En los últimos años, el rápido desarrollo de la tecnología de inteligencia artificial depende en gran medida del entrenamiento de datos masivos. Sin embargo, el editor de Downcodes descubrió que las últimas investigaciones del MIT y otras instituciones señalaron que la dificultad para obtener datos está aumentando dramáticamente. Los datos de la red que alguna vez estuvieron fácilmente disponibles ahora están sujetos a restricciones cada vez más estrictas, lo que plantea enormes desafíos para la capacitación y el desarrollo de la IA. El estudio, que analizó múltiples conjuntos de datos de código abierto, revela esta cruda realidad.
Detrás del rápido desarrollo de la inteligencia artificial, está surgiendo un problema grave: la dificultad de adquisición de datos está aumentando. Las últimas investigaciones del MIT y otras instituciones han descubierto que los datos web que alguna vez fueron fácilmente accesibles ahora son cada vez más difíciles de acceder, lo que plantea un desafío importante para la capacitación y la investigación de la IA.
Los investigadores descubrieron que los sitios web rastreados por múltiples conjuntos de datos de código abierto como C4, RefineWeb, Dolma, etc. están ajustando rápidamente sus acuerdos de licencia. Esto no sólo afecta al entrenamiento de modelos comerciales de IA, sino que también obstaculiza la investigación por parte de organizaciones académicas y sin fines de lucro.

Esta investigación fue realizada por cuatro líderes de equipo del MIT Media Lab, Wellesley College, la startup de IA Raive y otras instituciones. Señalan que las restricciones de datos están proliferando y que las asimetrías e inconsistencias en las licencias son cada vez más evidentes.
El equipo de investigación utilizó el Protocolo de exclusión de robots (REP) y los Términos de servicio (ToS) del sitio web como métodos de investigación. Descubrieron que incluso los rastreadores de grandes empresas de inteligencia artificial como OpenAI enfrentaban restricciones cada vez más estrictas.
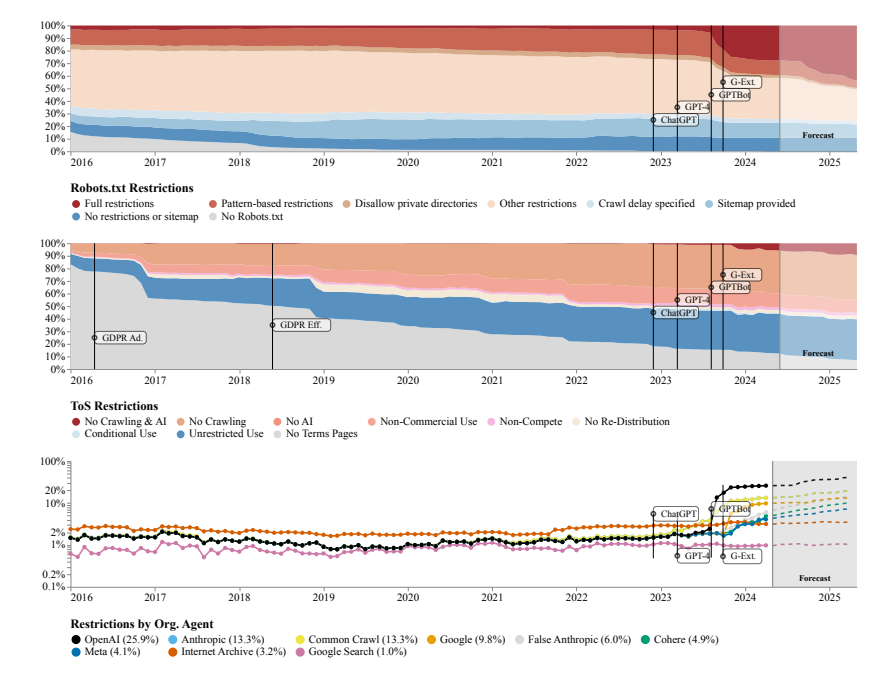
El modelo SARIMA predice que en el futuro, ya sea a través de robots.txt o ToS, las restricciones de datos de los sitios web seguirán aumentando. Esto sugiere que el acceso a los datos de la red abierta será más difícil.
El estudio también encontró que los datos rastreados de Internet no son consistentes con el propósito de entrenamiento del modelo de IA, lo que puede tener un impacto en la alineación del modelo, las prácticas de recopilación de datos y los derechos de autor.
El equipo de investigación plantea la necesidad de acuerdos más flexibles que reflejen los deseos de los propietarios de sitios web, separe los casos de uso permitidos y no permisibles y se sincronicen con los términos de servicio. Al mismo tiempo, quieren que los desarrolladores de IA puedan utilizar datos en la web abierta para capacitación, y esperan que las leyes futuras lo respalden.
Dirección del artículo: https://www.dataprovenance.org/Consent_in_Crisis.pdf
Esta investigación ha dado la voz de alarma sobre el problema de la adquisición de datos en el campo de la inteligencia artificial, y también ha planteado nuevos retos para el entrenamiento y desarrollo de futuros modelos de IA. Cómo equilibrar la adquisición de datos y los derechos e intereses de los propietarios de sitios web se convertirá en una cuestión clave que deberá considerarse y resolverse seriamente en el campo de la inteligencia artificial. El editor de Downcodes recomienda prestar atención al artículo para conocer más detalles.