Tencent Youtu Lab y otras instituciones han abierto el primer modelo de lenguaje grande multimodal VITA, que puede procesar videos, imágenes, texto y audio al mismo tiempo y brindar una experiencia interactiva fluida. La aparición de VITA tiene como objetivo compensar las deficiencias de los modelos lingüísticos a gran escala existentes en el procesamiento de dialectos chinos. Basado en el modelo Mixtral8×7B, se amplía el vocabulario chino y se afinan las instrucciones bilingües, haciéndolos competentes en inglés. y habla chino con fluidez. Esto marca un progreso significativo para la comunidad de código abierto en la comprensión e interacción multimodal.
Recientemente, investigadores de Tencent Youtu Lab y otras instituciones lanzaron el primer modelo de lenguaje grande multimodal de código abierto VITA, que puede procesar videos, imágenes, texto y audio al mismo tiempo, y su experiencia interactiva también es de primera clase.
El modelo VITA nació para cubrir las deficiencias de los grandes modelos lingüísticos en el procesamiento de dialectos chinos. Se basa en el potente modelo Mixtral8×7B, vocabulario chino ampliado e instrucciones bilingües perfeccionadas, lo que hace que VITA no solo domine el inglés, sino también el chino con fluidez.
Características principales:
Comprensión multimodal: la capacidad de VITA para procesar vídeo, imágenes, texto y audio no tiene precedentes entre los modelos de código abierto.
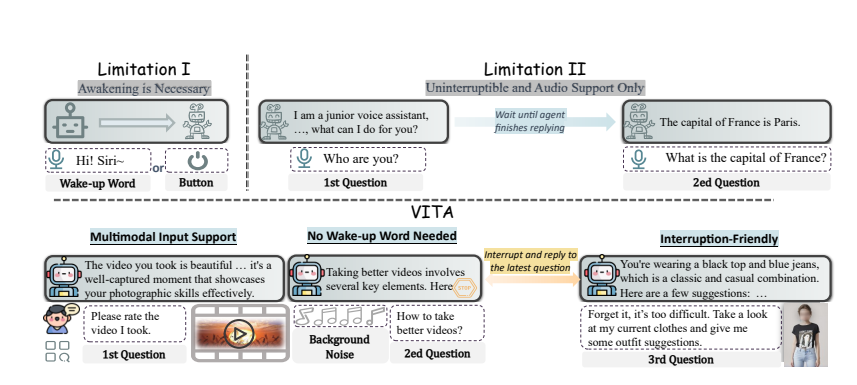
Interacción natural: no es necesario decir "Hola, VITA" cada vez, puede responder en cualquier momento cuando usted habla, e incluso cuando habla con otras personas, puede ser cortés y no interrumpir a voluntad.
Pionero del código abierto: VITA es un paso importante para la comunidad de código abierto en la comprensión e interacción multimodal, sentando las bases para investigaciones posteriores.
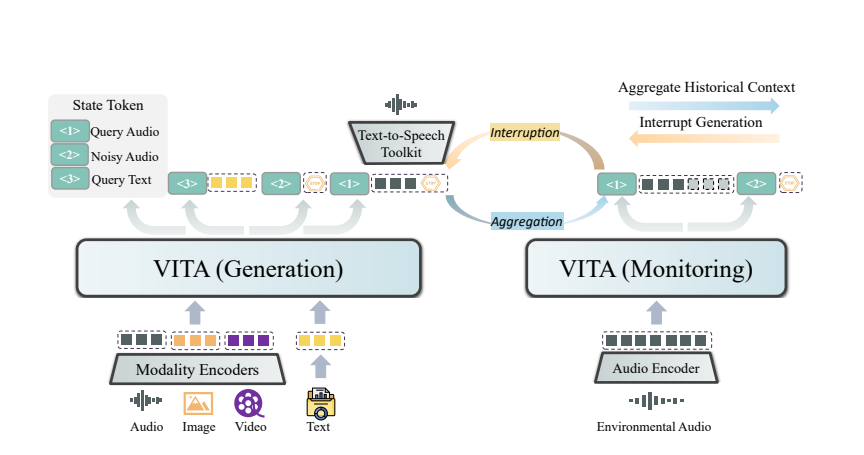
La magia de VITA proviene de su implementación de modelo dual. Un modelo es responsable de generar respuestas a las consultas de los usuarios y el otro modelo rastrea continuamente los aportes ambientales para garantizar que cada interacción sea precisa y oportuna.
VITA no sólo puede chatear, sino que también puede actuar como compañero de chat cuando hace ejercicio e incluso brindarle consejos cuando viaja. También puede responder preguntas basadas en las imágenes o el contenido de vídeo que proporciones, lo que demuestra su poderosa practicidad.
Aunque VITA ha demostrado un gran potencial, todavía está evolucionando en términos de síntesis emocional del habla y apoyo multimodal. Los investigadores planean permitir que la próxima generación de VITA genere audio de alta calidad a partir de entrada de video y texto, e incluso explorar la posibilidad de generar audio y video de alta calidad simultáneamente.
El código abierto del modelo VITA no es sólo una victoria técnica, sino también una profunda innovación en la forma de interacción inteligente. Con la profundización de la investigación, tenemos motivos para creer que VITA nos brindará una experiencia interactiva más inteligente y humana.
Dirección del artículo: https://arxiv.org/pdf/2408.05211
El código abierto de VITA proporciona una nueva dirección para el desarrollo de grandes modelos de lenguaje multimodal. Sus potentes funciones y su conveniente experiencia interactiva indican que la interacción entre humanos y computadoras será más inteligente y humana en el futuro. Esperamos que VITA logre mayores avances en el futuro y brinde más comodidad a la vida de las personas.