Apple, junto con la Universidad de Washington y otras instituciones, lanzó un poderoso modelo de lenguaje llamado DCLM como código abierto, con un tamaño de parámetro de 700 millones y una asombrosa cantidad de datos de entrenamiento que alcanzan los 2,5 billones de tokens de datos. DCLM no es solo un modelo de lenguaje eficiente, sino que, lo que es más importante, proporciona una herramienta llamada "Competencia de conjuntos de datos" (DataComp) para optimizar el conjunto de datos del modelo de lenguaje. Esta innovación no solo mejora el rendimiento del modelo, sino que también proporciona nuevos métodos y estándares para la investigación de modelos de lenguaje, lo que merece atención.
Recientemente, el equipo de inteligencia artificial de Apple cooperó con muchas instituciones, como la Universidad de Washington, para lanzar un modelo de lenguaje de código abierto llamado DCLM. Este modelo tiene 700 millones de parámetros y utiliza hasta 2,5 billones de tokens de datos durante el entrenamiento para ayudarnos a comprender y generar mejor el lenguaje.
Entonces, ¿qué es un modelo de lenguaje? En pocas palabras, es un programa que puede analizar y generar lenguaje, ayudándonos a completar diversas tareas como traducción, generación de texto y análisis de sentimientos. Para que estos modelos funcionen mejor, necesitamos conjuntos de datos de calidad. Sin embargo, obtener y organizar estos datos no es una tarea fácil ya que necesitamos filtrar contenido irrelevante o dañino y eliminar información duplicada.
Para abordar este desafío, el equipo de investigación de Apple lanzó DataComp for Language Models (DCLM), una herramienta de optimización de conjuntos de datos para modelos de lenguaje. Recientemente abrieron el modelo DCIM y el conjunto de datos en la plataforma Hugging Face. Las versiones de código abierto incluyen DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 y dclm-baseline-1.0-parquet. Los investigadores pueden realizar una gran cantidad de experimentos a través de esta plataforma. y encuentre la mejor solución. Estrategias efectivas de manipulación de datos.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
La principal fortaleza de DCLM es su flujo de trabajo estructurado. Los investigadores pueden elegir modelos de diferentes tamaños según sus necesidades, desde 412 millones hasta 700 millones de parámetros, y también pueden experimentar con diferentes métodos de curación de datos, como la deduplicación y el filtrado. A través de estos experimentos sistemáticos, los investigadores pueden evaluar claramente la calidad de diferentes conjuntos de datos. Esto no solo sienta las bases para investigaciones futuras, sino que también nos ayuda a comprender cómo mejorar el rendimiento del modelo mejorando el conjunto de datos.
Por ejemplo, utilizando el conjunto de datos de referencia establecido por DCLM, el equipo de investigación entrenó un modelo de lenguaje con 700 millones de parámetros y logró una precisión de 5 disparos del 64% en la prueba de referencia MMLU. ¡Esto es una mejora de 6,6 en comparación con la anterior! puntos porcentuales más altos y utiliza un 40% menos de recursos informáticos. El rendimiento del modelo básico DCLM también es comparable al de Mistral-7B-v0.3 y Llama38B, que requieren muchos más recursos informáticos.
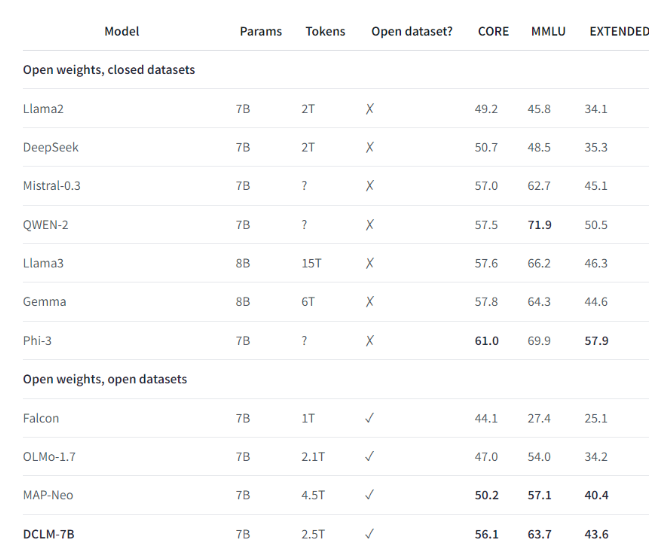
El lanzamiento de DCLM proporciona un nuevo punto de referencia para la investigación de modelos de lenguaje, ayudando a los científicos a mejorar sistemáticamente el rendimiento del modelo al tiempo que reduce los recursos informáticos necesarios.
Reflejos:
1️⃣ Apple AI cooperó con múltiples instituciones para lanzar DCLM, creando un poderoso modelo de lenguaje de código abierto.
2️⃣ DCLM proporciona herramientas estandarizadas de optimización de conjuntos de datos para ayudar a los investigadores a realizar experimentos eficaces.
3️⃣ El nuevo modelo logra avances significativos en pruebas importantes al tiempo que reduce los requisitos de recursos computacionales.
Con todo, el código abierto de DCLM ha inyectado nueva vitalidad en el campo de la investigación de modelos de lenguaje, y se espera que sus eficientes herramientas de optimización de modelos y conjuntos de datos promuevan un desarrollo más rápido en el campo y promuevan el nacimiento de modelos de lenguaje más poderosos y eficientes. En el futuro, esperamos que DCLM aporte resultados de investigación más sorprendentes.