El equipo OpenDataLab de la base de datos de modelos grandes del Laboratorio de Inteligencia Artificial de Shanghai (Laboratorio de IA de Shanghai) lanzó una nueva herramienta inteligente de extracción de datos MinerU en el Foro Principal WAIC Science Frontier de 2024. Esta herramienta de código abierto tiene como objetivo simplificar el proceso de procesamiento de datos de IA y ayudar a los investigadores a extraer datos de alta calidad de documentos masivos de manera más eficiente. MinerU admite una variedad de formatos de documentos, incluidos PDF, páginas web, epub, mobi y docx, etc., y los convierte a formato Markdown que es fácil de analizar. Sus módulos funcionales principales Magic-PDF y Magic-Doc se centran en la extracción de documentos PDF y páginas web/libros electrónicos respectivamente, y utilizan modelos como LayoutLMv3, YOLOv8, UniMERNet y PaddleOCR para lograr una extracción de datos de alta calidad, mejorando enormemente los datos. eficiencia de procesamiento.
En el Foro Principal WAIC Science Frontier de 2024, el equipo OpenDataLab de la base de datos de modelos grandes del Laboratorio de Inteligencia Artificial de Shanghai (Laboratorio de IA de Shanghai) lanzó una nueva herramienta inteligente de extracción de datos llamada MinerU. Esta herramienta está diseñada para simplificar el proceso de procesamiento de datos de IA y ayudar a los investigadores de IA a extraer datos de alta calidad de documentos masivos.
MinerU es una herramienta todo en uno de extracción de datos de páginas web y documentos de código abierto que puede convertir documentos PDF multimodales, incluidas imágenes, tablas, fórmulas, etc., a un formato Markdown claro y fácil de analizar. También puede analizar y extraer rápidamente contenido formal de páginas web que contienen información de interferencia, como anuncios, y admite la conversión por lotes de múltiples formatos como epub, mobi, docx, etc. a Markdown.
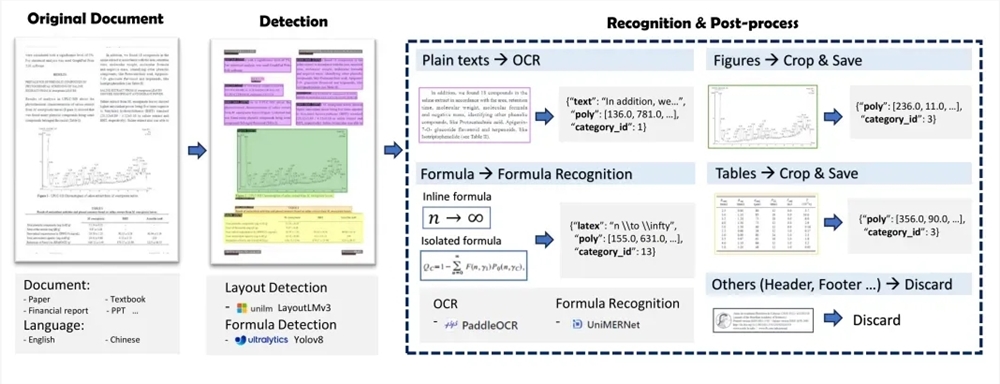
MinerU consta de dos partes principales: Magic-PDF y Magic-Doc. Magic-PDF se centra en la extracción de documentos PDF y convierte PDF al formato Markdown. Puede identificar rápidamente elementos de diseño de PDF, eliminar automáticamente contenido que no sea texto y conservar la estructura y el formato del documento original. Magic-Doc es responsable de extraer páginas web y libros electrónicos, admitiendo la extracción de información común de páginas web como artículos, foros, música, videos, etc., así como la conversión de formatos de libros electrónicos.
A nivel técnico, el proceso de extracción de documentos PDF de MinerU incluye preprocesamiento de clasificación de documentos PDF, análisis de modelos, procesamiento de canales e inspección de calidad de los resultados de la extracción de PDF. Utiliza una serie de modelos, como LayoutLMv3, YOLOv8, UniMERNet y PaddleOCR, para lograr una extracción de datos de documentos de alta calidad.
El lanzamiento de MinerU no solo proporciona a los investigadores de IA una poderosa herramienta de procesamiento de datos, sino que también promueve aún más la actualización de todo el sistema de herramientas de la cadena para el desarrollo y la aplicación de modelos a gran escala.
Enlace de experiencia de la comunidad mágica:
https://modelscope.cn/studios/OpenDataLab/MinerU
Enlace de código abierto:
https://github.com/opendatalab/MinerU/
Modelo de código abierto de MinerU (PDF-Extract-Kit):
https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit
El código abierto y la facilidad de uso de MinerU facilitarán enormemente a los investigadores y desarrolladores de IA, acelerarán la eficiencia del procesamiento de datos en el campo de la IA y brindarán un fuerte soporte para el desarrollo de modelos grandes. Bienvenido a visitar el enlace para experimentar y utilizar MinerU.