Recientemente, el modelo de IA de código abierto Reflection70B ha atraído una gran atención en la industria debido a su controversia sobre su rendimiento. El modelo fue lanzado por HyperWrite, que originalmente afirmó que era el modelo de código abierto más poderoso del mundo y atrajo mucha atención debido a su excelente desempeño en pruebas de terceros. Sin embargo, algunas instituciones y usuarios independientes cuestionaron posteriormente su rendimiento y los resultados de las pruebas difirieron significativamente de las afirmaciones iniciales de HyperWrite.
El modelo de IA de código abierto Reflection70B, que acaba de debutar, ha sido recientemente cuestionado ampliamente por la industria.
Este modelo lanzado por la startup neoyorquina HyperWrite, que dice ser la variante Llama3.1 de Meta, ha llamado la atención por su excelente rendimiento en pruebas de terceros. Sin embargo, cuando se publicaron algunos resultados de las pruebas, la reputación de Reflection70B comenzó a verse cuestionada.
La causa del problema fue que el cofundador y director ejecutivo de HyperWrite, Matt Shumer, anunció Reflection70B en la red social X el 6 de septiembre y lo llamó con confianza "el modelo de código abierto más fuerte del mundo".
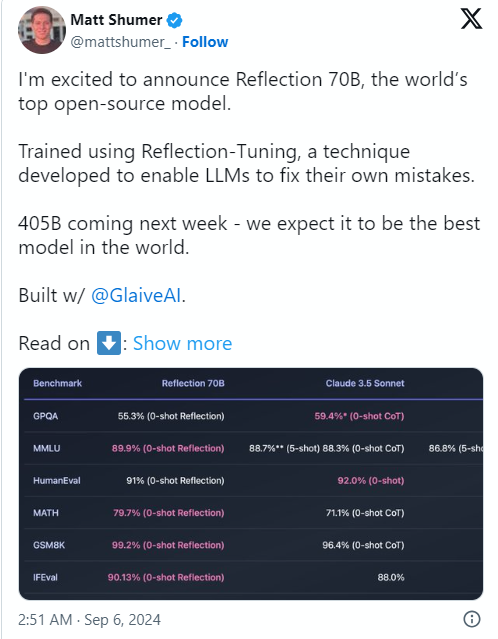
Shumer también compartió sobre la tecnología de “ajuste reflectante” del modelo, afirmando que este método permite que el modelo se revise a sí mismo antes de generar contenido, mejorando así la precisión.
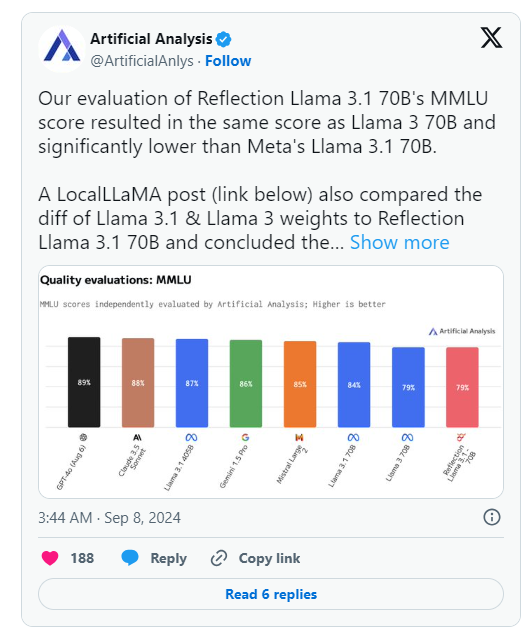
Sin embargo, el día después del anuncio de HyperWrite, Artificial Analysis, un grupo que se especializa en "análisis independiente de modelos de IA y proveedores de alojamiento", publicó su propio análisis sobre X, señalando que evaluaron la puntuación MMLU (Comprensión masiva del lenguaje multitarea) de Reflection Llama3.170B. es igual que Llama370B, pero significativamente menor que Llama3.170B de Meta, lo cual es una diferencia significativa de los resultados publicados originalmente por HyperWrite/Shumer.
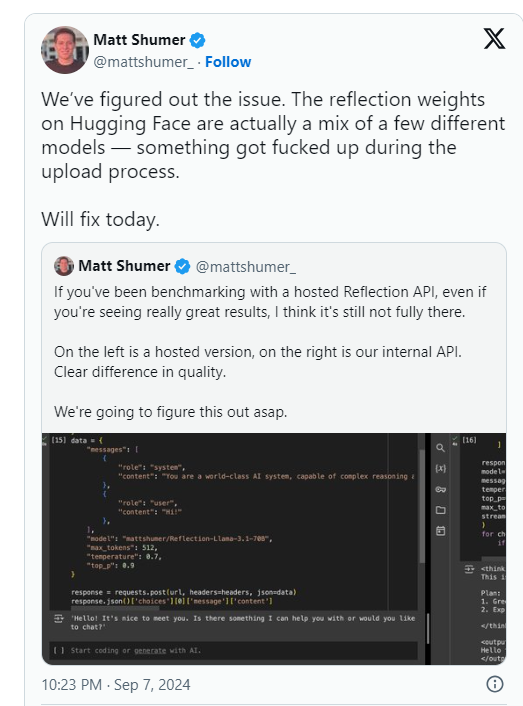
Shumer declaró más tarde que había un problema con los pesos de Reflection70B (o configuraciones para el modelo de código abierto) durante la carga a Hugging Face (una empresa y repositorio de alojamiento de código de IA de terceros), lo que puede haber resultado en un peor rendimiento que la "API interna" de HyperWrite. " versión. .
Artificial Analysis dijo en una declaración posterior que obtuvieron acceso a la API privada y vieron un rendimiento impresionante, pero no al nivel indicado originalmente. Dado que esta prueba se realizó en una API privada, no pudieron verificar de forma independiente lo que estaban probando.
El grupo planteó dos cuestiones clave que cuestionan seriamente las afirmaciones de rendimiento originales de HyperWrite y Shumer:
Mientras tanto, los usuarios de múltiples comunidades de aprendizaje automático e inteligencia artificial en Reddit también han cuestionado el rendimiento y los orígenes de Reflection70B. Algunos han señalado que Reflection70B parece ser una variante de Llama3 en lugar de Llama-3.1 , según una comparación de modelos publicada por un tercero en Github, lo que arroja más dudas sobre las afirmaciones originales de Shumer y HyperWrite.
Esto resultó en que al menos un usuario de X, Shin Megami Boson, publicara el 8 de septiembre ET.
A las 8:07 p.m.EDT, Shumer acusó públicamente a Shumer de “conducta fraudulenta” en la comunidad de investigación de IA y publicó una larga lista de capturas de pantalla y otras pruebas.
Otros han alegado que el modelo es en realidad un "envoltorio" o aplicación construida sobre Claude3 de Anthropic, competidor propietario/de código cerrado.
Sin embargo, otros usuarios de X han salido en defensa de Shumer y el Reflection70B, y algunos también han publicado un rendimiento impresionante en su parte del modelo.
Actualmente, la comunidad de investigación de IA está esperando la respuesta de Shumer a estas acusaciones de fraude y los pesos de los modelos actualizados en Hugging Face.
Después del lanzamiento del modelo Reflection70B, se cuestionó el rendimiento y los resultados de las pruebas no lograron replicar las afirmaciones iniciales.
⚙️ El fundador de HyperWrite explicó que los problemas de carga del modelo causaron una degradación del rendimiento y llamó la atención sobre la versión actualizada.
El modelo ha sido objeto de acalorados debates en las redes sociales, con acusaciones y defensas mezcladas.
En la actualidad, el incidente del Reflection70B aún continúa fermentando y el resultado final aún debe esperar más investigación y respuesta. Este incidente también nos recuerda que debemos tener cuidado con la promoción del rendimiento de cualquier modelo de IA y confiar en resultados de verificación independientes para emitir juicios.