¡El editor de Downcodes le brindará una comprensión profunda de los secretos del modelo Transformer! Recientemente, un artículo titulado "Transformer Layers as Painters" explicó vívidamente el mecanismo de trabajo de la capa intermedia del modelo Transformer desde la perspectiva de un "pintor". A través de ingeniosas metáforas y experimentos, este artículo revela cómo opera la jerarquía Transformer, brindándonos nuevas ideas para comprender las operaciones internas de grandes modelos de lenguaje. En el artículo, el autor compara cada capa del Transformer con un pintor, trabajando juntos para crear una imagen con un gran lenguaje, y verifica esta visión a través de una serie de experimentos.
En el mundo de la inteligencia artificial, existe un grupo especial de pintores: la estructura jerárquica en el modelo Transformer. Son como pinceles mágicos que pintan un mundo colorido sobre el lienzo del lenguaje. Recientemente, un artículo llamado Transformer Layers as Painters nos proporciona una nueva perspectiva para comprender el mecanismo de funcionamiento de la capa intermedia de Transformer.
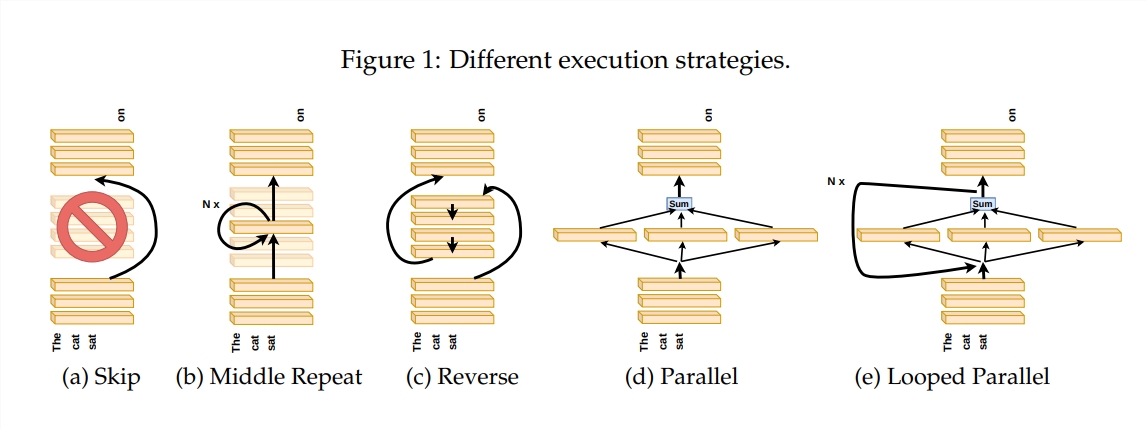
El modelo Transformer, como modelo de lenguaje a gran escala más popular en la actualidad, tiene miles de millones de parámetros. Cada capa es como un pintor, trabajando en conjunto para completar una imagen de gran lenguaje. Pero, ¿cómo trabajaron juntos estos pintores? ¿En qué se diferenciaban los pinceles y las pinturas que utilizaban? Este artículo intenta responder a estas preguntas.
Para explorar cómo funciona la capa Transformer, el autor diseñó una serie de experimentos, que incluyen omitir ciertas capas, cambiar el orden de las capas o ejecutar capas en paralelo. Estos experimentos son como establecer diferentes reglas de pintura para que los pintores vean si pueden adaptarse.
En la metáfora del "canal del pintor", la entrada se ve como un lienzo, y el proceso de pasar a través de las capas intermedias es como el paso del lienzo en la línea de montaje. Cada "pintor", es decir, cada capa del Transformador, modificará la pintura según su propia experiencia. Esta analogía nos ayuda a comprender el paralelismo y la escalabilidad de la capa Transformer.
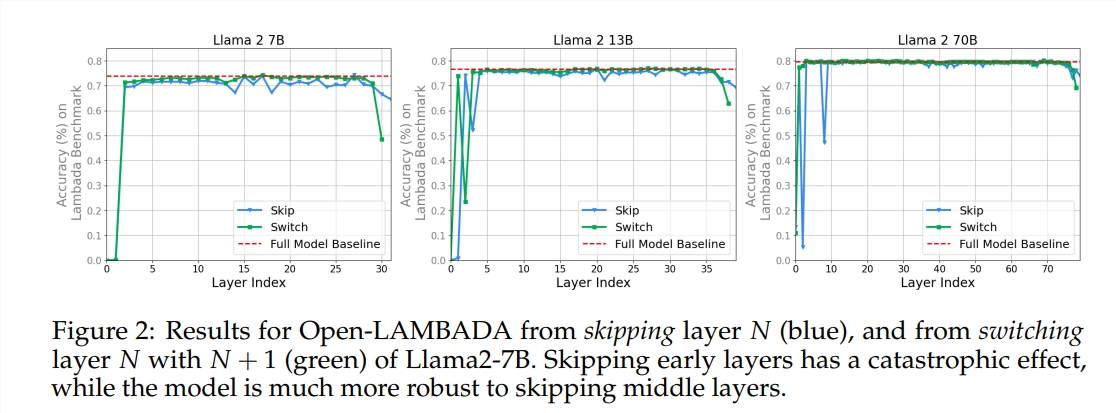
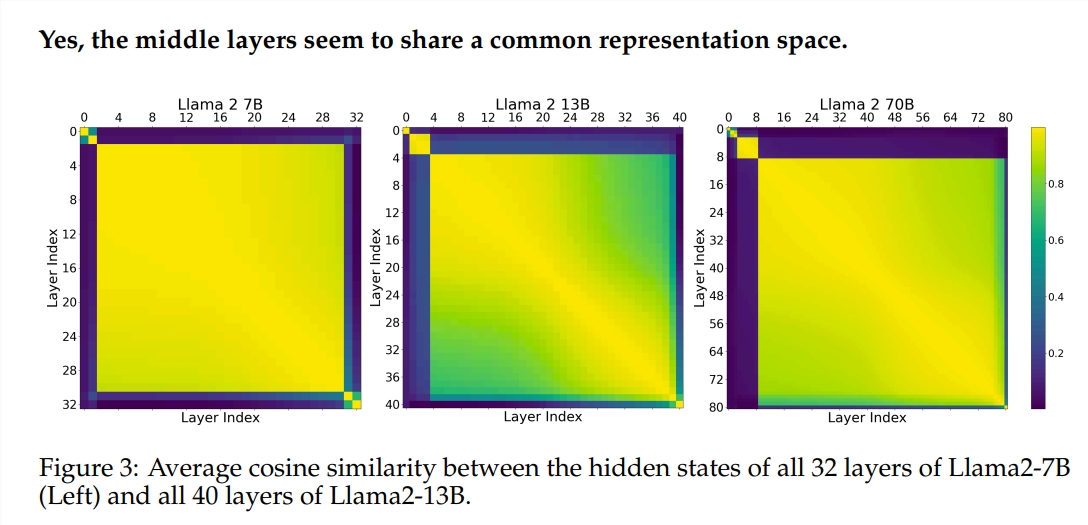
El experimento utilizó dos modelos de lenguaje grande (LLM) previamente entrenados: Llama2-7B y BERT. El estudio encontró que los pintores de los niveles intermedios parecían compartir una caja de pintura común, que representaba el espacio, diferente de los del primer y último nivel. Los pintores que se saltan ciertas capas intermedias tienen poco impacto en toda la pintura, lo que indica que no todos los pintores son necesarios.
Aunque los pintores de la capa intermedia usan la misma caja de pintura, usan sus propias habilidades para pintar diferentes patrones en el lienzo. Si simplemente reutilizas la técnica de un determinado pintor, la pintura perderá su encanto original.
El orden en el que dibujas es particularmente importante para tareas matemáticas y de razonamiento que requieren una lógica estricta. Para tareas que dependen de la comprensión semántica, el impacto del orden es relativamente pequeño.
Los resultados de la investigación muestran que la capa intermedia del Transformer tiene cierto grado de consistencia pero no es redundante. Para tareas matemáticas y de razonamiento, el orden de las capas es más importante que para tareas semánticas.
El estudio también encontró que no todas las capas son necesarias y que las capas intermedias se pueden omitir sin afectar catastróficamente el rendimiento del modelo. Además, aunque las capas intermedias comparten el mismo espacio de representación, realizan funciones diferentes. Cambiar el orden de ejecución de las capas resultó en una degradación del rendimiento, lo que indica que el orden tiene un impacto importante en el rendimiento del modelo.
En el camino hacia la exploración del modelo Transformer, muchos investigadores están intentando optimizarlo, incluida la poda, la reducción de parámetros, etc. Estos trabajos brindan valiosa experiencia e inspiración para comprender el modelo Transformer.
Dirección del artículo: https://arxiv.org/pdf/2407.09298v1
Con todo, este artículo nos proporciona una nueva perspectiva para comprender el mecanismo interno del modelo Transformer y proporciona nuevas ideas para la optimización futura del modelo. El editor de Downcodes recomienda que los lectores interesados lean el artículo completo para comprender en profundidad los misterios del modelo Transformer.