Entrepôt de données analytiques Apache Kylin v4.0.3 version officielle
4.0.3
Apache Kylin : un outil de requête en moins d'une seconde pour des données à très grande échelle
Éditeur de downcodes
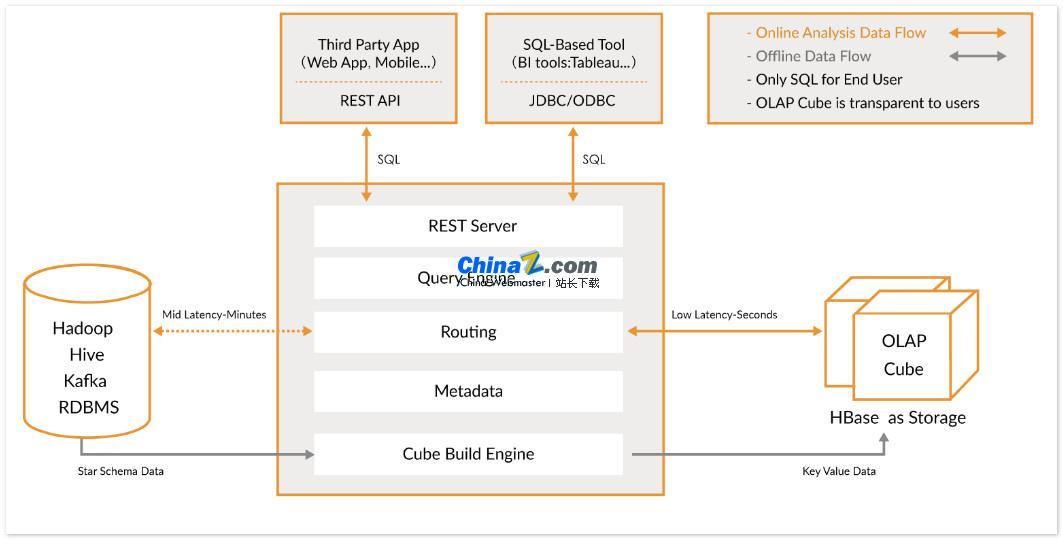
Apache Kylin est un entrepôt de données analytiques distribué et open source qui fournit une interface de requête SQL et des fonctionnalités d'analyse multidimensionnelle (OLAP) en plus de Hadoop/Spark, et peut traiter efficacement des données à très grande échelle. Développé à l'origine par eBay et contribué à la communauté open source, il répond à des requêtes sur des données massives en moins de quelques secondes.
Les trois grandes étapes de Kylin
Kylin permet aux utilisateurs de mettre en œuvre des requêtes en moins d'une seconde sur de très grands ensembles de données en seulement trois étapes :
1. Définissez un modèle en étoile ou en flocon de neige sur votre ensemble de données : Tout d'abord, vous devez définir un modèle en étoile ou en flocon de neige pour décrire votre ensemble de données. Cela aidera Kylin à comprendre la relation entre les données et ainsi à optimiser les performances des requêtes.
2. Build Cube : Build Cube sur la table de données définie. Cube est l'unité permettant à Kylin de précalculer et de stocker les données, ce qui peut considérablement améliorer la vitesse des requêtes.
3. Utilisez une requête SQL standard : utilisez la syntaxe SQL standard pour interroger Cube via l'API ODBC, JDBC ou RESTFUL. Kylin peut renvoyer les résultats de la requête en quelques secondes.
Capacités d'intégration de Kylin
Kylin s'intègre à une variété d'outils de visualisation de données, tels que Tableau, Power BI, etc. Les utilisateurs peuvent utiliser ces outils BI pour analyser les données Hadoop et afficher visuellement des informations sur les données.
Résumer
Apache Kylin est un outil puissant qui peut aider les utilisateurs à effectuer des requêtes sur des données à très grande échelle en quelques secondes. Sa facilité d'utilisation, son évolutivité et son efficacité le rendent idéal pour gérer l'analyse de données à grande échelle.