Moore Thread ha abierto su gran modelo de comprensión de audio MooER, que es el primer gran modelo de voz de código abierto de la industria basado en entrenamiento e inferencia de GPU nacional con todas las funciones, lo cual es un hito. MooER admite el reconocimiento de voz en chino e inglés y la traducción fonética chino-inglés, lo que demuestra potentes capacidades de procesamiento en varios idiomas. Su innovadora estructura de modelo de tres partes (codificador, adaptador y decodificador) permite que el modelo procese audio de manera eficiente y realice tareas posteriores. En la actualidad, el código de inferencia y el modelo entrenado en base a 5000 horas de datos son de código abierto. En el futuro, el código de entrenamiento y el modelo mejorado entrenado en base a 80.000 horas de datos serán de código abierto, lo que promoverá en gran medida el desarrollo. de la tecnología de inteligencia artificial de audio en el país y en el extranjero.
MooER tuvo un buen desempeño en pruebas comparativas de múltiples modelos grandes de comprensión de audio de código abierto bien conocidos, con una tasa de error de palabras en chino (CER) tan baja como 4,21% y una tasa de error de palabras en inglés (WER) del 17,98%, especialmente BLEU en chino. -Conjunto de pruebas de traducción al inglés con una puntuación de hasta 25,2, liderando otros modelos de código abierto. El modelo MooER-80k entrenado en base a 80.000 horas de datos tiene un rendimiento más sólido, con CER y WER reducidos al 3,50 % y 12,66 % respectivamente, lo que muestra un gran potencial. Este movimiento de Moore Thread no solo demuestra la gran fortaleza de las GPU nacionales en el campo de la IA, sino que también inyecta nueva vitalidad al desarrollo de la tecnología de IA de audio global. Se espera que MooER traiga más avances en el futuro.
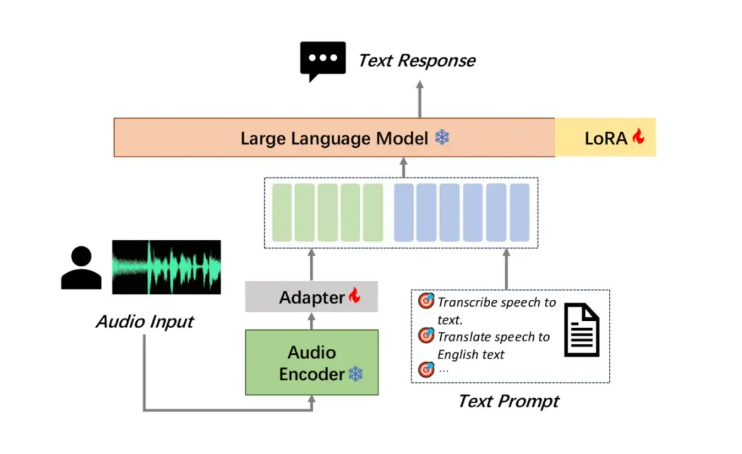
En pruebas comparativas con múltiples modelos grandes de comprensión de audio de código abierto conocidos, MooER-5K tuvo un desempeño excelente. En la prueba de chino, su tasa de error de palabras (CER) alcanzó el 4,21%; en la prueba de inglés, su tasa de error de palabras (WER) fue del 17,98%, que es mejor o equivalente a otros modelos superiores. Vale la pena mencionar especialmente que en el conjunto de pruebas de traducción chino-inglés de Covost2zh2en, la puntuación BLEU de MooER llega a 25,2, muy por delante de otros modelos de código abierto y alcanza un nivel comparable a las aplicaciones de nivel industrial.
Lo que es aún más emocionante es que el modelo MooER-80k entrenado en base a 80.000 horas de datos muestra un rendimiento más potente. El CER en el conjunto de pruebas chino cayó aún más al 3,50%, y el WER en el conjunto de pruebas en inglés también se optimizó a 12,66. % Muestra un enorme potencial de desarrollo.
MooER de código abierto de Moore Thread no solo demuestra la fuerza de las aplicaciones de las GPU nacionales en el campo de la IA, sino que también inyecta nueva vitalidad al desarrollo de la tecnología de IA de audio global. A medida que más datos y códigos de capacitación se vuelvan de código abierto, la industria espera que MooER aporte más avances en el reconocimiento de voz, la traducción y otros campos, y promueva la popularización y la aplicación innovadora de la tecnología de inteligencia artificial de audio.
Dirección: https://arxiv.org/pdf/2408.05101
El código abierto de MooER indica que las GPU nacionales han logrado avances significativos en el campo de los grandes modelos de IA, proporcionando valiosos recursos y plataformas para desarrolladores nacionales y extranjeros. Se espera que MooER pueda desempeñar un papel en más escenarios de aplicaciones en el futuro y promover la innovación y el desarrollo continuos de la tecnología de inteligencia artificial de audio.