détecteur de langue efficace
3.0.0
Le détecteur de langage efficace ( Nito-ELD ou ELD ) est un logiciel de détection de langage naturel rapide et précis, écrit à 100 % en PHP, avec une vitesse comparable aux détecteurs rapides compilés en C++ et une précision dans la gamme des meilleurs détecteurs à ce jour.
Il n'a pas de dépendances, une installation facile, tout ce dont il a besoin est PHP avec l'extension mb .
ELD est également disponible (versions obsolètes) en Javascript et Python.
Installation
Comment utiliser
Repères
Bases de données
Essai
Langues
Modifications de ELD v2 à v3 :
détecter()->langue renvoie désormais la chaîne
'und'pour indéterminé au lieu deNULLLes bases de données ne sont pas compatibles et plus grandes, moyennes v2 ≈ petites v3
La fonction DynamicLangSubset() est supprimée
La fonction cleanText() s'appelle désormais activateTextCleanup()
$ composer nécessite nitotm/efficace-lingual-detector
--prefer-dist omettra tests/ , misc/ & benchmark/ , ou utilisera --prefer-source pour tout inclure
Installez nitotm/efficient-language-detector:dev-main pour essayer les dernières modifications instables
Alternativement, télécharger/cloner les fichiers peut très bien fonctionner.
(Seule petite installation de base de données en construction)
Il est recommandé d'utiliser OPcache, spécialement pour les bases de données plus volumineuses, afin de réduire les temps de chargement.
Nous devons définir opcache.interned_strings_buffer , opcache.memory_consumption suffisamment haut pour chaque base de données
Valeur recommandée entre parenthèses. Vérifiez les bases de données pour plus d'informations.
| paramètre php.ini | Petit | Moyen | Grand | Très grand |
|---|---|---|---|---|
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
detect() attend une chaîne UTF-8 et renvoie un objet avec une propriété language , contenant un code ISO 639-1 (ou autre format sélectionné), ou 'und' pour un langage indéterminé.
// require_once 'manual_loader.php'; Pour charger ELD sans chargeur automatique. Mettre à jour path.use NitotmEld{LanguageDetector, EldDataFile, EldFormat};// LanguageDetector(databaseFile : ?string, outputFormat : ?string)$eld = new LanguageDetector(EldDataFile::SMALL, EldFormat::ISO639_1);// Fichiers de base de données : ' petit », « moyen », « grand », « extralarge ». Vérifiez les besoins en mémoire// Formats : 'ISO639_1', 'ISO639_2T', 'ISO639_1_BCP47', 'ISO639_2T_BCP47' et 'FULL_TEXT'// Les constantes ne sont pas obligatoires, LanguageDetector('small', 'ISO639_1'); fonctionnera également$eld->detect('Hola, cómo te llamas?');// object( language => string, scores() => array, isReliable() => bool )// ( langage => 'es', scores() => ['es' => 0,25, 'nl' => 0,05], isReliable() => true )$eld->detect('Hola, comment te llamas ?') ->langue;// 'es' Appeler langSubset() une fois définira le sous-ensemble. Le premier appel prend plus de temps car il crée une nouvelle base de données, si vous enregistrez le fichier de base de données (par défaut), il sera chargé la prochaine fois que nous créerons le même sous-ensemble.
Pour utiliser un sous-ensemble sans surcharge supplémentaire, la bonne méthode consiste à instancier le détecteur avec le fichier enregistré et renvoyé par langSubset() . Vérifiez les langues disponibles ci-dessous.
// Il accepte toujours les codes ISO 639-1, ainsi que le format de sortie sélectionné s'il est différent.// langSubset(langues : [], save : true, encode : true); Renvoie le nom du fichier du sous-ensemble s'il est enregistré$eld->langSubset(['en', 'es', 'fr', 'it', 'nl', 'de']);// Object ( success => bool, langues => ?array, error => ?string, file => ?string )// ( success => true, langues => ['en', 'es'...], error => NULL, file => ' small_6_mfss...' )// pour supprimer le sous-ensemble$eld->langSubset();// Le moyen le meilleur et le plus rapide d'utiliser un sous-ensemble est de le charger comme une base de données par défaut$eld_subset = new NitotmEldLanguageDetector('small_6_mfss5z1t' );// si activateTextCleanup(True), detector() supprime les URL, les domaines .com, les e-mails, les caractères alphanumériques...// Non recommandé, car les URL et les domaines contiennent des indices sur une langue, ce qui pourrait aider à la précision$eld->enableTextCleanup(true ); // La valeur par défaut est false// Si nécessaire, nous pouvons obtenir des informations sur l'instance ELD : langues, type de base de données, etc.$eld->info();
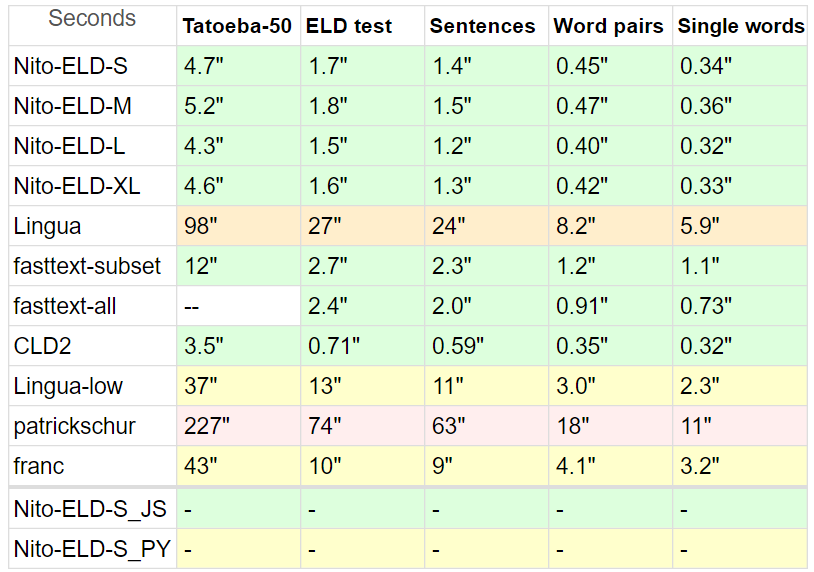
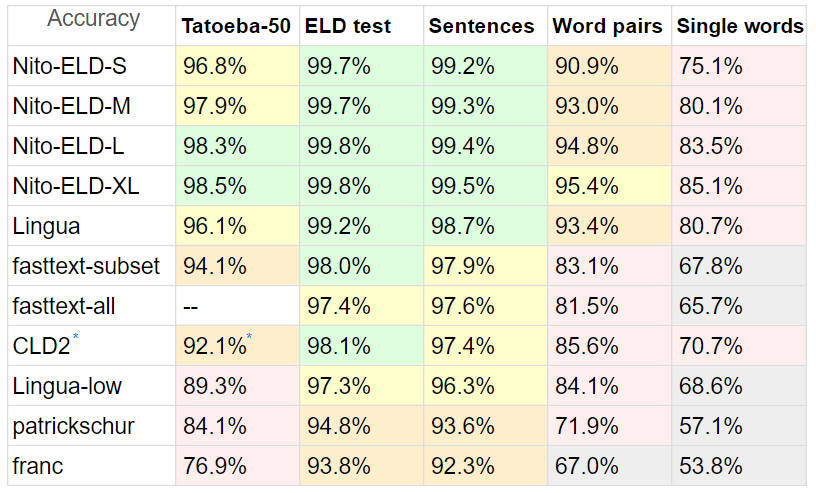
J'ai comparé ELD avec une autre variété de détecteurs, car il n'y en a pas beaucoup en PHP.
| URL | Version | Langue |
|---|---|---|
| https://github.com/nitotm/efficient-lingual-detector/ | 3.0.0 | PHP |
| https://github.com/pemistahl/lingua-py | 2.0.2 | Python |
| https://github.com/facebookresearch/fastText | 0.9.2 | C++ |
| https://github.com/CLD2Owners/cld2 | 21 août 2015 | C++ |
| https://github.com/patrickschur/langue-detection | 5.3.0 | PHP |
| https://github.com/wooorm/franc | 7.2.0 | Javascript |
Repères :
Tatoeba : 20 Mo , phrases courtes de Tatoeba, 50 langues prises en charge par tous les concurrents, jusqu'à 10 000 lignes chacune.
Pour Tatoeba, j'ai limité tous les détecteurs au sous-ensemble de 50 langues, rendant la comparaison aussi équitable que possible.
De plus, Tatoeba ne fait pas partie de l'ensemble de données de formation ELD (ni de réglage), mais c'est pour fasttext
Test ELD : 10 Mo , phrases des 60 langues prises en charge par ELD, 1000 lignes chacune. Extrait des 60 Go de données de formation ELD.
Phrases : 8 Mo , phrases du benchmark Lingua , moins les langues non prises en charge et le yoruba qui comportaient des caractères brisés.
Paires de mots 1,5 Mo et mots simples 870 Ko , également de Lingua, mêmes 53 langues.


Lingua participe avec 54 langues, le franc avec 58, le patrickschur avec 54.
fasttext n'a pas d'option de sous-ensemble intégrée, donc pour montrer son potentiel de précision et de vitesse, j'ai fait deux tests, fasttext - tous n'étant limités par aucun sous-ensemble à aucun test
* Le CLD2 de Google ne dispose pas non plus d'une option de sous-ensemble, et il est difficile de créer un sous-ensemble même avec son option bestEffort = True , car elle ne renvoie généralement qu'une seule langue, ce qui présente un désavantage comparatif.
Le temps est normalisé : (total des lignes * temps) / lignes traitées
| Petit | Moyen | Grand | Très grand | |
|---|---|---|---|---|
| Avantages | Mémoire la plus basse | Equilibré | Le plus rapide | Le plus précis |
| Inconvénients | Le moins précis | Le plus lent (mais rapide) | Mémoire élevée | Mémoire la plus élevée |
| Taille du fichier | 3 Mo | 10 Mo | 32 Mo | 71 Mo |
| Utilisation de la mémoire | 76 Mo | 280 Mo | 977 Mo | 2083 Mo |
| Utilisation de la mémoire | 0,4 Mo + OP | 0,4 Mo + OP | 0,4 Mo + OP | 0,4 Mo + OP |
| OPcache a utilisé la mémoire | 21 Mo | 69 Mo | 244 Mo | 539 Mo |
| OPcache utilisé en interne | 4 Mo | 10 Mo | 45 Mo | 98 Mo |
| Temps de chargement non mis en cache | 0,14 s | 0,5 seconde | 1,5 seconde | 3,4 secondes |
| Temps de chargement En cache | 0,0002 s | 0,0002 s | 0,0002 s | 0,0002 s |
| Paramètres (recommandés) | ||||
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... * | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
* Je recommande d'utiliser plus que suffisamment interned_strings_buffer car une erreur de dépassement de tampon pourrait retarder la réponse du serveur.
Pour utiliser toutes les bases de données, opcache.interned_strings_buffer doit être au minimum de 160 Mo (170 Mo).
Lorsque vous choisissez la quantité de mémoire, gardez à l'esprit opcache.memory_consumption inclut opcache.interned_strings_buffer .
Si la mémoire OPcache est de 230 Mo, interned_strings est de 32 Mo et la base de données moyenne est de 69 Mo en cache, nous avons un total de (230 -32 -69) = 129 Mo d'OPcache pour tout le reste.
De plus, si vous envisagez d'utiliser un sous-ensemble de langues en plus de la base de données principale, ou plusieurs sous-ensembles, augmentez opcache.memory en conséquence si vous souhaitez qu'ils soient chargés instantanément. Pour mettre en cache confortablement toutes les bases de données par défaut, vous souhaiterez la définir sur 1 200 Mo.
L'installation par défaut du compositeur peut ne pas inclure ces fichiers. Utilisez --prefer-source pour les inclure.
Pour l'environnement de développement avec composer "autoload-dev" (root uniquement), ce qui suit exécutera les tests
nouveau NitotmEldTestsTestsAutoload();
Ou, vous pouvez également exécuter les tests en exécutant le fichier suivant :
$ php efficient-lingual-detector/tests/tests.php # Chemin de mise à jour
Pour exécuter les tests de précision, exécutez le fichier benchmark/bench.php .
Ce sont les codes ISO 639-1 qui incluent les 60 langues. Plus 'und' pour indéterminé
Il s'agit du format de langage ELD par défaut. outputFormat: 'ISO639_1'
suis, ar, az, être, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, il, salut, hr, hu, hy, est, il, ja, ka, kn, ko, ku, lo, lt, lv, ml, mr, ms, nl, non, ou, pa, pl, pt, ro, ru, sk, sl, sq, sr, sv, ta, te, th, tl, tr, royaume-uni, ur, vi, yo, zh
Ce sont les 60 langues prises en charge pour Nito-ELD . outputFormat: 'FULL_TEXT'
Amharique, arabe, azerbaïdjanais (latin), biélorusse, bulgare, bengali, catalan, tchèque, danois, allemand, grec, anglais, espagnol, estonien, basque, persan, finnois, français, gujarati, hébreu, hindi, croate, hongrois, arménien , islandais, italien, japonais, géorgien, kannada, coréen, kurde (arabe), laotien, lituanien, letton, malayalam, marathi, malais (latin), néerlandais, norvégien, oriya, punjabi, polonais, portugais, roumain, russe, slovaque , slovène, albanais, serbe (cyrillique), suédois, tamoul, telugu, thaï, tagalog, turc, ukrainien, ourdou, vietnamien, yoruba, chinois
Codes ISO 639-1 avec balise de nom de script IETF BCP 47. outputFormat: 'ISO639_1_BCP47'
am, ar, az-Latn, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, est, il, ja, ka, kn, ko, ku-arabe, lo, lt, lv, ml, mr, ms-Latn, nl, non, ou, pa, pl, pt, ro, ru, sk, sl, sq, sr-Cyrl, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
Codes ISO 639-2/T (qui sont également valables 639-3 ) outputFormat: 'ISO639_2T' . Également disponible avec BCP 47 ISO639_2T_BCP47
amh, ara, aze, bel, bul, ben, chat, ces, dan, deu, ell, eng, spa, est, eus, fas, fin, fra, guj, heb, hin, hrv, hun, hye, isl, ita, jpn, kat, kan, kor, kur, lao, lit, lav, mal, mar, msa, nld, nor, ori, pan, pol, por, ron, rus, slk, slv, sqi, srp, swe, tam, tel, tha, tgl, tur, ukr, urd, vie, yor, zho
Si vous souhaitez faire un don pour des améliorations open source, m'embaucher pour des modifications privées, demander une formation alternative sur les ensembles de données ou me contacter, veuillez utiliser le lien suivant : https://linktr.ee/nitotm