Apple y Meta AI lanzaron conjuntamente una nueva tecnología llamada LazyLLM, que está diseñada para mejorar significativamente la eficiencia de los modelos de lenguaje grandes (LLM) en el procesamiento del razonamiento de textos largos. Cuando el LLM actual procesa indicaciones largas, la complejidad computacional del mecanismo de atención aumenta con el cuadrado del número de tokens, lo que resulta en una velocidad lenta, especialmente en la etapa de precarga. LazyLLM selecciona dinámicamente tokens importantes para el cálculo, reduciendo efectivamente la cantidad de cálculos, e introduce el mecanismo Aux Cache para restaurar eficientemente los tokens eliminados, aumentando así en gran medida la velocidad y garantizando la precisión.
Recientemente, el equipo de investigación de Apple y los investigadores de Meta AI lanzaron conjuntamente una nueva tecnología llamada LazyLLM, que mejora la eficiencia de los modelos de lenguaje grandes (LLM) en el razonamiento de textos largos.
Como todos sabemos, el LLM actual a menudo enfrenta problemas de baja velocidad al procesar indicaciones largas, especialmente durante la etapa de precarga. Esto se debe principalmente a que la complejidad computacional de las arquitecturas de transformadores modernas al calcular la atención crece cuadráticamente con la cantidad de tokens en la pista. Por lo tanto, cuando se utiliza el modelo Llama2, el tiempo de cálculo del primer token suele ser 21 veces mayor que el de los pasos de decodificación posteriores, lo que representa el 23% del tiempo de generación.
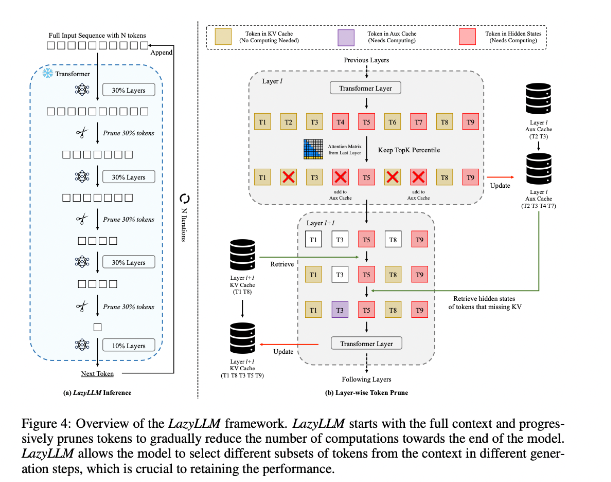
Para mejorar esta situación, los investigadores propusieron LazyLLM, que es un nuevo método para acelerar la inferencia de LLM seleccionando dinámicamente el método de cálculo de tokens importantes. El núcleo de LazyLLM es que evalúa la importancia de cada token en función del puntaje de atención de la capa anterior, reduciendo así gradualmente la cantidad de cálculo. A diferencia de la compresión permanente, LazyLLM puede restaurar tokens eliminados cuando sea necesario para garantizar la precisión del modelo. Además, LazyLLM introduce un mecanismo llamado Aux Cache, que puede almacenar el estado implícito de los tokens eliminados para restaurarlos de manera eficiente y evitar la degradación del rendimiento.
LazyLLM destaca en la velocidad de inferencia, especialmente en las etapas de prellenado y decodificación. Las tres ventajas principales de esta técnica son que es compatible con cualquier LLM basado en transformadores, no requiere reentrenamiento del modelo durante la implementación y se desempeña de manera muy efectiva en una variedad de tareas lingüísticas. La estrategia de poda dinámica de LazyLLM le permite reducir significativamente la cantidad de cálculo mientras retiene los tokens más importantes, aumentando así la velocidad de generación.
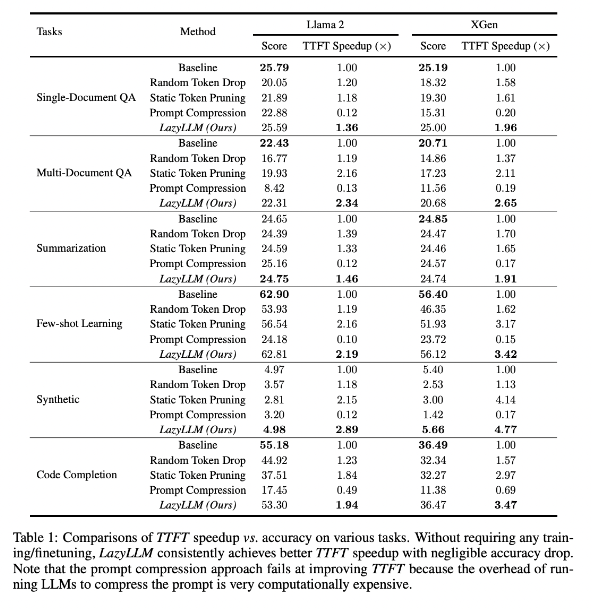
Los resultados de la investigación muestran que LazyLLM se desempeña bien en tareas de múltiples idiomas, con una velocidad TTFT aumentada 2,89 veces (para Llama2) y 4,77 veces (para XGen), mientras que la precisión es casi la misma que la línea base. Ya sea que se trate de tareas de respuesta a preguntas, generación de resúmenes o finalización de código, LazyLLM puede lograr una velocidad de generación más rápida y lograr un buen equilibrio entre rendimiento y velocidad. Su estrategia de poda progresiva junto con el análisis capa por capa sienta las bases del éxito de LazyLLM.
Dirección del artículo: https://arxiv.org/abs/2407.14057
Reflejos:
LazyLLM acelera el proceso de razonamiento de LLM seleccionando dinámicamente tokens importantes, especialmente en escenarios de textos largos.
Esta tecnología puede mejorar significativamente la velocidad de inferencia y la velocidad TTFT se puede aumentar hasta 4,77 veces, manteniendo una alta precisión.
LazyLLM no requiere modificaciones en los modelos existentes, es compatible con cualquier LLM basado en convertidor y es fácil de implementar.
Con todo, la aparición de LazyLLM proporciona nuevas ideas y soluciones efectivas para resolver el problema de la eficiencia del razonamiento de textos largos de LLM. Su excelente rendimiento en velocidad y precisión indica que desempeñará un papel importante en futuras aplicaciones de modelos grandes. Esta tecnología tiene amplias perspectivas de aplicación y vale la pena esperar su mayor desarrollo y aplicación.