El equipo de Alibaba Tongyi Qianwen lanzó la serie Qwen2 de modelos de código abierto. Esta serie incluye 5 tamaños de modelos de preentrenamiento y ajuste de instrucciones. La cantidad de parámetros y el rendimiento se han mejorado significativamente en comparación con la generación anterior Qwen1.5. La serie Qwen2 también ha logrado un gran avance en capacidades multilingües, admitiendo 27 idiomas además del inglés y el chino. En términos de comprensión del lenguaje natural, codificación, capacidades matemáticas, etc., el modelo grande (más de 70B parámetros) funciona bien, especialmente el modelo Qwen2-72B, que supera a la generación anterior en rendimiento y número de parámetros. Este lanzamiento marca una nueva altura en la tecnología de inteligencia artificial, brindando posibilidades más amplias para la aplicación y comercialización global de la IA.
Esta mañana temprano, el equipo de Alibaba Tongyi Qianwen lanzó la serie Qwen2 de modelos de código abierto. Esta serie de modelos incluye 5 tamaños de modelos previamente entrenados y ajustados con instrucciones: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B y Qwen2-72B. La información clave muestra que la cantidad de parámetros y el rendimiento de estos modelos han mejorado significativamente en comparación con la generación anterior Qwen1.5.
Para las capacidades multilingües del modelo, la serie Qwen2 ha invertido mucho esfuerzo en aumentar la cantidad y calidad del conjunto de datos, cubriendo otros 27 idiomas excepto inglés y chino. Después de las pruebas comparativas, el modelo grande (más de 70B parámetros) tuvo un buen desempeño en comprensión del lenguaje natural, codificación, capacidades matemáticas, etc. El modelo Qwen2-72B superó a la generación anterior en términos de rendimiento y número de parámetros.
El modelo Qwen2 no solo demuestra sólidas capacidades en la evaluación de modelos de lenguaje básico, sino que también logra resultados impresionantes en la evaluación de modelos de ajuste de instrucciones. Sus capacidades multilingües funcionan bien en pruebas comparativas como M-MMLU y MGSM, lo que demuestra el poderoso potencial del modelo de ajuste de instrucciones Qwen2.
Los modelos de la serie Qwen2 lanzados esta vez marcan una nueva altura en la tecnología de inteligencia artificial, brindando posibilidades más amplias para las aplicaciones y la comercialización globales de la IA. De cara al futuro, Qwen2 ampliará aún más la escala del modelo y las capacidades multimodales para acelerar el desarrollo del campo de la IA de código abierto.
Información del modeloLa serie Qwen2 incluye 5 tamaños de modelos básicos y optimizados por comando, incluidos Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B y Qwen2-72B. Explicamos la información clave de cada modelo en la siguiente tabla:
Modelo Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# Parámetro 049 millones 154 millones 707B57.41B72.71B# Parámetro no EMB 035 millones 131B598 millones 5632 millones 7021B La garantía de calidad es realmente realmente de verdadero vínculo incorporado verdadero verdadero falso falso falso falso contexto longitud 32 mil 32 mil 128 mil 64 mil 128 milEspecíficamente, en Qwen1.5, solo Qwen1.5-32B y Qwen1.5-110B usaban Atención de consultas grupales (GQA). Esta vez, aplicamos GQA para todos los tamaños de modelos para que disfruten de los beneficios de velocidades más rápidas y menor uso de memoria en la inferencia de modelos. Para modelos pequeños, preferimos aplicar incrustaciones vinculantes porque las incrustaciones grandes y dispersas representan una gran parte de los parámetros totales del modelo.
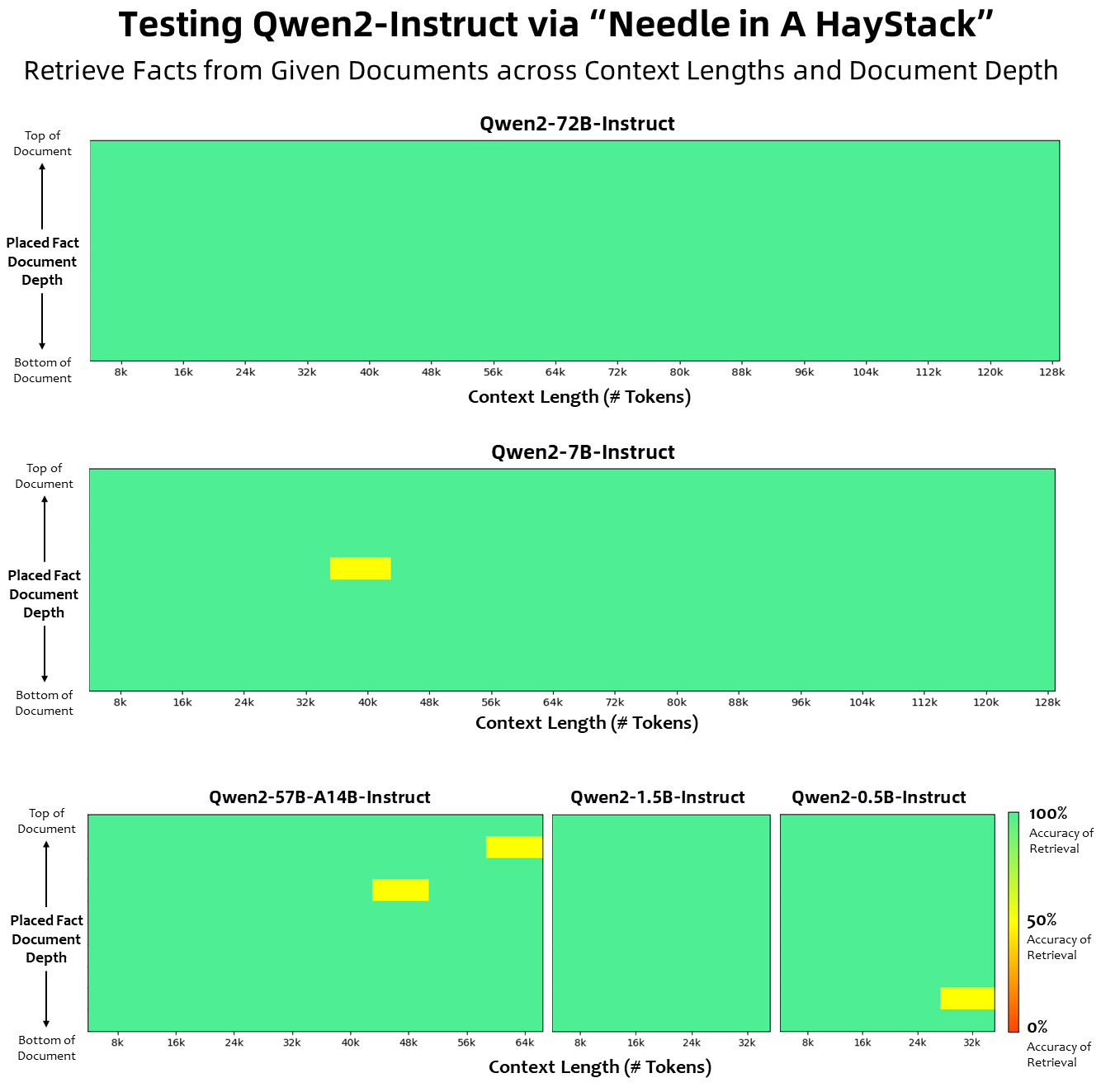
En términos de longitud del contexto, todos los modelos de lenguaje base se han entrenado previamente con datos de longitud de contexto de 32 000 tokens, y observamos capacidades de extrapolación satisfactorias hasta 128 000 en la evaluación PPL. Sin embargo, para los modelos ajustados a la instrucción, no estamos satisfechos solo con la evaluación de PPL, necesitamos que el modelo pueda comprender correctamente el contexto largo y completar la tarea. En la tabla, enumeramos las capacidades de longitud del contexto del modelo de ajuste de instrucciones, según lo evaluado mediante la evaluación de la tarea Needlein a Haystack. Vale la pena señalar que cuando se mejoran con YARN, tanto el modelo Qwen2-7B-Instruct como el Qwen2-72B-Instruct muestran capacidades impresionantes y pueden manejar longitudes de contexto de hasta 128 000 tokens.
Hemos realizado importantes esfuerzos para aumentar la cantidad y calidad de los conjuntos de datos ajustados a la instrucción y la capacitación previa que cubren varios idiomas además del inglés y el chino para mejorar sus capacidades multilingües. Aunque los modelos de lenguaje grandes tienen la capacidad inherente de generalizarse a otros lenguajes, enfatizamos explícitamente la inclusión de otros 27 lenguajes en nuestra capacitación:
Idiomas regionales Europa occidental Alemán, francés, español, portugués, italiano, holandés Europa oriental y central Ruso, checo, polaco Oriente Medio Árabe, persa, hebreo, turco Asia oriental Japonés, coreano Sudeste asiático Vietnamita, tailandés, indonesio, malayo, Lao, birmano, cebuano, jemer, tagalo hindi del sur de Asia, bengalí, urduAdemás, ponemos un gran esfuerzo en resolver los problemas de transcodificación que a menudo surgen en las evaluaciones multilingües. Por lo tanto, la capacidad de nuestro modelo para manejar este fenómeno mejora significativamente. Las evaluaciones que utilizan señales que normalmente provocan el cambio de código entre idiomas confirmaron una reducción significativa de los problemas relacionados.
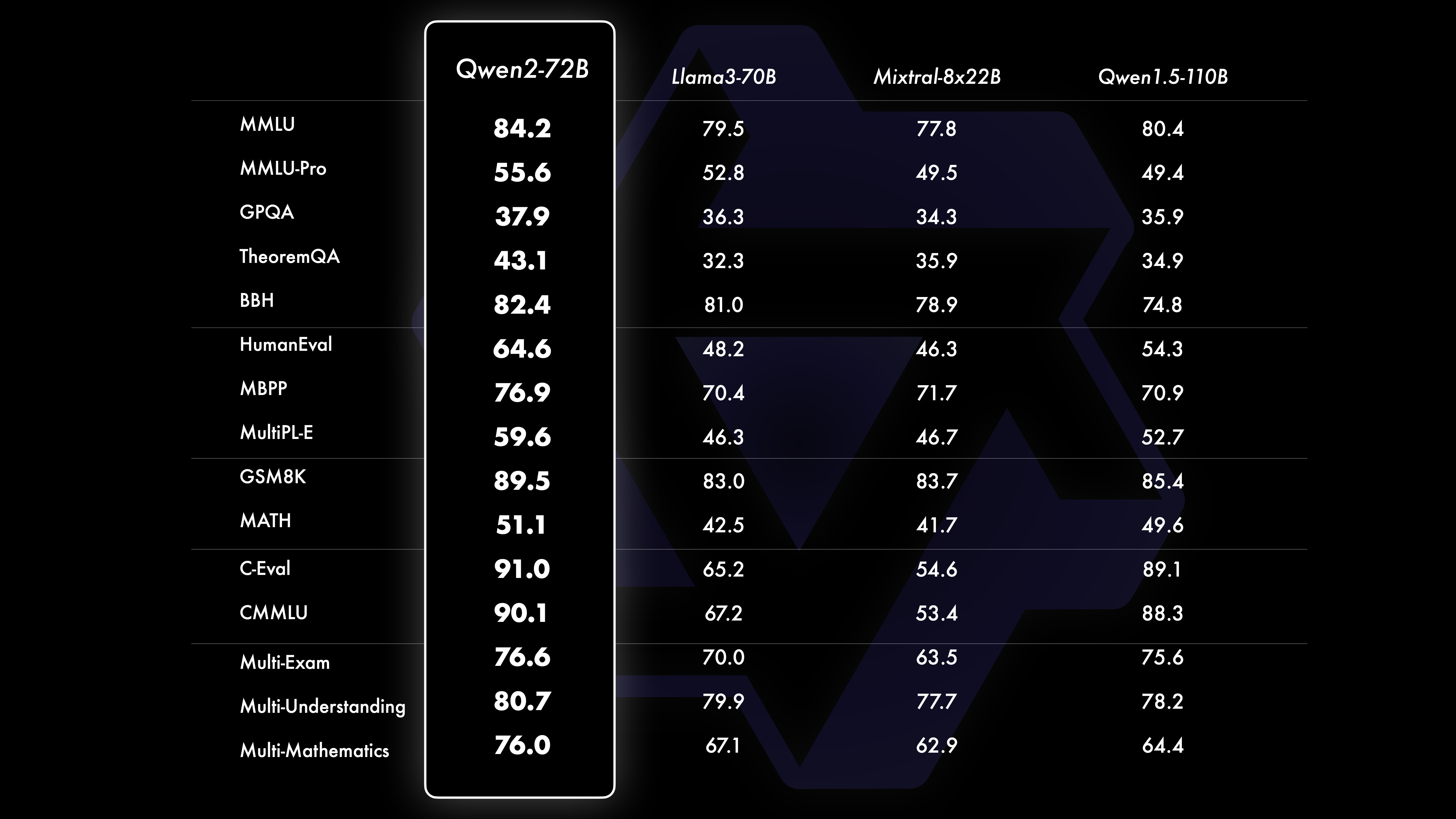
ActuaciónLos resultados de las pruebas comparativas muestran que el rendimiento del modelo a gran escala (más de 70 mil parámetros) ha mejorado significativamente en comparación con Qwen1.5. Esta prueba se centró en el modelo a gran escala Qwen2-72B. En términos de modelos de lenguaje básico, comparamos el rendimiento de Qwen2-72B y los mejores modelos abiertos actuales en términos de comprensión del lenguaje natural, adquisición de conocimientos, capacidades de programación, capacidades matemáticas, capacidades multilingües y otras capacidades. Gracias a conjuntos de datos cuidadosamente seleccionados y métodos de entrenamiento optimizados, Qwen2-72B supera a modelos líderes como Llama-3-70B, e incluso supera a la generación anterior Qwen1.5- con un número menor de parámetros.
Después de un extenso entrenamiento previo a gran escala, realizamos un entrenamiento posterior para mejorar aún más la inteligencia de Qwen y acercarlo a los humanos. Este proceso mejora aún más las capacidades del modelo en áreas como codificación, matemáticas, razonamiento, seguimiento de instrucciones y comprensión de varios idiomas. Además, alinea el resultado del modelo con los valores humanos, garantizando que sea útil, honesto e inofensivo. Nuestra fase posterior a la capacitación está diseñada con los principios de capacitación escalable y mínima anotación humana. Específicamente, estudiamos cómo obtener datos de presentación y datos de preferencia de alta calidad, confiables, diversos y creativos a través de varias estrategias de alineación automática, como muestreo de rechazo para matemáticas, retroalimentación de ejecución para codificación y seguimiento de instrucciones, y retrotraducción para escritura creativa. , supervisión escalable de juegos de rol y más. En cuanto a la capacitación, utilizamos una combinación de ajuste supervisado, capacitación en modelos de recompensa y capacitación en DPO en línea. También empleamos un novedoso optimizador de fusiones en línea para minimizar los impuestos de alineación. Estos esfuerzos combinados mejoran enormemente las capacidades y la inteligencia de nuestros modelos, como se muestra en la siguiente tabla.
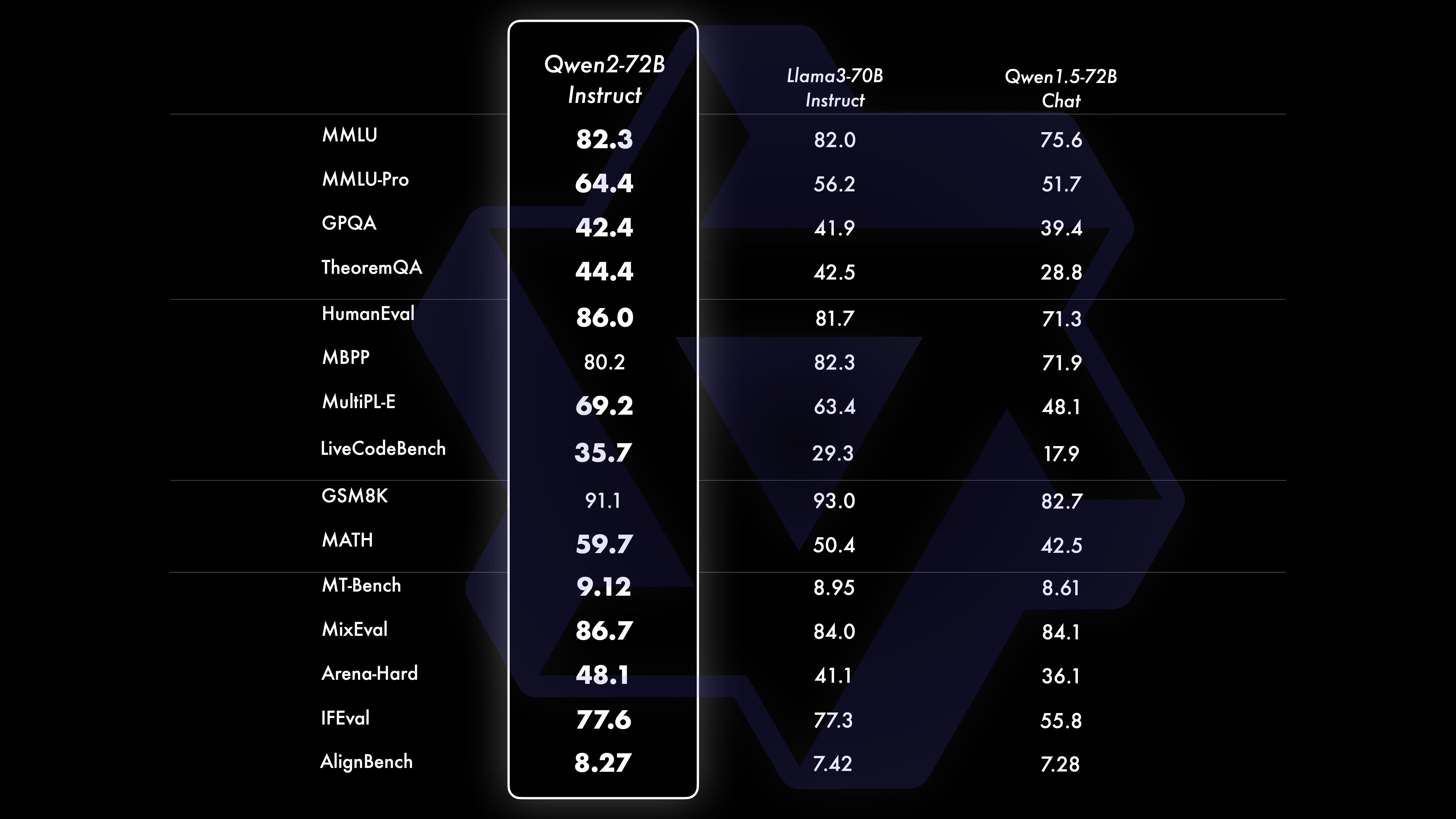
Realizamos una evaluación integral de Qwen2-72B-Instruct, que cubrió 16 puntos de referencia en varios campos. Qwen2-72B-Instruct logra un equilibrio entre adquirir mejores habilidades y ser coherente con los valores humanos. Específicamente, Qwen2-72B-Instruct supera significativamente a Qwen1.5-72B-Chat en todos los puntos de referencia y también logra un rendimiento competitivo en comparación con Llama-3-70B-Instruct.
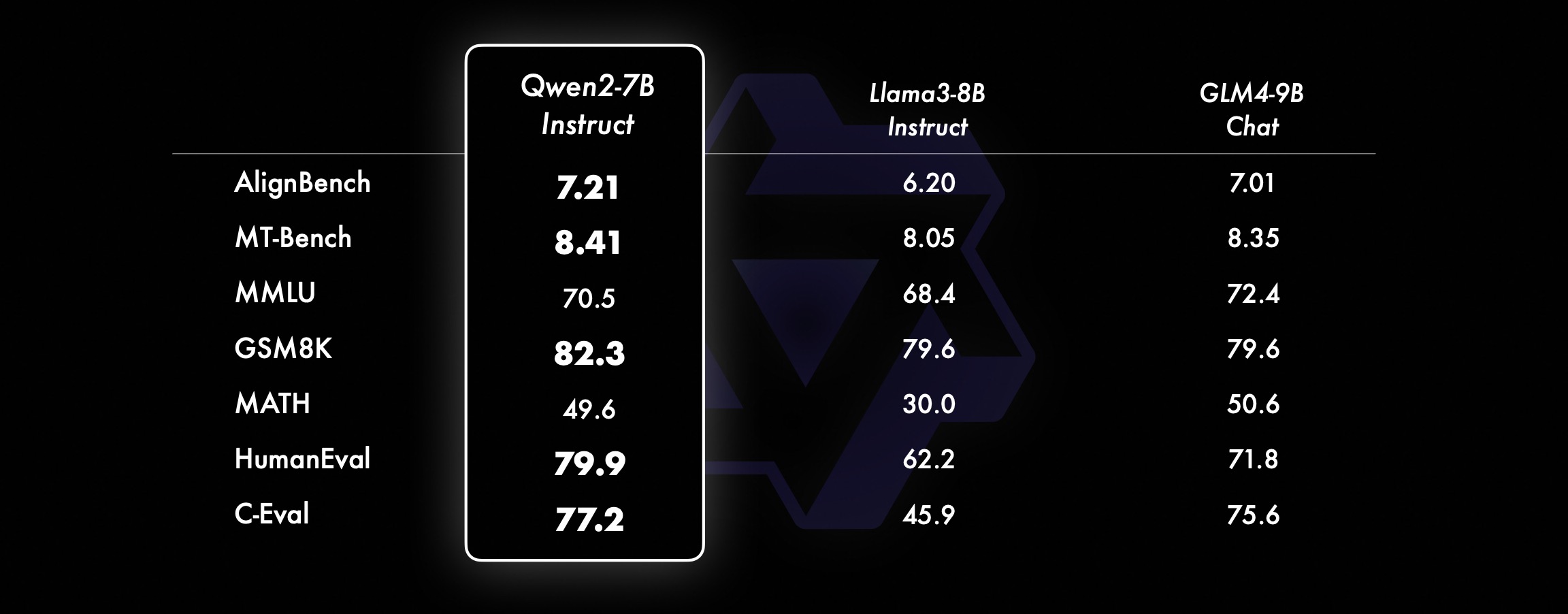
En modelos más pequeños, nuestros modelos Qwen2 también superan a los modelos SOTA similares e incluso de mayor tamaño. En comparación con el modelo SOTA recién lanzado, Qwen2-7B-Instruct todavía muestra ventajas en varias pruebas de referencia, especialmente en codificación e indicadores relacionados con el chino.
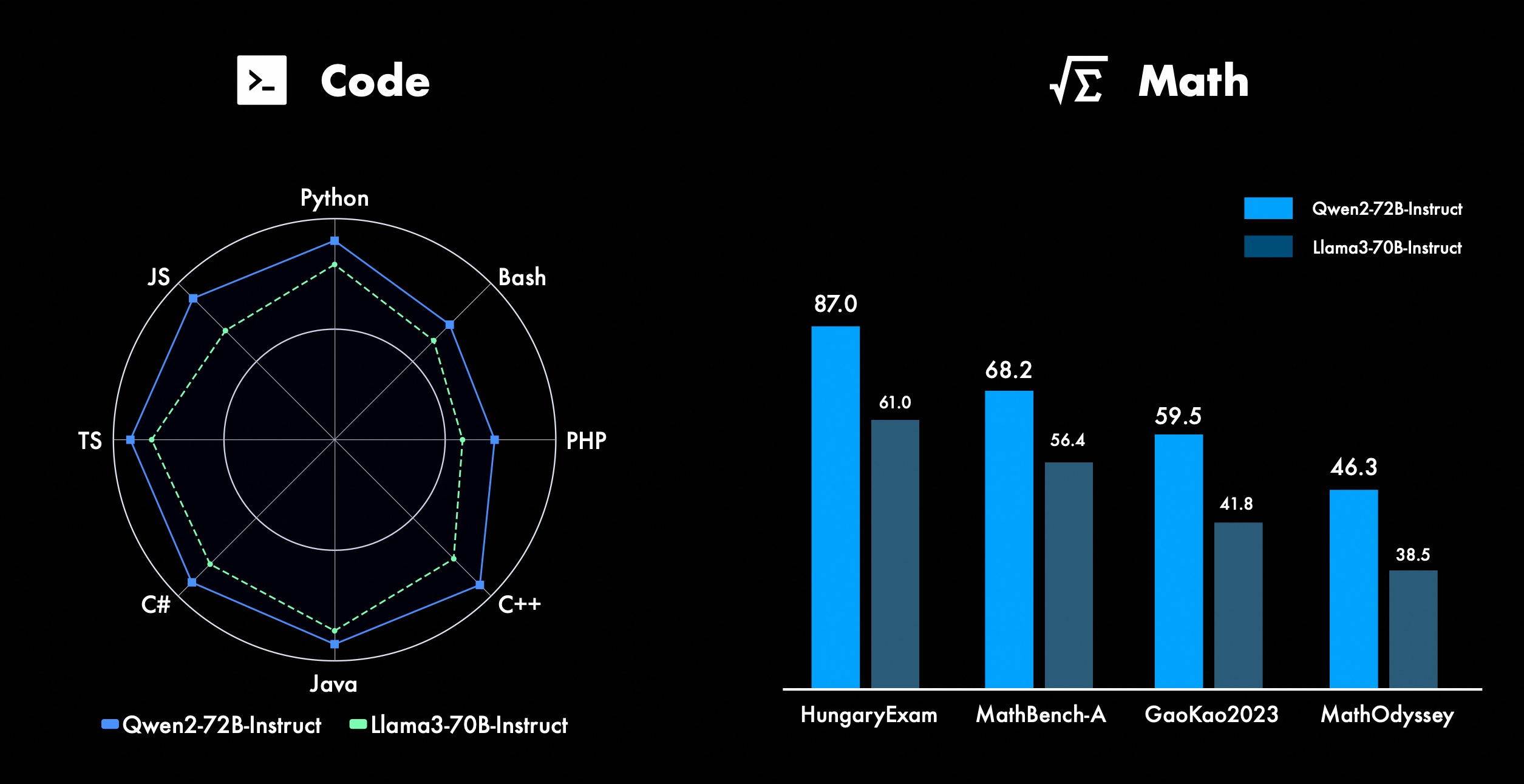
Trabajamos constantemente para mejorar las funciones avanzadas de Qwen, especialmente en codificación y matemáticas. En términos de codificación, integramos con éxito la experiencia de capacitación de código y los datos de CodeQwen1.5, lo que resultó en que Qwen2-72B-Instruct lograra mejoras significativas en varios lenguajes de programación. En matemáticas, Qwen2-72B-Instruct demuestra capacidades mejoradas para resolver problemas matemáticos aprovechando un conjunto de datos extenso y de alta calidad.
En Qwen2, todos los modelos de ajuste de instrucciones se entrenan en contextos de 32k de longitud y se extrapolan a contextos de mayor longitud utilizando técnicas como YARN o Dual Chunk Attention.
La siguiente imagen muestra los resultados de nuestra prueba en Needle in a Haystack. Vale la pena señalar que Qwen2-72B-Instruct puede manejar perfectamente la tarea de extracción de información en el contexto de 128k. Junto con su potente rendimiento inherente, se puede utilizar cuando los recursos son suficientes. En este caso, se convierte en la primera opción para procesar tareas de texto largas.
Además, cabe destacar las impresionantes capacidades de los otros modelos de la serie: el Qwen2-7B-Instruct maneja contextos de hasta 128k casi a la perfección, el Qwen2-57B-A14B-Instruct maneja contextos de hasta 64k y la serie The two Los modelos más pequeños admiten contextos de 32k.
Además del modelo de contexto largo, abrimos una solución proxy para el procesamiento eficiente de documentos que contienen hasta 1 millón de etiquetas. Para obtener más detalles, consulte nuestra publicación de blog dedicada a este tema.
La siguiente tabla muestra la proporción de respuestas dañinas generadas por un modelo grande para cuatro categorías de consultas multilingües inseguras (actividad ilegal, fraude, pornografía, violencia privada). Los datos de prueba provienen de Jailbreak y se traducen a varios idiomas para su evaluación. Descubrimos que Llama-3 no maneja señales multilingües de manera eficiente y, por lo tanto, no lo incluimos en la comparación. A través de la prueba de significancia (P_value), encontramos que el rendimiento de seguridad del modelo Qwen2-72B-Instruct es equivalente al de GPT-4 y significativamente mejor que el del modelo Mistral-8x22B.
Idioma Actividad ilegal Fraude Pornografía Privacidad Violencia GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chino0%13%0 %0%17%0%43%47%53%0%10%0%Inglés0%7%0%0%23% 0%37%67%63%0%27%3%Cuentas por cobrar0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%Francia0%3%0% 3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%punto0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%promedio0%8%0% 3%11%2%27%39%31%3%16%2% usan Qwen2 para desarrolloActualmente, todos los modelos se han lanzado en Hugging Face y ModelScope. Le invitamos a visitar la tarjeta del modelo para ver los métodos de uso detallados y obtener más información sobre las características, el rendimiento y otra información de cada modelo.
Durante mucho tiempo, muchos amigos han apoyado el desarrollo de Qwen, incluido el ajuste fino (Axolotl, Llama-Factory, Firefly, Swift, XTuner), la cuantificación (AutoGPTQ, AutoAWQ, Neural Compressor), la implementación (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), plataforma API (Together, Fireworks, OpenRouter), ejecución local (MLX, Llama.cpp, Ollama, LM Studio), agente y framework RAG (LlamaIndex, CrewAI, OpenDevin), evaluación (LMSys, OpenCompass, Open LLM Leaderboard), formación de modelos (Dolphin, Openbuddy), etc. Sobre cómo utilizar Qwen2 con marcos de terceros, consulte su documentación respectiva, así como nuestra documentación oficial.

Hay muchos equipos e individuos que han contribuido a Qwen y que no hemos mencionado. Agradecemos sinceramente su apoyo y esperamos que nuestra colaboración promueva la investigación y el desarrollo en la comunidad de IA de código abierto.
licenciaEsta vez, cambiamos el permiso del modelo por uno diferente. Qwen2-72B y su modelo de ajuste de instrucciones todavía usan la licencia Qianwen original, mientras que todos los demás modelos, incluidos Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B y Qwen2-57B-A14B, han cambiado a Apache2.0. Creemos que una mayor apertura de nuestro modelo a la comunidad puede acelerar la aplicación y comercialización de Qwen2 en todo el mundo.
¿Qué sigue para Qwen2?Estamos entrenando un modelo Qwen2 más grande para explorar más a fondo las extensiones del modelo, así como nuestras extensiones de datos recientes. Además, ampliamos el modelo de lenguaje Qwen2 para que sea multimodal, capaz de comprender información visual y de audio. En un futuro próximo, continuaremos abriendo nuevos modelos de código abierto para acelerar la IA de código abierto. ¡Manténganse al tanto!
CitaPronto publicaremos un informe técnico sobre Qwen2. ¡Bienvenidas las cotizaciones!
@article{qwen2, Apéndice Evaluación del modelo de lenguaje básicoLa evaluación de modelos básicos se centra principalmente en el rendimiento del modelo, como la comprensión del lenguaje natural, la respuesta a preguntas generales, la codificación, las matemáticas, el conocimiento científico, el razonamiento y las capacidades multilingües.
Los conjuntos de datos evaluados incluyen:
Tareas en inglés: MMLU (5 veces), MMLU-Pro (5 veces), GPQA (5 veces), Theorem QA (5 veces), BBH (3 veces), HellaSwag (10 veces), Winogrande (5 veces), TruthfulQA ( 0 veces), ARC-C (25 veces)
Tareas de codificación: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
Tareas de matemáticas: GSM8K (4 veces), MATH (4 veces)
Tareas chinas: C-Eval (5 disparos), CMMLU (5 disparos)
Tareas en varios idiomas: exámenes múltiples (M3Exam 5 veces, IndoMMLU 3 veces, ruMMLU 5 veces, mmMLU 5 veces), múltiples comprensiones (BELEBELE 5 veces, XCOPA 5 veces, XWinograd 5 veces, XStoryCloze 0 veces, PAWS-X 5 veces) , matemáticas múltiples (MGSM 8 veces), traducciones múltiples (Flores-1015 veces)
Conjunto de datos de rendimiento Qwen2-72B DeepSeek-V2Mixtral-8x22BCel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArquitecturaMinisterio de EducaciónDenseDenseDenseDenseDense#Parámetros activados 21B39B70B72B110B72B#Parámetros 236B140B70B72B 110B72B Inglés Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552. 845.849.455.6Garantía de calidad-34.336.336.335.937.9Teorema de preguntas y respuestas-35.932.329.334.943.1Baibihei 78.978.981.065.574.88 2.4 Shiraswag 87.888.788.086. 587.6 Ventanas grandes 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668.9 Preguntas y respuestas honestas 42.251.045.659.649.654.8 Evaluación de personal de codificación 45.746.348.246.354.364.6 Departamento de Servicio Público de Malasia 73 .971.770.466.970.976.9 Evaluación 55.054.154.852.957.765.4 Varios 44.446.746.341.852.759.6 Matemáticas GSM8K79. 283.783.079.585.489.5 Matemáticas 43.641.742.534.149.651.1 Evaluación C de chino 81.754.665 284.189.191.0 Universidad de Montreal, Canadá 84.053 .467.283.588.390.1 Múltiples idiomas y múltiples exámenes 67.563.570.066.475.676.6Múltiples entendimientos 77.077.779.978.278.280.7 Matemáticas múltiples 58.862.967.161.764.476.0 Traducciones múltiples 36.023.338.035.636.2 37.8 Qwen2-57B-A14B Conjunto de datos Jabba Mixtral-8x7B Instrument-1.5-34BQwen1.5-32B Qwen2-57B-A14B Arquitectura MoE MoE Denso Denso MoE #Parámetros activados 12B12B34B32B14B #Parámetros 52B47B34B32B57B Inglés Moleman Lu 67.471.877.174.376.5MMLU - Edición profesional - 41.048.344.043.0 Garantía de calidad - 29.2 - 30.834.3 Teorema Preguntas y respuestas - .2 - 28.833.5 Baibei Negro 45.450.376.466.867.0 Shiela Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 Preguntas y respuestas honestas 46.451.153.957.457.7 Evaluación de mano de obra de codificación 29.337.246.343.35 3.0 Servicio Público Malasia - 63.965.564.271.9 Evaluación - 46.451 .950.457.2 Varios - 39.03 9.538.549 .8 Matemáticas GSM8K59.962.582.776.880.7 Matemáticas-30.841.736.143.0 Evaluación C de chino---83.587.7 Universidad de Montreal, Canadá--84.882.388.5 Múltiples idiomas y exámenes múltiples-56.158.361.665.5 Comprensión multipartita -70.773.976.577.0Matemáticas múltiples -45.049.356.162.3Traducción múltiple -29.830.033.534.5Qwen2-7B Conjunto de datos Mistral -7B Jemma -7B Camel -3-8BQwen1.5 -7BQwen2-7B# Parámetros 7.2B850 millones 8.0B7.7B7.6B# Parámetros no embebidos 7.0B780 millones 7.0B650 millones 650 millones Inglés Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 Garantía de calidad 24.725 .725.826. 731.8 Teorema Preguntas y respuestas 19.221.522.114.231.1 Baibei Black 56.155.157.740.262.6 Shiraswager 83.282.282.178.580.7 Winogrand 78.479.077.471.377.0ARC-C60.061.159 .354.260.6Preguntas y respuestas honestas 42.244 .844.051.154.2 Evaluación de mano de obra de codificación 29.337.233.536 .051.2 Servicio público Malasia 51.150.653.951.665.9 Evaluación 36.439.640.340.054.2 Múltiple 29.429.722.628.146.3 Matemáticas GSM8K52.246.456.0 62.579.9 Matemáticas 13.124.320.520. 344.2 China Evaluación C humana 47.443.649.574.183.2 Université de Montréal , Canadá -- 50.873.183.9 Examen múltiple multilingüe 47.142.752.347.759.2 Comprensión múltiple 63.358.368.667.672.0 Matemáticas multivariadas 26.339.136.337.357.5 Traducción múltiple 23.331.231 .928.431.5Qwen2 - Conjunto de datos 0.5B y Qwen2-1.5B Phi-2Gemma -2B CPM mínimo Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# Parámetros no Emb 250 millones 2.0B2.4B1.3B035 millones 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 Teorema Preguntas y respuestas----8.915.0 Evaluación de mano de obra 47.622.050.020.122.031.1 Departamento de Servicios Públicos de Malasia 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 Matemáticas 3.511.810.210.110.72 1.7 Baibi Negro 43.435.236.924.228.437. 2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 Preguntas y respuestas honestas 44.533.1-39.439.745.9C - Evaluación 23.428.051 .159.758.270.6 Universidad de Montreal, Canadá 24.2 - 51.157.855.170.3 Evaluación del modelo de ajuste de instrucciones Qwen2-72B - Conjunto de datos guiado Camel - 3-70B - Guía Qwen1.5-72B - Chat Qwen2-72B - Guía Inglés Mohr Man Lu 82.075.682.3MMLU - Edición profesional 56.251. 764.4 Garantía de calidad 41.939.442.4 Preguntas y respuestas sobre teoremas 42.528.844.4MT - Bench8.958.619.12 Arena - Duro 41.136.148.1 IFEval (acceso estricto y rápido) 77.355.877.6 Evaluación de mano de obra de codificación 81.771.386.0 Servicio público Malasia 82. 371.980.2 Evaluación múltiple 63.448.169.2 75.266.979.0 Prueba de código en vivo 29.317.935.7 Matemáticas GSM 8K93.082.7 91.1 Matemáticas 50.442.559.7 Evaluación C china 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMixtral -8x7B-Instrucción-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - Arquitectura de orientación Ministerio de Educación Denso Denso Ministerio de Educación #Parámetro activado 12B34B32B14B #Parámetro 47B34B32B57B Inglés Mohr Man Lu 71.476.874.875.4MMLU - Edición profesional 43.352.346.452.8 Calidad Aseguramiento - 30.834.3 Preguntas y respuestas sobre teoremas - -30.933.1MT-Bench8.308.508.308.55 Evaluación de mano de obra de codificación 45.175.268.379.9 Servicio público Malasia 59.574.667.970.9 Varios --50.766.4 Evaluación 48.5-63.671.6 En vivo Prueba de código 12.3-15.225.5 Matemáticas GSM8K65.790.283.679.6 Matemáticas 30.750.142.449.1 C-Evaluación china-76.780.5AlignBench5.707.207.197.36qwen2-7B-Guide DataSet Camber -Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide English Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 Garantía de calidad 34.2--27.825.3 Teorema de preguntas y respuestas 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 Codificación humanitaria 62.266.571.846.379.9 Servicio público Malasia 67.9--48.967.2 Múltiple 48.5--27.259.1 Evaluación 60.9--44.870.3 Prueba de código en vivo 17.3-- 26. 6 Matemáticas GSM8K79.684.879.660.382.3 Matemáticas 30.047.750.623.249.6 Evaluación C de chino 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct y Qwen2-1.5B-Instruct Data establecer Qwen1. 0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 Evaluación de mano de obra 9.117.125.037.8GSM8K11.340.135.361.6C-Evaluación 37.245.255.36 3.8Valor IFE ( Solicite acceso estricto) El comando 14.620.016.829.0 ajusta las capacidades multilingües del modelo.Comparamos el modelo de ajuste de instrucciones Qwen2 con otros LLM recientes en varios puntos de referencia abiertos en varios idiomas, así como en la evaluación humana. Para la línea de base, presentamos resultados en 2 conjuntos de datos de evaluación:
M-MMLU de Okapi: evaluación multilingüe de conocimientos generales (utilizamos subconjuntos de ar, de, es, fr, it, nl, ru, uk, vi, zh para la evaluación) MGSM: para evaluaciones de alemán, inglés, español, francés y matemáticas en Idiomas japonés, ruso, tailandés, chino y brasileño.Los resultados se promedian en todos los idiomas para cada punto de referencia y son los siguientes:
M-MMLU ejemplar (5 disparos) MGSM (0 disparos, CoT) LLM patentado GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 comando LL.M de código abierto-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -Guía 60.057.0Qwen2-57B-A14B-Guía 68.074.0Qwen2-72B-Guía 78.086.6Para la evaluación manual, comparamos Qwen2-72B-Instruct con GPT3.5, GPT4 y Claude-3-Opus utilizando un conjunto de evaluación interno, que incluye 10 idiomas ar, es, fr, ko, th, vi, pt, id, ja y ru (rango de puntuación de 1 a 5):
Modelo Cuentas por Cobrar Español Francés Corri Seis Puntos ID Jiaru Promedio Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 4.324.09 GPT-4-Turbo- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-Guía 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 .943.873.833.953.553.773.063.633.71GPT-3.5-Turbo-11062.524. 073.472.373.382.903.373.562.753.243.16Agrupados por tipo de tarea, los resultados son los siguientes:
Modelo Conocimiento Comprensión Creación Matemáticas Claude-3-Works-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61GPT - 4-06133.424. 32GPT-3.5-Turbo-11063.373.673.892.97Estos resultados demuestran las poderosas capacidades multilingües del modelo de ajuste de instrucciones Qwen2.
Los modelos de la serie Qwen2 de código abierto de Alibaba han mejorado significativamente el rendimiento y las capacidades en varios idiomas, lo que supone una importante contribución a la comunidad de IA de código abierto. En el futuro, Qwen2 continuará desarrollando y ampliando aún más la escala del modelo y las capacidades multimodales, algo que vale la pena esperar.