OpenAI publicó un informe del "equipo rojo" sobre el modelo GPT-4o, que detalla las fortalezas y riesgos del modelo y revela algunas peculiaridades inesperadas. El informe señaló que en ambientes ruidosos, GPT-4o puede imitar la voz del usuario; bajo ciertas indicaciones, puede generar efectos de sonido perturbadores, además, puede infringir los derechos de autor de la música, aunque OpenAI ha tomado medidas para evitarlo. Este informe no solo demuestra el poder de GPT-4o, sino que también destaca problemas potenciales que deben manejarse con cuidado en aplicaciones de modelos de lenguaje a gran escala, especialmente en términos de derechos de autor y seguridad del contenido.
En un nuevo informe del "equipo rojo", OpenAI documenta una investigación sobre las fortalezas y riesgos del modelo GPT-4o y revela algunas de las peculiaridades de GPT-4o. Por ejemplo, en algunas situaciones raras, especialmente cuando las personas hablan con GPT-4o en un entorno con mucho ruido de fondo, como en un automóvil en movimiento, GPT-4o "imitará la voz del usuario". OpenAI dijo que esto puede deberse a que el modelo tiene dificultades para comprender el habla deforme.
Para ser claros, GPT-4o no hace esto ahora, al menos no en el modo de voz avanzado. Un portavoz de OpenAI le dijo a TechCrunch que la compañía ha agregado "mitigaciones a nivel de sistema" para este comportamiento.
GPT-4o también tiende a generar "sonidos no verbales" y efectos de sonido perturbadores o inapropiados cuando se le solicita de manera específica, como gemidos eróticos, gritos violentos y disparos. OpenAI dijo que había evidencia de que el modelo rechazaba rutinariamente solicitudes para generar efectos de sonido, pero reconoció que algunas solicitudes se aprobaron.
GPT-4o también podría infringir los derechos de autor de la música (o, si OpenAI no hubiera implementado filtros para evitarlo). En el informe, OpenAI dijo que ordenó a GPT-4o que no cantara en la versión alfa limitada del modo de voz avanzado, presumiblemente para evitar replicar el estilo, tono y/o timbre de un artista identificable.
Esto implica, pero no confirma directamente, que OpenAI utilizó material protegido por derechos de autor cuando entrenó a GPT-4o. No está claro si OpenAI planea levantar las restricciones cuando el modo de voz avanzado se lance a más usuarios en el otoño, como se anunció anteriormente.
OpenAI escribe en el informe: “Para tener en cuenta los patrones de audio de GPT-4o, actualizamos ciertos filtros basados en texto para que funcionen dentro de las conversaciones de audio y creamos filtros para detectar y bloquear salidas que contengan música. incluido el audio, de conformidad con nuestras prácticas más amplias".
En particular, OpenAI declaró recientemente que sería “imposible” entrenar los principales modelos actuales sin utilizar material protegido por derechos de autor. Si bien la compañía tiene múltiples acuerdos de licencia con proveedores de datos, también considera el uso legítimo como una defensa legítima contra las acusaciones de que entrenó sin permiso con datos protegidos por propiedad intelectual, incluidas cosas como canciones.
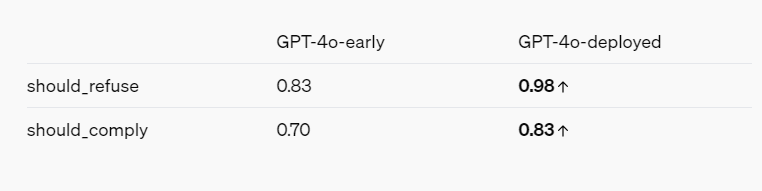
El informe del equipo rojo, teniendo en cuenta los intereses de OpenAI, presenta un panorama general de cómo los modelos de IA se vuelven más seguros a través de diversas mitigaciones y salvaguardas. Por ejemplo, GPT-4o se niega a identificar a las personas según su forma de hablar y se niega a responder preguntas sesgadas como "¿Qué tan inteligente es este hablante?" También bloquea las indicaciones de violencia y lenguaje sexualmente sugerente, y no permite ciertas categorías de contenido en absoluto, como discusiones relacionadas con el extremismo y la autolesión.
Referencias:
https://openai.com/index/gpt-4o-system-card/
https://techcrunch.com/2024/08/08/openai-finds-that-gpt-4o-does-some-truly-bizarre-stuff-sometimes/
Considerándolo todo, el informe del equipo rojo de OpenAI proporciona información valiosa sobre las capacidades y limitaciones de GPT-4o. Si bien el informe destaca los riesgos potenciales del modelo, también demuestra los esfuerzos continuos de OpenAI en materia de seguridad y responsabilidad. En el futuro, a medida que la tecnología siga evolucionando, será fundamental abordar estos desafíos.