El campo del procesamiento del lenguaje natural (PNL) cambia cada día que pasa y el rápido desarrollo de grandes modelos de lenguaje (LLM) nos ha brindado oportunidades y desafíos sin precedentes. Entre ellos, la dependencia de la evaluación del modelo de los datos anotados por humanos es un cuello de botella. El alto costo y el tiempo del trabajo de recopilación de datos limitan la evaluación efectiva y la mejora continua del modelo. El editor de Downcodes le presentará una nueva solución propuesta por los investigadores de Meta FAIR: el "Evaluador de autoaprendizaje", que proporciona una nueva idea para resolver este problema.
En la era actual, el campo del procesamiento del lenguaje natural (PLN) se está desarrollando rápidamente y los modelos de lenguaje grandes (LLM) pueden realizar tareas complejas relacionadas con el lenguaje con alta precisión, brindando más posibilidades para la interacción persona-computadora. Sin embargo, un problema importante en la PNL es la dependencia de anotaciones humanas para la evaluación del modelo.
Los datos generados por humanos son fundamentales para el entrenamiento y la validación de modelos, pero recopilar estos datos es costoso y requiere mucho tiempo. Además, a medida que los modelos continúan mejorando, es posible que sea necesario actualizar las anotaciones recopiladas anteriormente, lo que las hace menos útiles para evaluar nuevos modelos. Esto resulta en la necesidad de adquirir nuevos datos continuamente, lo que plantea desafíos a la escala y la sostenibilidad de la evaluación efectiva del modelo.
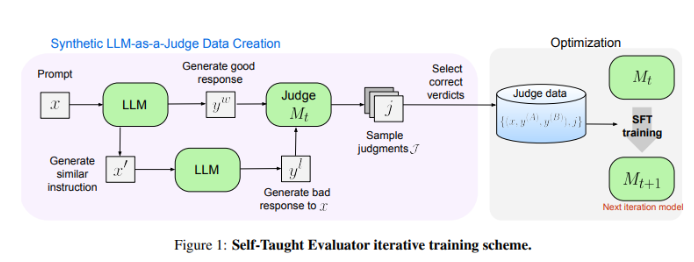
Los investigadores de Meta FAIR han ideado una nueva solución: el "evaluador autodidacta". Este enfoque no requiere anotaciones humanas y se basa en datos generados sintéticamente. Primero, un modelo semilla genera pares de preferencias sintéticas contrastantes y luego el modelo evalúa estos pares y los mejora iterativamente, utilizando su propio criterio para mejorar el rendimiento en iteraciones posteriores, lo que reduce en gran medida la dependencia de las anotaciones generadas por humanos.
Los investigadores probaron el desempeño del "evaluador de autoaprendizaje" utilizando el modelo Llama-3-70B-Instruct. Este método mejora la precisión del modelo en el punto de referencia RewardBench de 75,4 a 88,7, igualando o incluso superando el rendimiento de los modelos entrenados con anotaciones humanas. Después de múltiples iteraciones, el modelo final logró una precisión de 88,3 en una sola inferencia y 88,7 en una votación mayoritaria, lo que demuestra su gran estabilidad y confiabilidad.
El "Evaluador de autoaprendizaje" proporciona una solución escalable y eficiente para la evaluación de modelos de PNL, aprovechando datos sintéticos y la superación personal iterativa, abordando los desafíos de depender de anotaciones humanas y avanzando en el desarrollo de modelos de lenguaje.
Dirección del artículo: https://arxiv.org/abs/2408.02666
El "evaluador de autoaprendizaje" de Meta FAIR ha traído cambios revolucionarios a la evaluación del modelo de PNL, y sus características eficientes y escalables promoverán efectivamente el progreso continuo de los modelos de lenguaje futuros. El resultado de esta investigación no solo reduce la dependencia de los datos anotados por humanos, sino que, lo que es más importante, allana el camino para construir modelos de PNL más potentes y confiables. ¡Esperamos más innovaciones similares en el futuro!