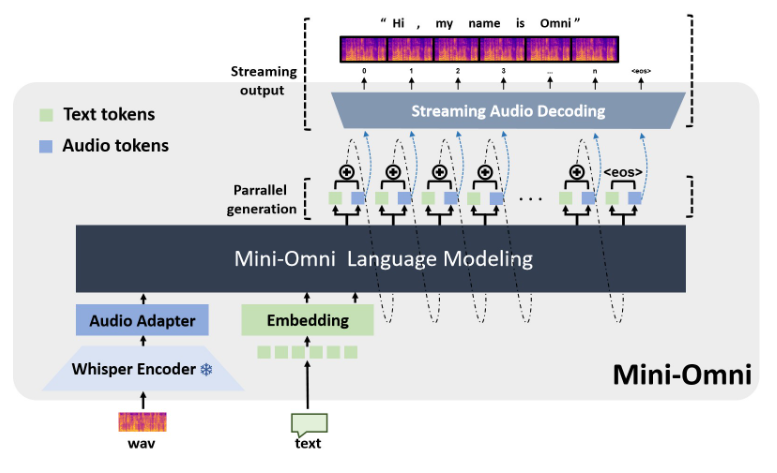
Mini-Omni, un modelo de lenguaje multimodal a gran escala de código abierto, está revolucionando la tecnología de interacción de voz. Integra tecnología avanzada para realizar entrada y salida de voz en tiempo real, y tiene la capacidad de pensar y hablar al mismo tiempo, brindando una experiencia de interacción persona-computadora más natural y fluida. La principal ventaja de Mini-Omni radica en sus capacidades de procesamiento de voz en tiempo real de extremo a extremo. No se requiere configuración adicional de los modelos ASR o TTS para disfrutar de conversaciones fluidas. Admite múltiples entradas modales y las convierte de manera flexible para adaptarse a diversos escenarios complejos y satisfacer diversas necesidades.
Hoy en día, con el rápido desarrollo de la inteligencia artificial, un modelo de lenguaje multimodal a gran escala de código abierto llamado Mini-Omni está liderando la innovación de la tecnología de interacción de voz. Este sistema de inteligencia artificial integrado con múltiples tecnologías avanzadas no solo permite la entrada y salida de voz en tiempo real, sino que también tiene la capacidad única de pensar y hablar al mismo tiempo, brindando a los usuarios una experiencia de interacción natural sin precedentes.
La principal ventaja de Mini-Omni reside en sus capacidades de procesamiento de voz en tiempo real de extremo a extremo. Los usuarios pueden disfrutar de conversaciones de voz fluidas sin configuración adicional de modelos de reconocimiento automático de voz (ASR) o texto a voz (TTS). Este diseño perfecto mejora enormemente la experiencia del usuario y hace que la interacción persona-computadora sea más natural e intuitiva.
Además de la función de voz, Mini-Omni también admite la entrada en múltiples modos, como texto, y puede cambiar de manera flexible entre diferentes modos. Esta capacidad de procesamiento multimodal permite que el modelo se adapte a varios escenarios de interacción complejos y satisfaga las diversas necesidades de los usuarios.
Particularmente digna de mención es la función Cualquier modelo puede hablar de Mini-Omni. Esta innovación permite que otros modelos de IA integren fácilmente las capacidades de voz en tiempo real de Mini-Omni, ampliando enormemente las posibilidades de las aplicaciones de IA. Esto no sólo proporciona a los desarrolladores más opciones, sino que también allana el camino para la aplicación multicampo de la tecnología de IA.
En términos de rendimiento, Mini-Omni muestra su fortaleza integral. No solo funciona bien en tareas de voz tradicionales como el reconocimiento de voz (ASR) y la generación de voz (TTS), sino que también muestra un gran potencial en tareas multimodales que requieren capacidades de razonamiento complejas como TextQA y SpeechQA. Esta capacidad integral permite a Mini-Omni manejar una variedad de escenarios de interacción complejos, desde simples comandos de voz hasta tareas de preguntas y respuestas que requieren un pensamiento profundo.
La implementación técnica de Mini-Omni incorpora múltiples modelos y tecnologías de IA avanzados. Utiliza Qwen2 como base de un modelo de lenguaje grande, usa litGPT para entrenamiento e inferencia, usa susurro para la codificación de audio y snac es responsable de la decodificación de audio. Este método de fusión de múltiples tecnologías no solo mejora el rendimiento general del modelo, sino que también mejora su adaptabilidad en diferentes escenarios.
Para desarrolladores e investigadores, Mini-Omni proporciona un uso cómodo. Con sencillos pasos de instalación, los usuarios pueden iniciar Mini-Omni en su entorno local y realizar demostraciones interactivas a través de herramientas como Streamlit y Gradio. Esta característica abierta y fácil de usar brinda un fuerte apoyo a la popularización y aplicación innovadora de la tecnología de IA.
Dirección del proyecto: https://github.com/gpt-omni/mini-omni
Con sus potentes funciones, uso conveniente y características de código abierto, Mini-Omni brinda nuevas posibilidades al campo de la interacción de voz con IA y merece la atención y exploración de desarrolladores e investigadores. También vale la pena esperar su desarrollo futuro.