Los modelos de lenguaje grande (LLM) enfrentan desafíos en la comprensión de textos largos y el tamaño de su ventana de contexto limita sus capacidades de procesamiento. Para resolver este problema, los investigadores desarrollaron la prueba de referencia LooGLE para evaluar la capacidad de comprensión de contexto a largo plazo de los LLM. LooGLE contiene 776 documentos ultralargos (promedio de 19,3 mil palabras) publicados después de 2022 y 6448 instancias de prueba, que cubren múltiples campos, con el objetivo de evaluar de manera más integral la capacidad del modelo para comprender y procesar textos largos. Este punto de referencia evalúa el desempeño de los LLM existentes y proporciona una referencia valiosa para el desarrollo de modelos futuros.
En el campo del procesamiento del lenguaje natural, la comprensión de contextos prolongados siempre ha sido un desafío. Aunque los modelos de lenguaje grandes (LLM) funcionan bien en una variedad de tareas lingüísticas, a menudo se ven limitados cuando procesan texto que excede el tamaño de su ventana de contexto. Para superar esta limitación, los investigadores han estado trabajando arduamente para mejorar la capacidad de los LLM para comprender textos largos, lo cual no solo es importante para la investigación académica, sino también para escenarios de aplicaciones del mundo real, como la comprensión del conocimiento de un dominio específico, la generación de diálogos, historias largas o generación de códigos, etc., también son cruciales.
En este estudio, los autores proponen una nueva prueba de referencia: LooGLE (Evaluación del lenguaje genérico de contexto largo), que está especialmente diseñada para evaluar la capacidad de comprensión del contexto largo de los LLM. Este punto de referencia contiene 776 documentos ultralargos después de 2022, cada documento contiene un promedio de 19,3 mil palabras y tiene 6448 instancias de prueba, que cubren múltiples campos, como académicos, historia, deportes, política, arte, eventos y entretenimiento, etc.
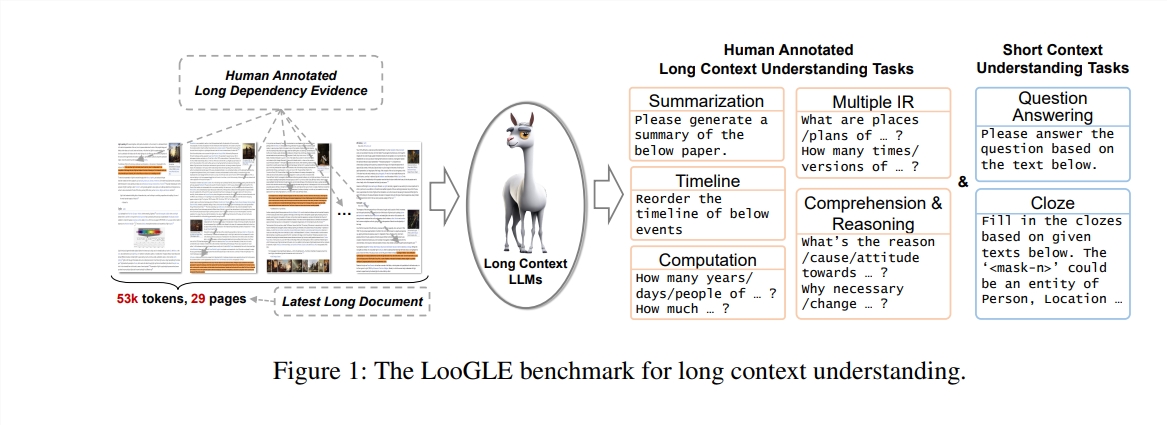
Características de LooGLE
Documentos reales ultralargos: la longitud de los documentos en ooGLE supera con creces el tamaño de la ventana de contexto de los LLM, lo que requiere que el modelo pueda recordar y comprender textos más largos.
Tareas de dependencia corta y larga diseñadas manualmente: la prueba de referencia contiene 7 tareas principales, incluidas tareas de dependencia corta y de dependencia larga, para evaluar la capacidad de los LLM para comprender el contenido de las dependencias largas y cortas.
Documentos relativamente novedosos: todos los documentos se publicaron después de 2022, lo que garantiza que la mayoría de los LLM modernos no hayan estado expuestos a estos documentos durante la capacitación previa, lo que permite una evaluación más precisa de sus capacidades de aprendizaje contextual.
Datos comunes entre dominios: los datos de referencia provienen de documentos populares de código abierto, como artículos de arXiv, artículos de Wikipedia, guiones de películas y televisión, etc.
Los investigadores realizaron una evaluación exhaustiva de ocho LLM de última generación y los resultados revelaron los siguientes hallazgos clave:
El modelo comercial supera en rendimiento al modelo de código abierto.
Los LLM se desempeñan bien en tareas de corta dependencia, pero presentan desafíos en tareas más complejas de larga dependencia.
Los métodos basados en el aprendizaje del contexto y las cadenas de pensamiento proporcionan sólo mejoras limitadas en la comprensión del contexto a largo plazo.
Las técnicas basadas en la recuperación muestran ventajas significativas en la respuesta a preguntas breves, mientras que las estrategias para ampliar la longitud de la ventana de contexto a través de una arquitectura Transformer optimizada o codificación posicional tienen un impacto limitado en la comprensión del contexto largo.
El punto de referencia LooGLE no solo proporciona un esquema de evaluación sistemático e integral para evaluar LLM de contexto largo, sino que también brinda orientación para el desarrollo futuro de modelos con capacidades de "verdadera comprensión de contexto largo". Todo el código de evaluación se ha publicado en GitHub para referencia y uso por parte de la comunidad de investigación.
Dirección del artículo: https://arxiv.org/pdf/2311.04939
Dirección del código: https://github.com/bigai-nlco/LooGLE
El punto de referencia LooGLE proporciona una herramienta importante para evaluar y mejorar las capacidades de comprensión de textos largos de los LLM, y los resultados de su investigación son de gran importancia para promover el desarrollo del campo del procesamiento del lenguaje natural. Las direcciones de mejora propuestas por los investigadores son dignas de atención. Creo que en el futuro aparecerán LLM cada vez más potentes para manejar mejor textos largos.