Un cadre pour la formation de modèles de fondation multimodaux any-to-any.
Évolutif. Source ouverte. À travers des dizaines de modalités et de tâches.
EPFL - Pomme
Website | BibTeX | ? Demo
Implémentation officielle et modèles pré-entraînés pour :
4M : Modélisation masquée massivement multimodale , NeurIPS 2023 (Spotlight)
David Mizrahi*, Roman Bachmann*, Oğuzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, Amir Zamir
4M-21 : Un modèle de vision Any-to-Any pour des dizaines de tâches et de modalités , NeurIPS 2024
Roman Bachmann*, Oğuzhan Fatih Kar*, David Mizrahi*, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir
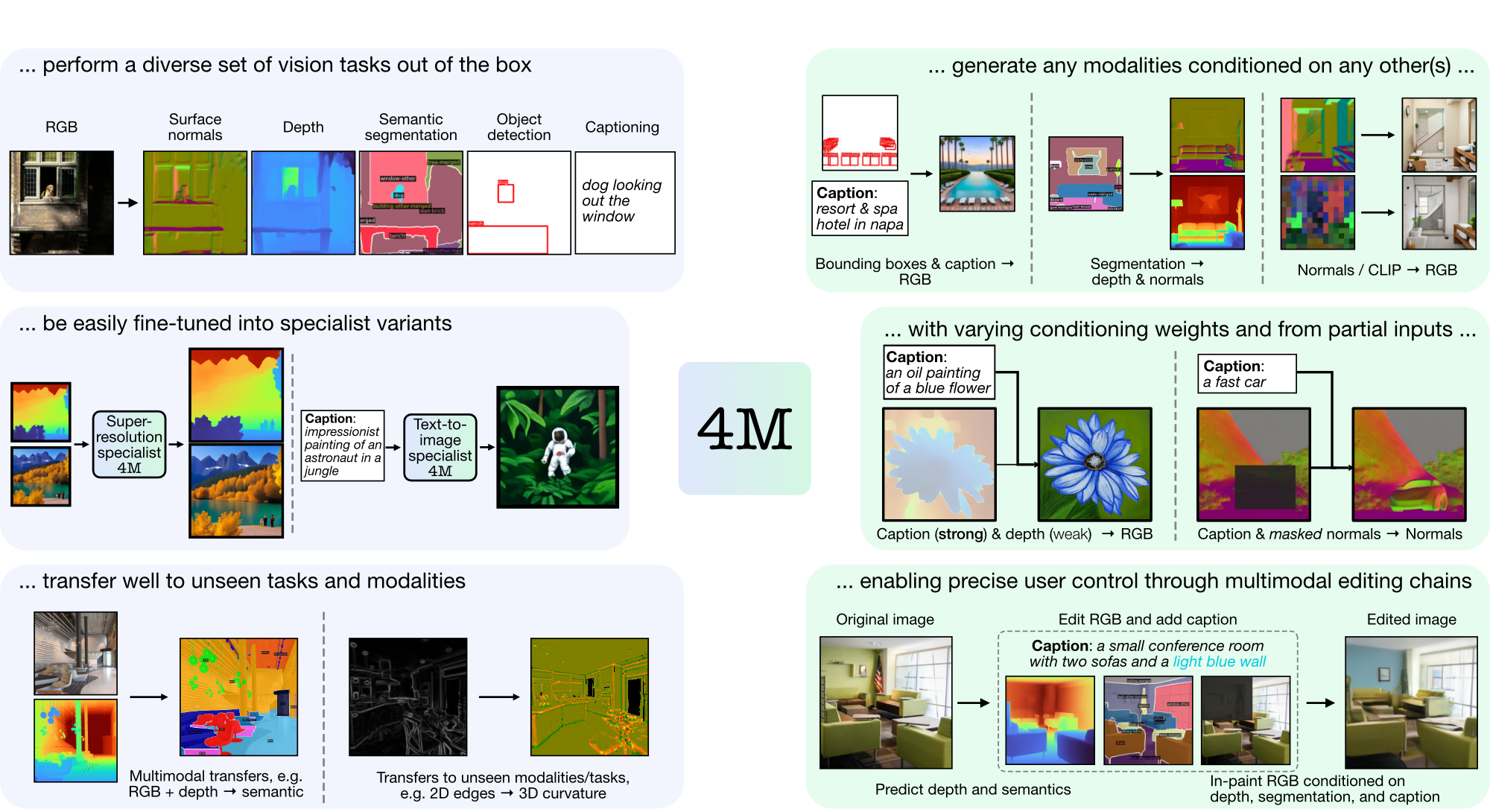
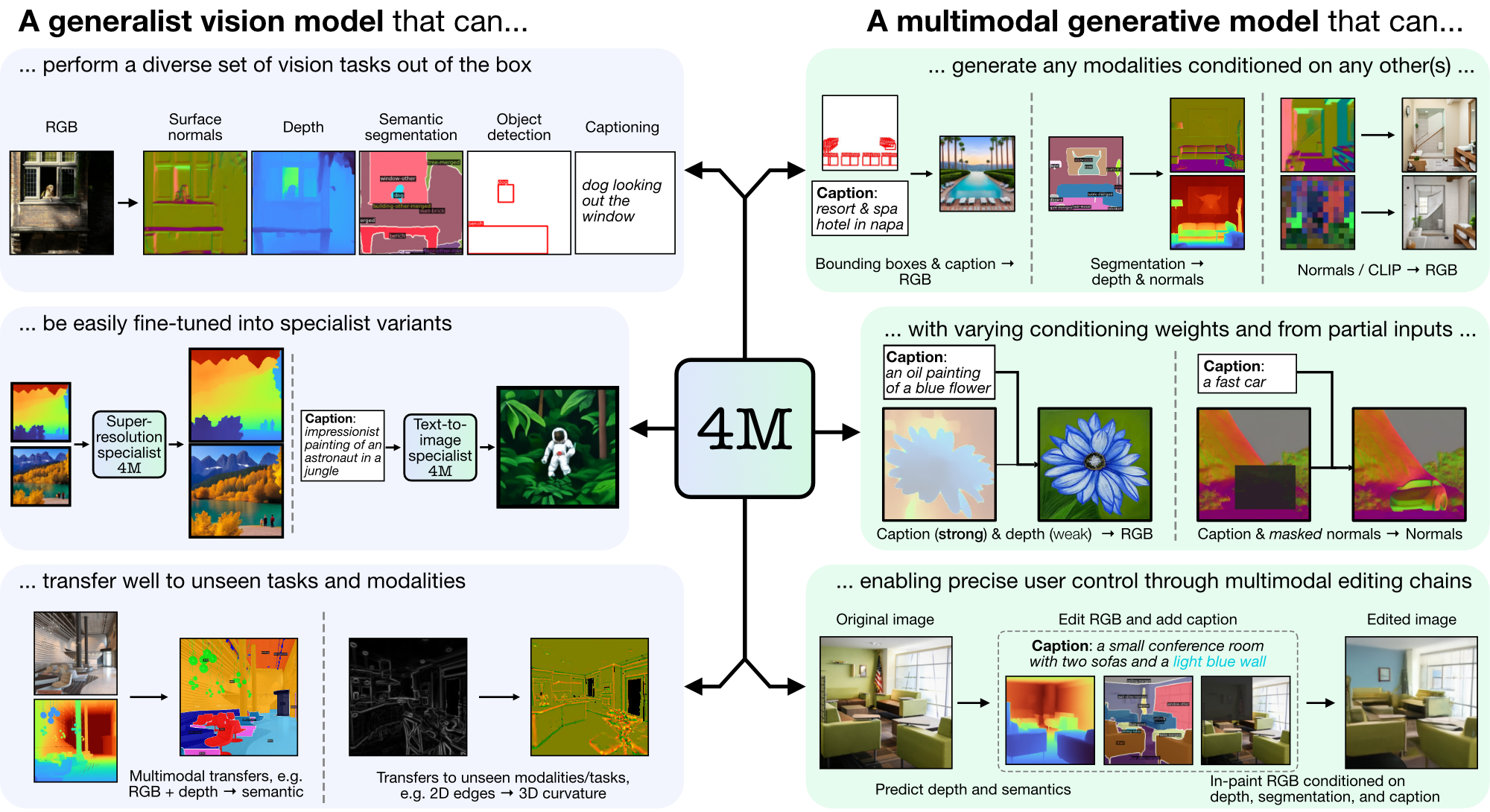
4M est un cadre permettant de former des modèles de base « tout-à-tout », utilisant la tokenisation et le masquage pour s'adapter à de nombreuses modalités diverses. Les modèles formés à l'aide de 4M peuvent effectuer un large éventail de tâches de vision, se transférer facilement vers des tâches et des modalités invisibles, et sont des modèles génératifs multimodaux flexibles et orientables. Nous publions du code et des modèles pour « 4M : Modélisation masquée massivement multimodale » (noté ici 4M-7), ainsi que « 4M-21 : Un modèle de vision Any-to-Any pour des dizaines de tâches et de modalités » (noté ici 4M). -21).
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
Si CUDA n'est pas disponible, envisagez de réinstaller PyTorch en suivant les instructions d'installation officielles. De même, si vous souhaitez installer xFormers (facultatif, pour des tokenizers plus rapides), suivez leur README pour vous assurer que la version CUDA est correcte.
Nous fournissons un wrapper de démonstration pour commencer rapidement à utiliser les modèles 4M pour les tâches de génération RVB pour tous ou {légende, cadres de délimitation} pour tous. Par exemple, pour générer toutes les modalités à partir d'une entrée RVB donnée, appelez :
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )Vous devriez vous attendre à voir une sortie comme celle-ci :


Pour effectuer la génération de sous-titres pour tous, vous pouvez remplacer l'entrée de l'échantillonneur par : preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) . Pour une liste des modèles 4M disponibles, veuillez consulter le zoo de modèles ci-dessous et consulter README_GENERATION.md pour plus d'instructions sur la génération.
Voir README_DATA.md pour obtenir des instructions sur la façon de préparer des ensembles de données multimodaux alignés.
Voir README_TOKENIZATION.md pour obtenir des instructions sur la façon de former des tokeniseurs spécifiques à une modalité.
Voir README_TRAINING.md pour obtenir des instructions sur la façon de former des modèles 4M.
Voir README_GENERATION.md pour obtenir des instructions sur la façon d'utiliser les modèles 4M pour l'inférence/génération. Nous fournissons également un cahier de génération qui contient des exemples d'inférence 4M, effectuant spécifiquement la génération d'images conditionnelles et des tâches de vision courantes (c'est-à-dire RVB vers tous).
Nous fournissons des points de contrôle 4M et tokenizer comme dispositifs de sécurité, et proposons également un chargement facile via Hugging Face Hub.
| Modèle | #Mod. | Ensembles de données | # Paramètres | Configuration | Poids |
|---|---|---|---|---|---|
| 4M-B | 7 | CC12M | 198M | Configuration | Point de contrôle / Hub HF |
| 4M-B | 7 | COYO700M | 198M | Configuration | Point de contrôle / Hub HF |
| 4M-B | 21 | CC12M+COYO700M+C4 | 198M | Configuration | Point de contrôle / Hub HF |
| 4M-L | 7 | CC12M | 705M | Configuration | Point de contrôle / Hub HF |
| 4M-L | 7 | COYO700M | 705M | Configuration | Point de contrôle / Hub HF |
| 4M-L | 21 | CC12M+COYO700M+C4 | 705M | Configuration | Point de contrôle / Hub HF |
| 4M-XL | 7 | CC12M | 2,8 milliards | Configuration | Point de contrôle / Hub HF |
| 4M-XL | 7 | COYO700M | 2,8 milliards | Configuration | Point de contrôle / Hub HF |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2,8 milliards | Configuration | Point de contrôle / Hub HF |
Pour charger des modèles depuis Hugging Face Hub :
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )Pour charger les points de contrôle manuellement, téléchargez d'abord les fichiers safetensors à partir des liens ci-dessus et appelez :
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )Ces modèles ont été initialisés avec les modèles standard 4M-7 CC12M, mais ont continué la formation avec un mélange de modalités fortement orienté vers la saisie de texte. Ils sont toujours capables d'effectuer toutes les autres tâches, mais fonctionnent mieux en matière de génération de texte en image par rapport aux modèles non affinés.
| Modèle | #Mod. | Ensembles de données | # Paramètres | Configuration | Poids |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198M | Configuration | Point de contrôle / Hub HF |
| 4M-T2I-L | 7 | CC12M | 705M | Configuration | Point de contrôle / Hub HF |
| 4M-T2I-XL | 7 | CC12M | 2,8 milliards | Configuration | Point de contrôle / Hub HF |
Pour charger des modèles depuis Hugging Face Hub :
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )Le chargement manuel à partir des points de contrôle s'effectue de la même manière que ci-dessus pour les modèles 4M de base.
| Modèle | #Mod. | Ensembles de données | # Paramètres | Configuration | Poids |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198M | Configuration | Point de contrôle / Hub HF |
Pour charger des modèles depuis Hugging Face Hub :
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )Le chargement manuel à partir des points de contrôle s'effectue de la même manière que ci-dessus pour les modèles 4M de base.
| Modalité | Résolution | Nombre de jetons | Taille du livre de codes | Décodeur de diffusion | Poids |
|---|---|---|---|---|---|
| RVB | 224-448 | 196-784 | 16k | ✓ | Point de contrôle / Hub HF |
| Profondeur | 224-448 | 196-784 | 8k | ✓ | Point de contrôle / Hub HF |
| Normales | 224-448 | 196-784 | 8k | ✓ | Point de contrôle / Hub HF |
| Bords (Canny, SAM) | 224-512 | 196-1024 | 8k | ✓ | Point de contrôle / Hub HF |
| Segmentation sémantique COCO | 224-448 | 196-784 | 4k | ✗ | Point de contrôle / Hub HF |
| CLIP-B/16 | 224-448 | 196-784 | 8k | ✗ | Point de contrôle / Hub HF |
| DINov2-B/14 | 224-448 | 256-1024 | 8k | ✗ | Point de contrôle / Hub HF |
| DINov2-B/14 (mondial) | 224 | 16 | 8k | ✗ | Point de contrôle / Hub HF |
| ImageBind-H/14 | 224-448 | 256-1024 | 8k | ✗ | Point de contrôle / Hub HF |
| ImageBind-H/14 (global) | 224 | 16 | 8k | ✗ | Point de contrôle / Hub HF |
| Instances SAM | - | 64 | 1k | ✗ | Point de contrôle / Hub HF |
| Poses humaines 3D | - | 8 | 1k | ✗ | Point de contrôle / Hub HF |
Pour charger des modèles depuis Hugging Face Hub :
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )Pour charger les points de contrôle manuellement, téléchargez d'abord les fichiers safetensors à partir des liens ci-dessus et appelez :
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )Le code de ce référentiel est publié sous la licence Apache 2.0 telle que trouvée dans le fichier LICENSE.
Les poids de modèle dans ce référentiel sont publiés sous la licence Sample Code telle que trouvée dans le fichier LICENSE_WEIGHTS.
Si vous trouvez ce référentiel utile, pensez à citer notre travail :
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


