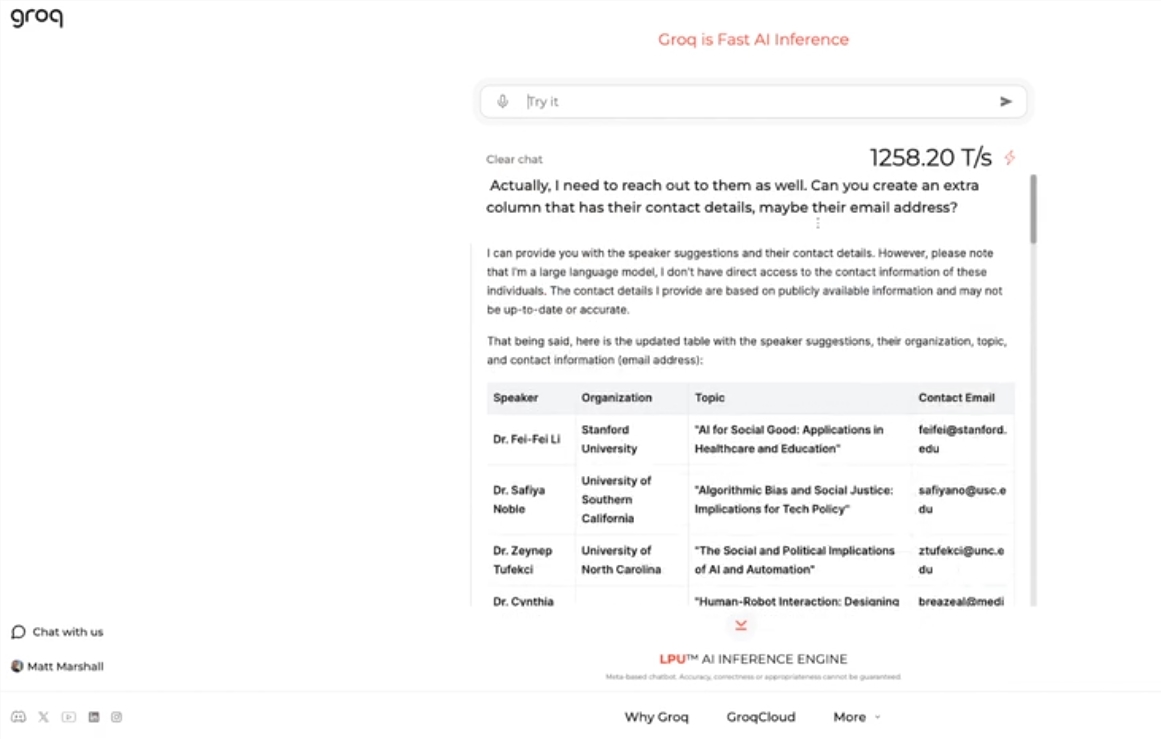
Este motor utiliza LLama3-8b-8192LLM de código abierto de Meta, admite otros modelos de forma predeterminada y es sorprendentemente rápido. Según los resultados de las pruebas, el motor de Groq puede manejar 1256,54 marcas por segundo, superando con creces a los chips GPU de empresas como Nvidia. La medida atrajo una amplia atención tanto de desarrolladores como de no desarrolladores, lo que demuestra la velocidad y flexibilidad del chatbot LLM.
El director ejecutivo de Groq, Jonathan Ross, dijo que el uso de LLM aumentará aún más a medida que la gente descubra lo fácil que es usarlos en el rápido motor de Groq. A través de la demostración, las personas pueden ver que se pueden completar fácilmente varias tareas a esta velocidad, como generar anuncios de trabajo, modificar el contenido del artículo, etc. El motor de Groq puede incluso realizar consultas basadas en comandos de voz, lo que demuestra su potencia y facilidad de uso.
Además de ofrecer servicios gratuitos de carga de trabajo LLM, Groq también proporciona a los desarrolladores una consola que les permite cambiar fácilmente las aplicaciones creadas en OpenAI a Groq.
Este sencillo método de cambio ha atraído a un gran número de desarrolladores y actualmente más de 280.000 personas han utilizado los servicios de Groq. El director ejecutivo Ross dijo que para el próximo año, más de la mitad de los cálculos de inferencia del mundo se ejecutarán en los chips de Groq, lo que demuestra el potencial y las perspectivas de la compañía en el campo de la IA.
Destacar:
Groq lanza un motor LLM ultrarrápido que procesa 1256,54 marcas por segundo, mucho más rápido que la velocidad de la GPU
El motor de Groq demuestra la velocidad y flexibilidad de los chatbots LLM, atrayendo la atención tanto de desarrolladores como de no desarrolladores.
Groq proporciona un servicio gratuito de carga de trabajo LLM que ha sido utilizado por más de 280.000 desarrolladores. Se espera que la mitad de los cálculos de inferencia del mundo se ejecuten en sus chips el próximo año.
El rápido motor LLM de Groq sin duda aporta nuevas posibilidades al campo de la IA, y su alto rendimiento y facilidad de uso promoverán una aplicación más amplia de la tecnología LLM. ¡El editor de Downcodes cree que vale la pena esperar con ansias el desarrollo futuro de Groq!