Page du projet | Papier | Carte modèle ?
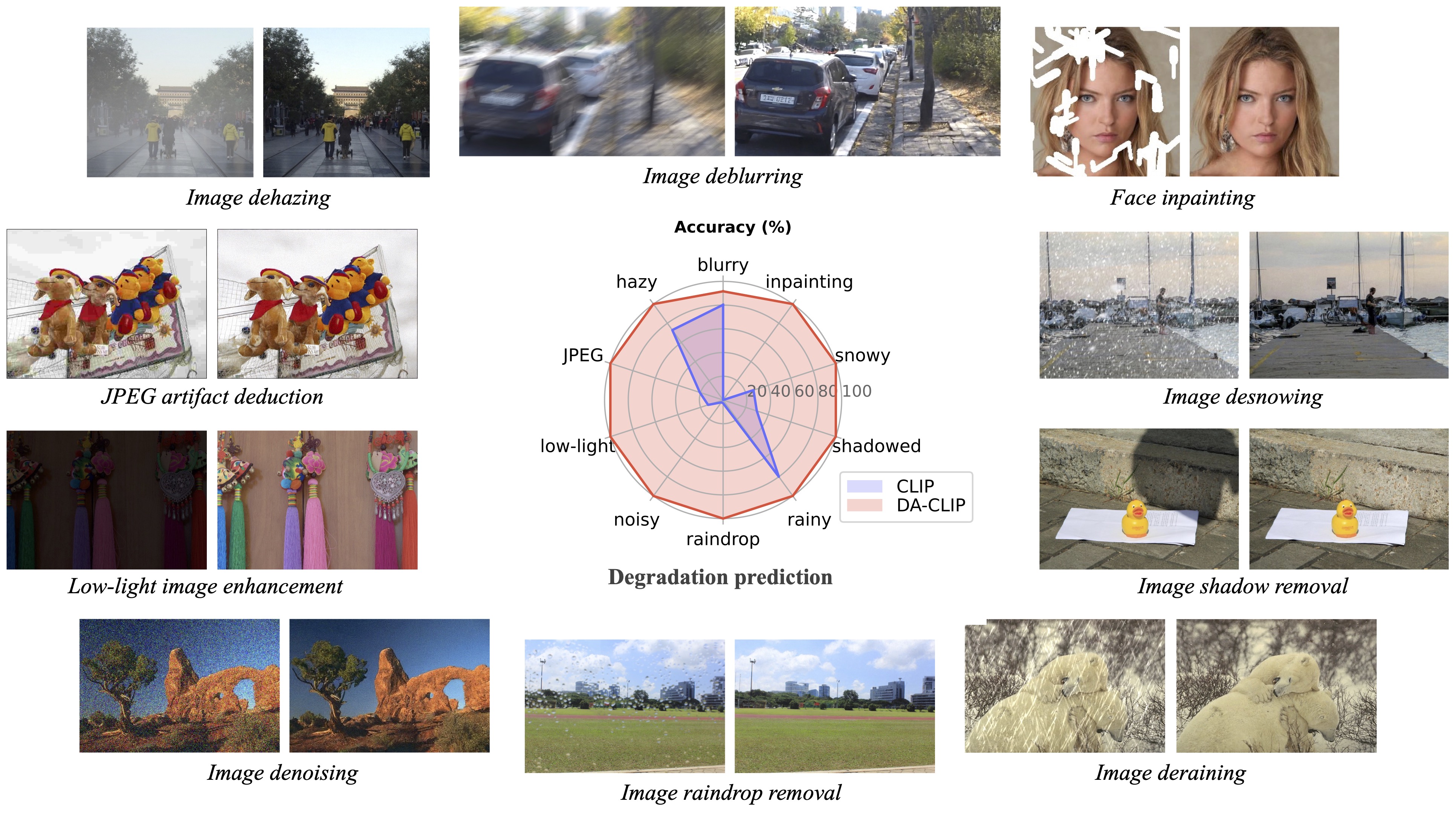
Notre travail de suivi Restauration d'images photo-réalistes dans la nature avec des modèles de langage de vision contrôlés (CVPRW 2024) présente un échantillonnage postérieur pour une meilleure génération d'images et gère des images à dégradation mixte du monde réel similaires à Real-ESRGAN.
[ 2024.04.16 ] Notre article de suivi « Restauration d'images photo-réalistes dans la nature avec des modèles de langage de vision contrôlés » est maintenant sur ArXiv !
[ 2024.04.15 ] Mise à jour d'un modèle IR sauvage pour les dégradations du monde réel et l'échantillonnage postérieur pour une meilleure génération d'images. Les poids pré-entraînés wild-ir.pth et wild-daclip_ViT-L-14.pt sont également fournis pour wild-ir.
[ 20/01/2024 ] ??? Notre article DA-CLIP a été accepté par l'ICLR 2024 ??? Nous proposons en outre un modèle plus robuste dans la fiche modèle.
[ 2023.10.25 ] Ajout de liens d'ensembles de données pour la formation et les tests.
[ 2023.10.13 ] Ajout de la démo et de l'API Replicate. Merci à @chenxwh !!! Nous avons mis à jour la démo Hugging Face et la démo Colab en ligne. Merci à @fffiloni et @camenduru !!! Nous avons également réalisé une carte modèle en Hugging Face ? et a fourni plus d'exemples pour les tests.
[ 2023.10.09 ] Les poids pré-entraînés de DA-CLIP et du modèle Universal IR sont publiés respectivement dans lien1 et lien2. De plus, nous fournissons également un fichier d'application Gradio pour le cas où vous souhaitez tester vos propres images.
Système d'exploitation : Ubuntu 20.04
nvidia :
cuda : 11,4
python 3.8
Nous vous conseillons dans un premier temps de créer un environnement virtuel avec :
python3 -m venv .envsource .env/bin/activate pip installer -U pip pip install -r exigences.txt
Accédez au répertoire universal-image-restoration et exécutez :
import torchfrom PIL import Imageimport open_clipcheckpoint = 'pretrained/daclip_ViT-B-32.pt'model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)tokenizer = open_clip.get_tokenizer('ViT-B-32 ')image = preprocess(Image.open("haze_01.png")).unsqueeze(0)degradations = ['flou de mouvement','brumeux','jpeg-compressé','faible luminosité','bruyant','goutte de pluie' ,'pluie','ombré','neigeux','incomplet']text = tokenizer(dégradations)avec torch.no_grad(), torch.cuda.amp.autocast():text_features = model.encode_text(text)image_features, degra_features = model.encode_image(image, control=True)degra_features /= degra_features.norm(dim=-1, keepdim=True)text_features / = text_features.norm(dim=-1, keepdim=True)text_probs = (100,0 * degra_features @ text_features.T).softmax(dim=-1)index = torch.argmax(text_probs[0])print(f"Tâche : {task_name} : {dégradations[index]} - {text_probs[0][index] }")Préparer les ensembles de données d'entraînement et de test en suivant notre section papier Construction d'ensembles de données comme :
#### pour l'ensemble de données d'entraînement ######## (incomplet signifie inpainting) ####datasets/universal/train|--motion-blurry| |--LQ/*.png| |--GT/*.png|--brumeux|--jpeg-compressé|--faible lumière|--bruyant|--goutte de pluie|--pluie|--ombré|--neigeux|--inachevé## ## pour tester l'ensemble de données ######## (la même structure que le train) ####datasets/universal/val ...#### pour des sous-titres propres ####datasets/universal/daclip_train.csv ensembles de données/universal/daclip_val.csv
Accédez ensuite au répertoire universal-image-restoration/config/daclip-sde et modifiez les chemins des ensembles de données dans les fichiers d'options dans options/train.yml et options/test.yml .
Vous pouvez ajouter plus de tâches ou d'ensembles de données aux répertoires train et val et ajouter le mot de dégradation à distortion .
| Dégradation | flou de mouvement | brumeux | compressé en jpeg* | faible luminosité | bruyant* (idem pour jpeg) |
|---|---|---|---|---|---|
| Ensembles de données | GoPro | RÉSIDE-6k | DIV2K+Flickr2K | MDR | DIV2K+Flickr2K |
| Dégradation | goutte de pluie | pluvieux | ombragé | neigeux | inachevé |
|---|---|---|---|---|---|
| Ensembles de données | Goutte de pluie | Rain100H : s’entraîner, tester | SRD | Neige100K | CelebaHQ-256 |
Vous devez uniquement extraire les ensembles de données du train pour la formation , et tous les ensembles de données de validation peuvent être téléchargés dans Google Drive. Pour les ensembles de données JPEG et bruyants, vous pouvez générer des images LQ à l'aide de ce script.
Voir DA-CLIP.md pour plus de détails.
Le code principal pour la formation se trouve dans universal-image-restoration/config/daclip-sde et le réseau principal de DA-CLIP se trouve dans universal-image-restoration/open_clip/daclip_model.py .
Placez les poids DA-CLIP pré-entraînés dans le répertoire pretrained et vérifiez le chemin daclip .
Vous pouvez ensuite entraîner le modèle en suivant les scripts bash ci-dessous :
cd universal-image-restoration/config/daclip-sde# Pour un seul GPU : python3 train.py -opt=options/train.yml# Pour une formation distribuée, vous devez modifier les gpu_ids dans l'option filepython3 -m torch.distributed.launch - -nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorch
Les modèles et les journaux de formation seront enregistrés dans log/universal-ir . Vous pouvez imprimer votre journal à la fois en exécutant tail -f log/universal-ir/train_universal-ir_***.log -n 100 .
Les mêmes étapes de formation peuvent être utilisées pour la restauration d'images dans la nature (wild-ir).
| Nom du modèle | Description | GoogleDrive | ÉtreindreVisage |
|---|---|---|---|
| DA-CLIP | Modèle CLIP prenant en compte la dégradation | télécharger | télécharger |
| IR universel | Modèle universel de restauration d'image basé sur DA-CLIP | télécharger | télécharger |
| DA-CLIP-mix | Modèle CLIP prenant en compte la dégradation (ajouter un flou gaussien + une peinture du visage et un flou gaussien + Rainy) | télécharger | télécharger |
| Mélange IR universel | Modèle universel de restauration d'image basé sur DA-CLIP (ajoute une formation robuste et des dégradations mixtes) | télécharger | télécharger |
| Sauvage-DA-CLIP | Modèle CLIP sensible à la dégradation dans la nature (ViT-L-14) | télécharger | télécharger |
| Wild-IR | Modèle de restauration d'image basé sur DA-CLIP dans la nature | télécharger | télécharger |
Pour évaluer notre méthode de restauration d'image, veuillez modifier le chemin de référence et le chemin du modèle et exécuter
cd restauration-image-universelle/config/universal-ir python test.py -opt=options/test.yml
Nous fournissons ici un fichier app.py pour tester vos propres images. Avant cela, vous devez télécharger les poids pré-entraînés (DA-CLIP et UIR) et modifier le chemin du modèle dans options/test.yml . Ensuite, en exécutant simplement python app.py , vous pouvez ouvrir http://localhost:7860 pour tester le modèle. (Nous fournissons également plusieurs images avec différentes dégradations dans la répertoire images ). Nous fournissons également plus d'exemples de notre ensemble de données de test dans Google Drive.
Les mêmes étapes peuvent être utilisées pour la restauration d'images dans la nature (wild-ir).
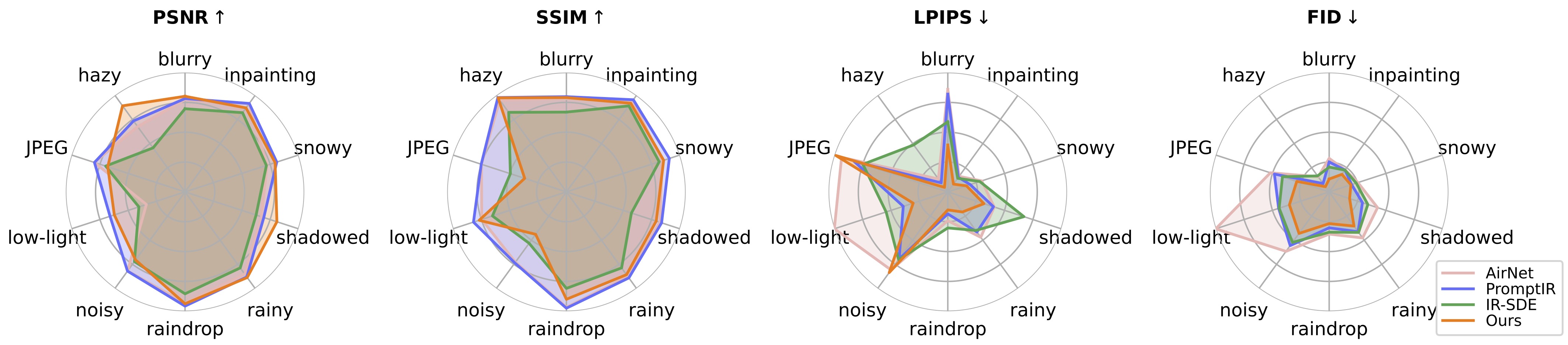



? Lors des tests, nous avons constaté que le modèle pré-entraîné actuel est encore difficile à traiter certaines images du monde réel qui pourraient avoir des changements de distribution avec notre ensemble de données d'entraînement (capturées à partir de différents appareils ou avec différentes résolutions ou dégradations). Nous le considérons comme un travail futur et essaierons de rendre notre modèle plus pratique ! Nous encourageons également les utilisateurs intéressés par notre travail à former leurs propres modèles avec un ensemble de données plus volumineux et davantage de types de dégradation.
? BTW, nous avons également constaté que le redimensionnement direct des images d'entrée entraînerait de mauvaises performances pour la plupart des tâches . Nous pourrions essayer d'ajouter l'étape de redimensionnement dans la formation mais cela détruit toujours la qualité de l'image à cause de l'interpolation.
? Pour la tâche d'inpainting, notre modèle actuel ne prend en charge que l'inpainting de visage en raison de la limitation de l'ensemble de données. Nous fournissons nos exemples de masques et vous pouvez utiliser le script generate_masked_face pour générer des visages incomplets.
Remerciement : Notre DA-CLIP est basé sur IR-SDE et open_clip. Merci pour leur code !
Si vous avez des questions, veuillez contacter : [email protected]
Si notre code vous aide dans vos recherches ou votre travail, pensez à citer notre article. Voici les références BibTeX :
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}

