system design 101
1.0.0
【 ?? YouTube | ? Bulletin 】
Expliquez les systèmes complexes à l’aide de visuels et de termes simples.
Que vous vous prépariez à un entretien de conception de système ou que vous souhaitiez simplement comprendre comment les systèmes fonctionnent sous la surface, nous espérons que ce référentiel vous aidera à y parvenir.
Les styles d'architecture définissent la manière dont les différents composants d'une interface de programmation d'application (API) interagissent les uns avec les autres. En conséquence, ils garantissent l'efficacité, la fiabilité et la facilité d'intégration avec d'autres systèmes en fournissant une approche standard pour la conception et la création d'API. Voici les styles les plus utilisés :
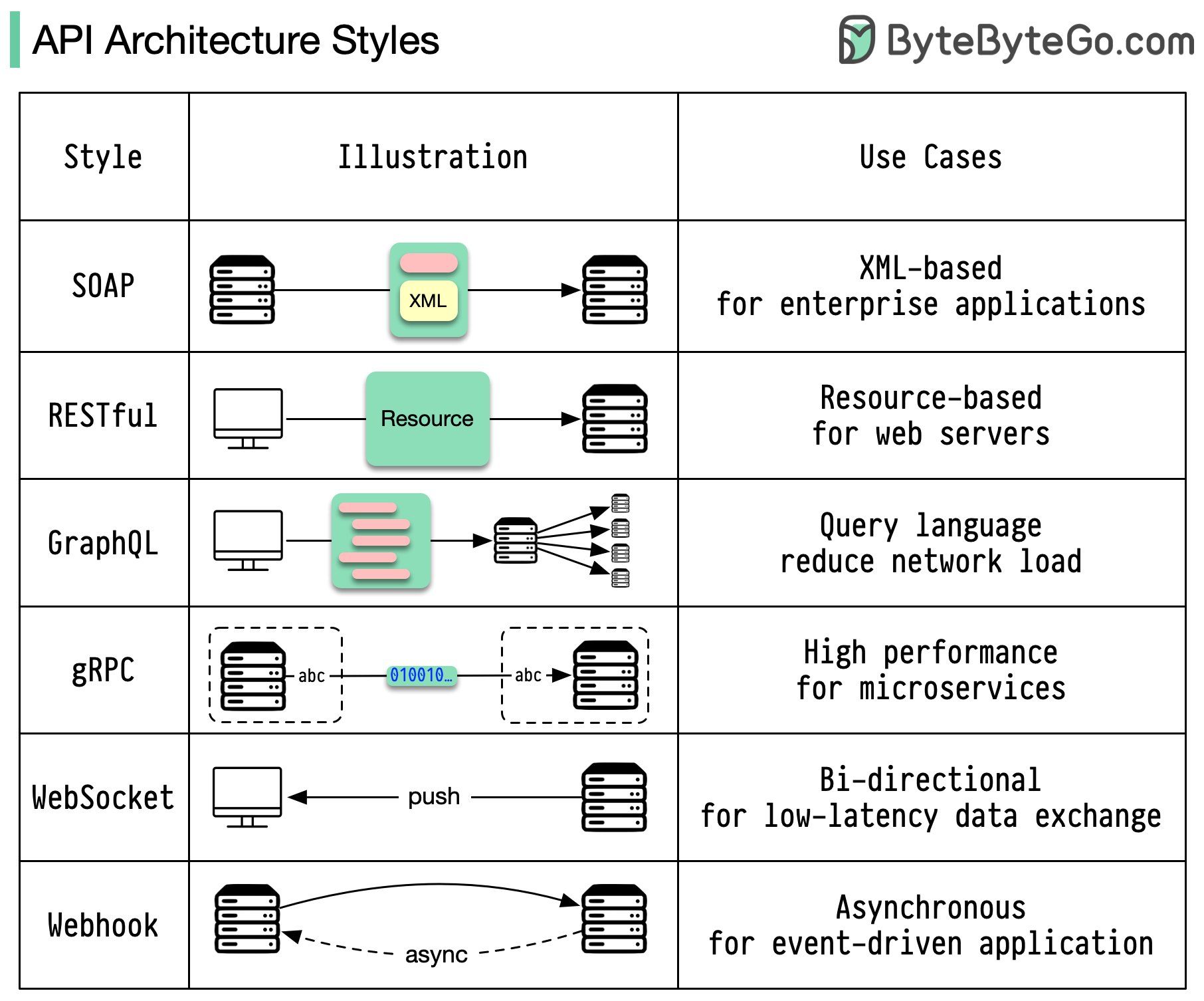
SAVON:
Mature, complet, basé sur XML
Idéal pour les applications d'entreprise
Reposant:
Méthodes HTTP populaires et faciles à mettre en œuvre
Idéal pour les services Web
GraphQL :
Langage de requête, demande de données spécifiques
Réduit la surcharge du réseau et des réponses plus rapides
gRPC :
Tampons de protocole modernes et performants
Adapté aux architectures de microservices
WebSocket :
Connexions en temps réel, bidirectionnelles et persistantes
Idéal pour l'échange de données à faible latence
Webhook :
Pilotés par les événements, rappels HTTP, asynchrones
Avertit les systèmes lorsque des événements se produisent
En matière de conception d'API, REST et GraphQL ont chacun leurs propres forces et faiblesses.
Le diagramme ci-dessous montre une comparaison rapide entre REST et GraphQL.
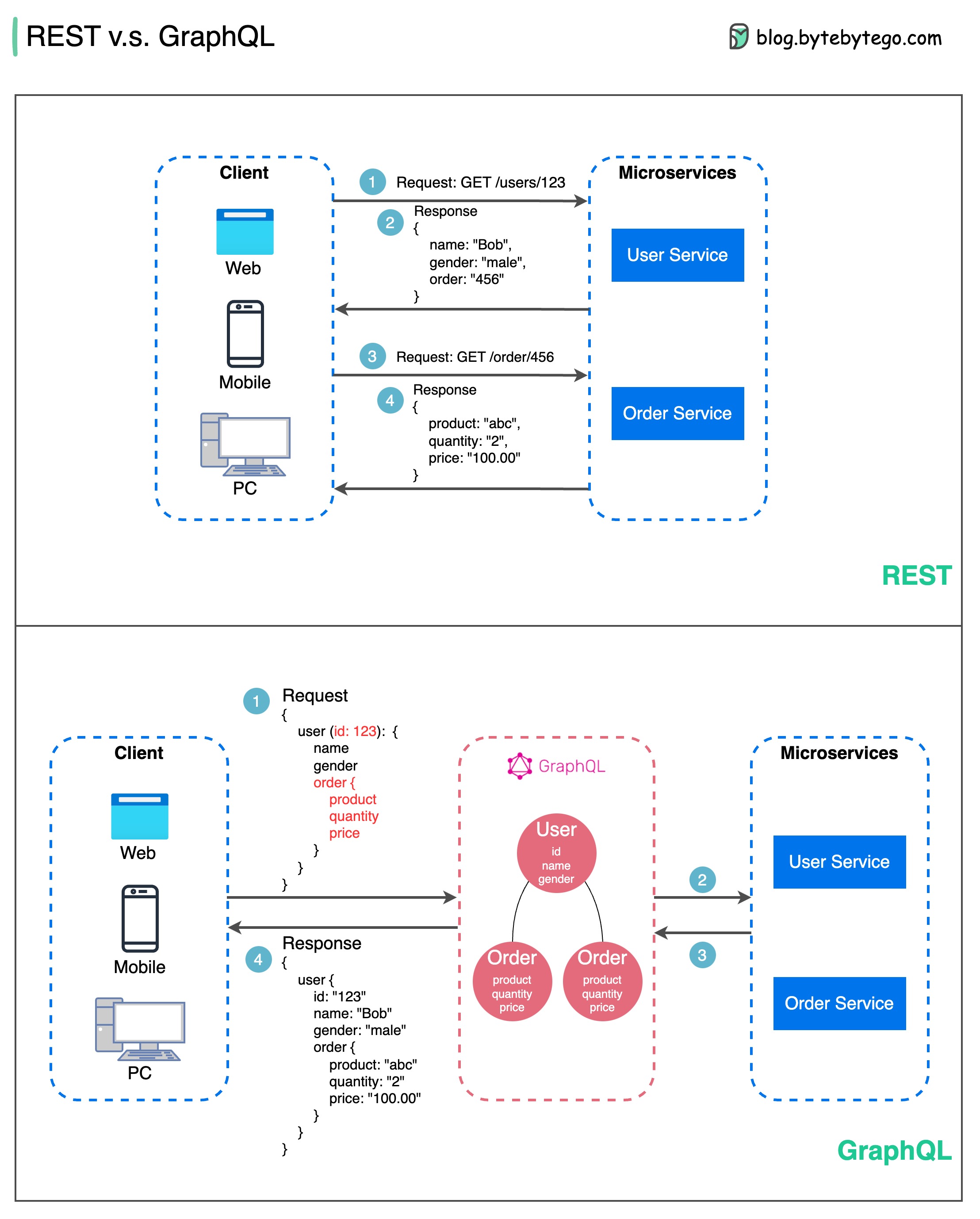
REPOS
GraphQL
Le meilleur choix entre REST et GraphQL dépend des exigences spécifiques de l'application et de l'équipe de développement. GraphQL convient parfaitement aux besoins frontaux complexes ou changeants, tandis que REST convient aux applications où des contrats simples et cohérents sont préférés.
Aucune des deux approches API n’est une solution miracle. Il est important d’évaluer soigneusement les exigences et les compromis pour choisir le bon style. REST et GraphQL sont tous deux des options valables pour exposer des données et alimenter des applications modernes.
RPC (Remote Procedure Call) est appelé « distant » car il permet les communications entre des services distants lorsque les services sont déployés sur différents serveurs sous une architecture de microservices. Du point de vue de l'utilisateur, cela agit comme un appel de fonction locale.
Le diagramme ci-dessous illustre le flux de données global pour gRPC .
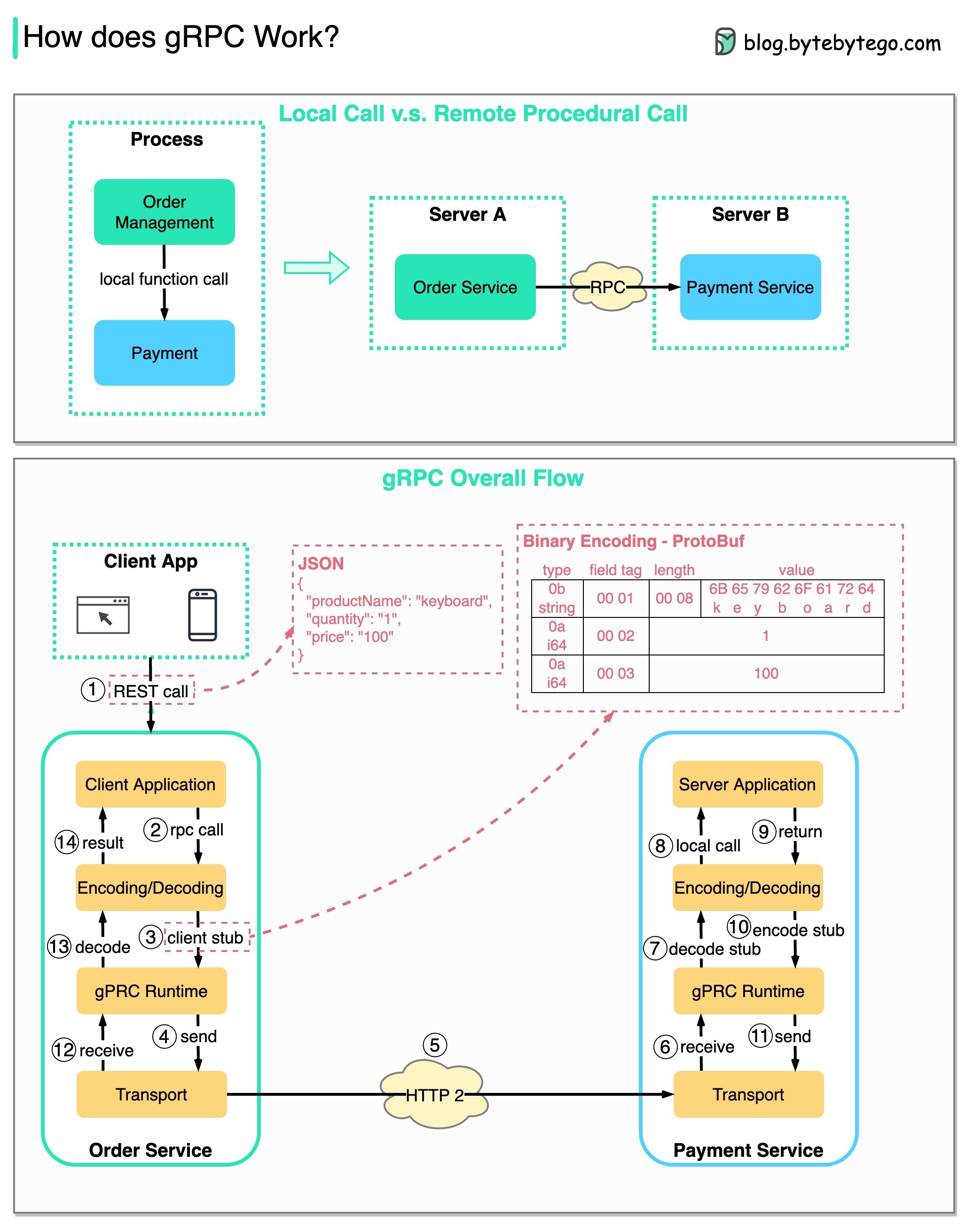
Étape 1 : Un appel REST est effectué depuis le client. Le corps de la requête est généralement au format JSON.
Étapes 2 à 4 : Le service de commande (client gRPC) reçoit l'appel REST, le transforme et effectue un appel RPC au service de paiement. gRPC code le stub client au format binaire et l'envoie à la couche de transport de bas niveau.
Étape 5 : gRPC envoie les paquets sur le réseau via HTTP2. En raison du codage binaire et des optimisations du réseau, gRPC serait 5 fois plus rapide que JSON.
Étapes 6 à 8 : Le service de paiement (serveur gRPC) reçoit les paquets du réseau, les décode et appelle l'application serveur.
Étapes 9 à 11 : le résultat est renvoyé par l'application serveur, codé et envoyé à la couche de transport.
Étapes 12 à 14 : Le service de commande reçoit les paquets, les décode et envoie le résultat à l'application client.
Le diagramme ci-dessous montre une comparaison entre l'interrogation et le Webhook.
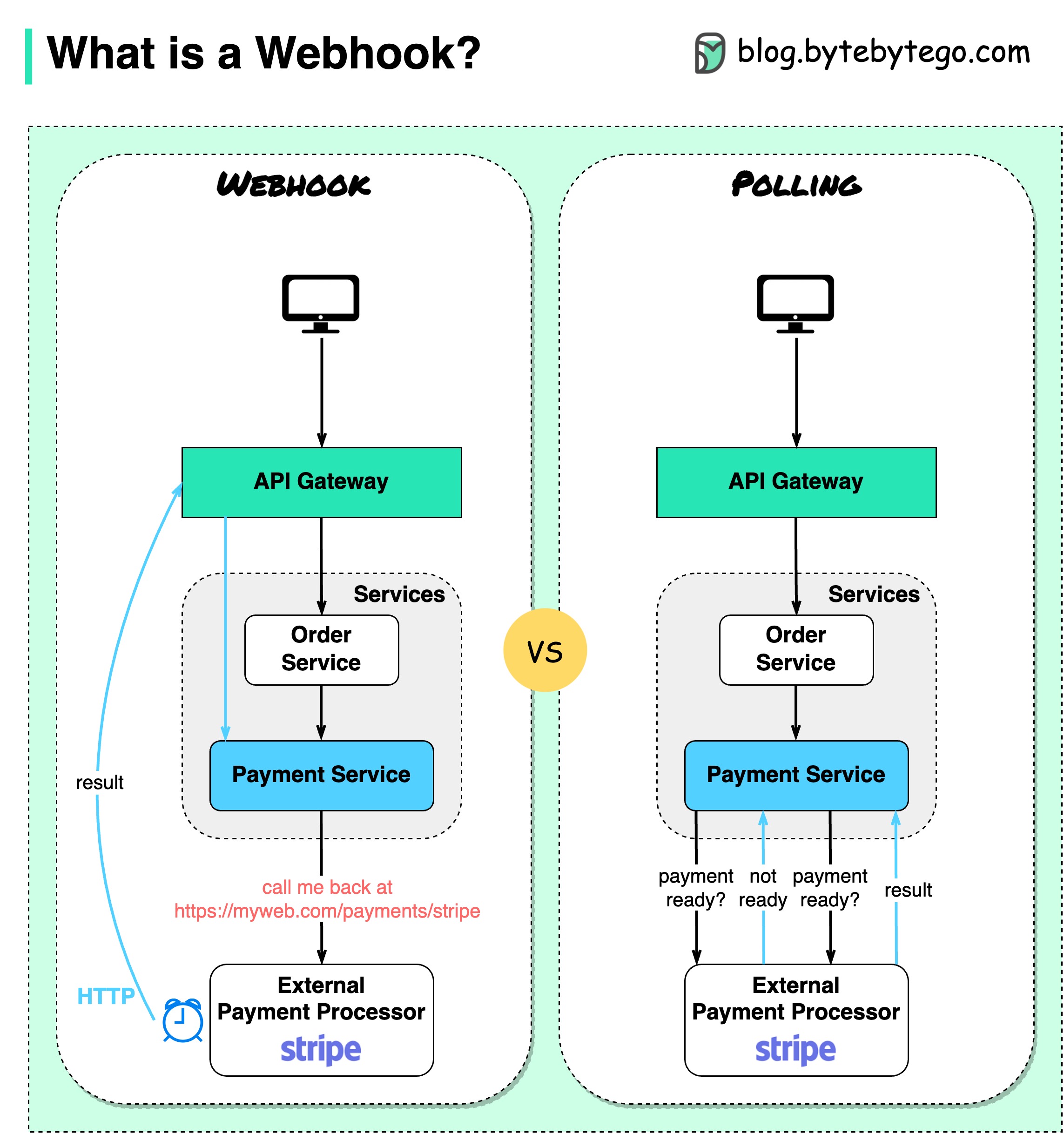
Supposons que nous gérions un site Web de commerce électronique. Les clients envoient des commandes au service de commande via la passerelle API, qui va au service de paiement pour les opérations de paiement. Le service de paiement s'adresse ensuite à un prestataire de services de paiement (PSP) externe pour finaliser les transactions.
Il existe deux manières de gérer les communications avec la PSP externe.
1. Sondage court
Après avoir envoyé la demande de paiement au PSP, le service de paiement continue de demander au PSP l'état du paiement. Après plusieurs tours, la PSP revient enfin avec le statut.
Les sondages courts présentent deux inconvénients :
2. Webhook
Nous pouvons enregistrer un webhook auprès du service externe. Cela signifie : rappelez-moi à une certaine URL lorsque vous avez des mises à jour sur la demande. Lorsque le PSP aura terminé le traitement, il invoquera la requête HTTP pour mettre à jour le statut du paiement.
De cette façon, le paradigme de programmation est modifié et le service de paiement n'a plus besoin de gaspiller des ressources pour interroger l'état du paiement.
Et si la PSP ne rappelle jamais ? Nous pouvons organiser un travail de ménage pour vérifier l'état des paiements toutes les heures.
Les webhooks sont souvent appelés API inversées ou API push, car le serveur envoie des requêtes HTTP au client. Nous devons prêter attention à 3 choses lorsque nous utilisons un webhook :
Le diagramme ci-dessous montre 5 astuces courantes pour améliorer les performances de l'API.
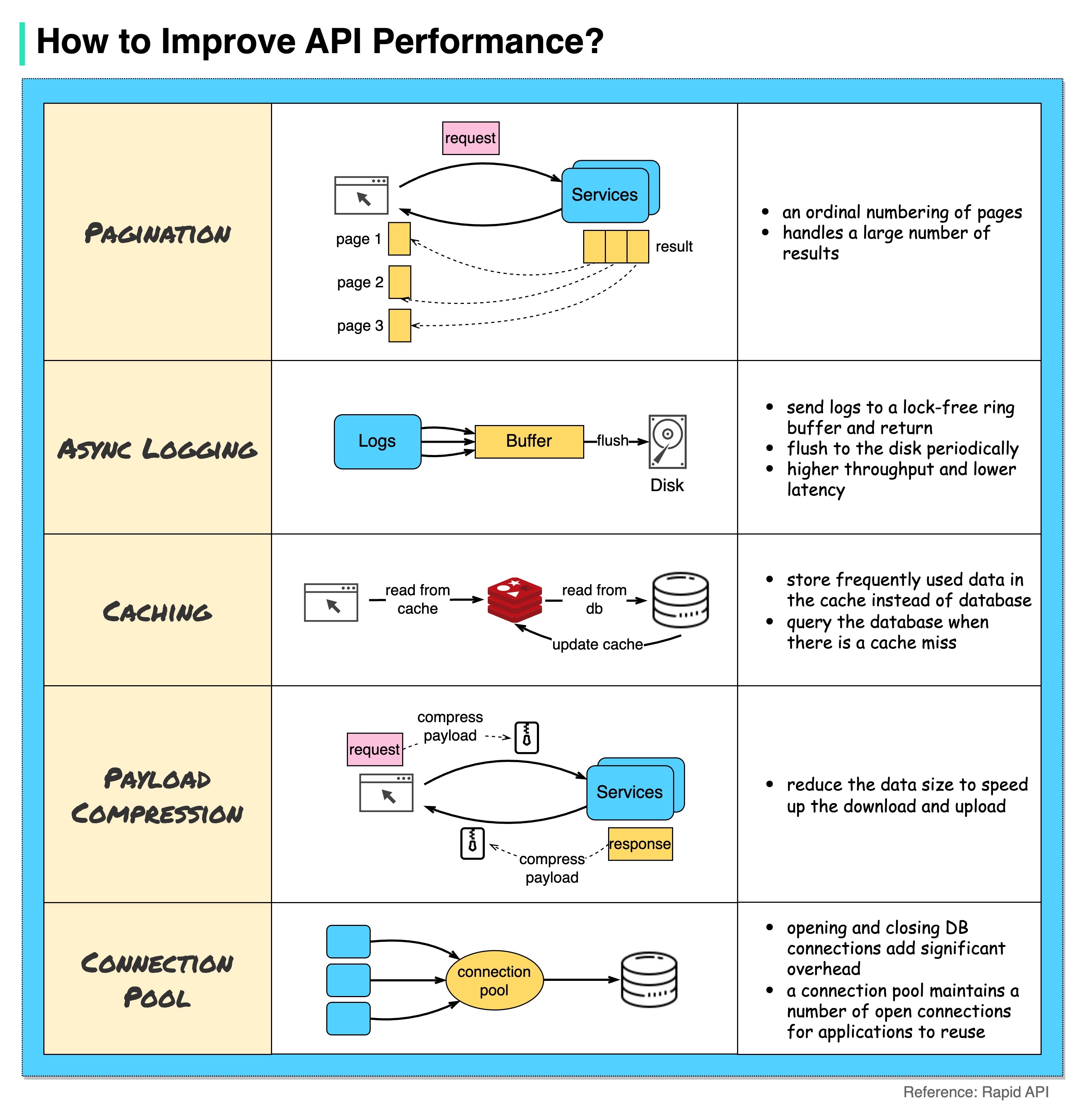
Pagination
Il s'agit d'une optimisation courante lorsque la taille du résultat est grande. Les résultats sont renvoyés au client pour améliorer la réactivité du service.
Journalisation asynchrone
La journalisation synchrone traite le disque pour chaque appel et peut ralentir le système. La journalisation asynchrone envoie d'abord les journaux vers un tampon sans verrouillage et les renvoie immédiatement. Les journaux seront vidés périodiquement sur le disque. Cela réduit considérablement la surcharge d’E/S.
Mise en cache
Nous pouvons stocker les données fréquemment consultées dans un cache. Le client peut d'abord interroger le cache au lieu de visiter directement la base de données. En cas d'échec du cache, le client peut interroger la base de données. Les caches comme Redis stockent les données en mémoire, l'accès aux données est donc beaucoup plus rapide que la base de données.
Compression de la charge utile
Les demandes et les réponses peuvent être compressées à l'aide de gzip, etc. afin que la taille des données transmises soit beaucoup plus petite. Cela accélère le téléchargement et le téléchargement.
Pool de connexions
Lors de l'accès aux ressources, nous devons souvent charger des données à partir de la base de données. L'ouverture des connexions de fermeture de la base de données ajoute une surcharge importante. Nous devrions donc nous connecter à la base de données via un pool de connexions ouvertes. Le pool de connexions est responsable de la gestion du cycle de vie des connexions.
Quel problème chaque génération de HTTP résout-elle ?
Le diagramme ci-dessous illustre les principales caractéristiques.
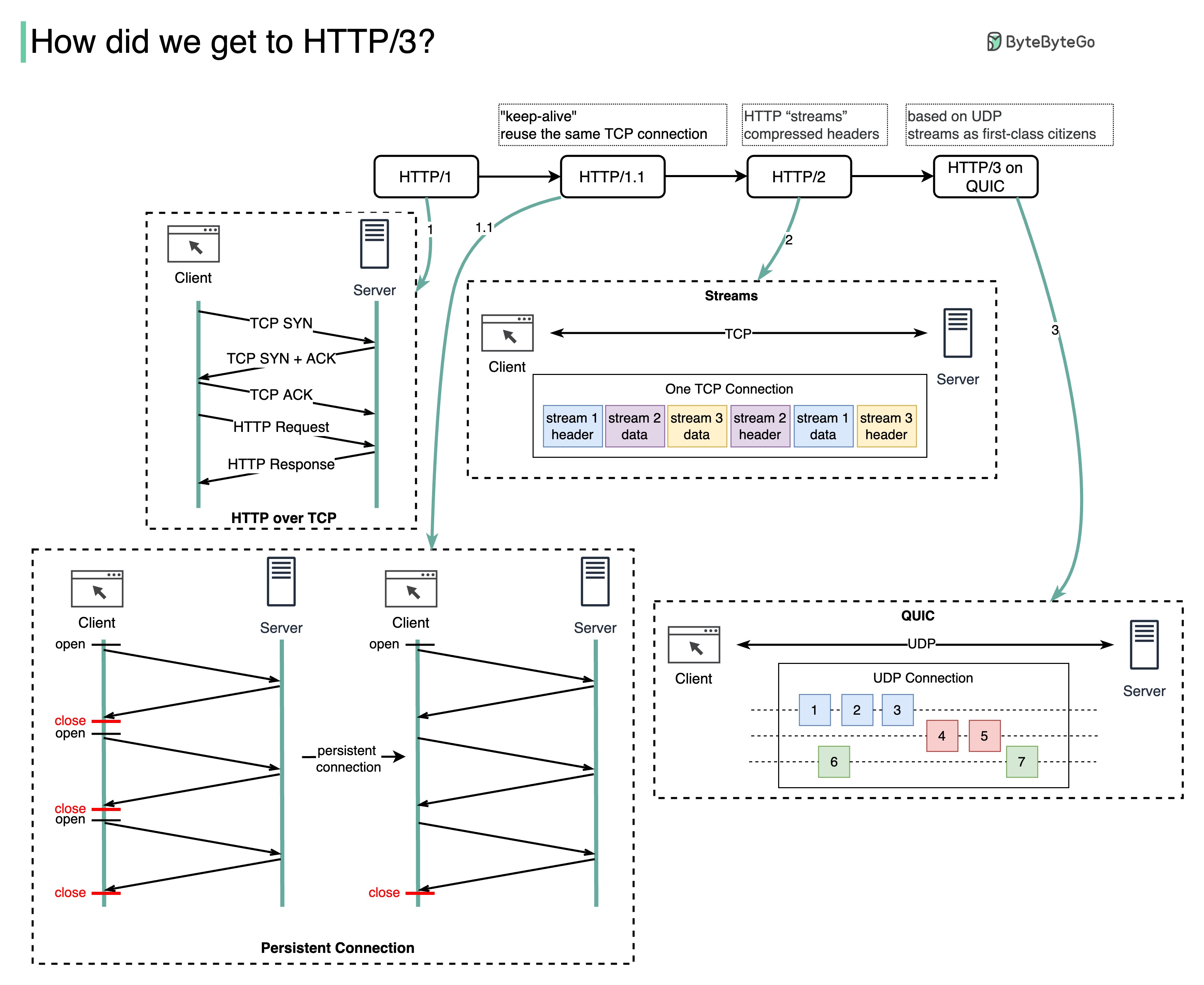
HTTP 1.0 a été finalisé et entièrement documenté en 1996. Chaque requête adressée au même serveur nécessite une connexion TCP distincte.
HTTP 1.1 a été publié en 1997. Une connexion TCP peut être laissée ouverte pour être réutilisée (connexion persistante), mais cela ne résout pas le problème de blocage HOL (tête de ligne).
Blocage HOL - lorsque le nombre de requêtes parallèles autorisées dans le navigateur est épuisé, les requêtes suivantes doivent attendre que les précédentes soient terminées.
HTTP 2.0 a été publié en 2015. Il résout le problème HOL via le multiplexage des requêtes, qui élimine le blocage HOL au niveau de la couche application, mais HOL existe toujours au niveau de la couche transport (TCP).
Comme vous pouvez le voir sur le schéma, HTTP 2.0 a introduit le concept de « flux » HTTP : une abstraction qui permet de multiplexer différents échanges HTTP sur la même connexion TCP. Chaque flux n'a pas besoin d'être envoyé dans l'ordre.
La première version de HTTP 3.0 a été publiée en 2020. Il s'agit du successeur proposé de HTTP 2.0. Il utilise QUIC au lieu de TCP pour le protocole de transport sous-jacent, supprimant ainsi le blocage HOL dans la couche de transport.
QUIC est basé sur UDP. Il introduit les flux en tant que citoyens de première classe au niveau du transport. Les flux QUIC partagent la même connexion QUIC, donc aucune poignée de main supplémentaire ni démarrage lent n'est nécessaire pour en créer de nouveaux, mais les flux QUIC sont livrés indépendamment de telle sorte que dans la plupart des cas, la perte de paquets affectant un flux n'affecte pas les autres.
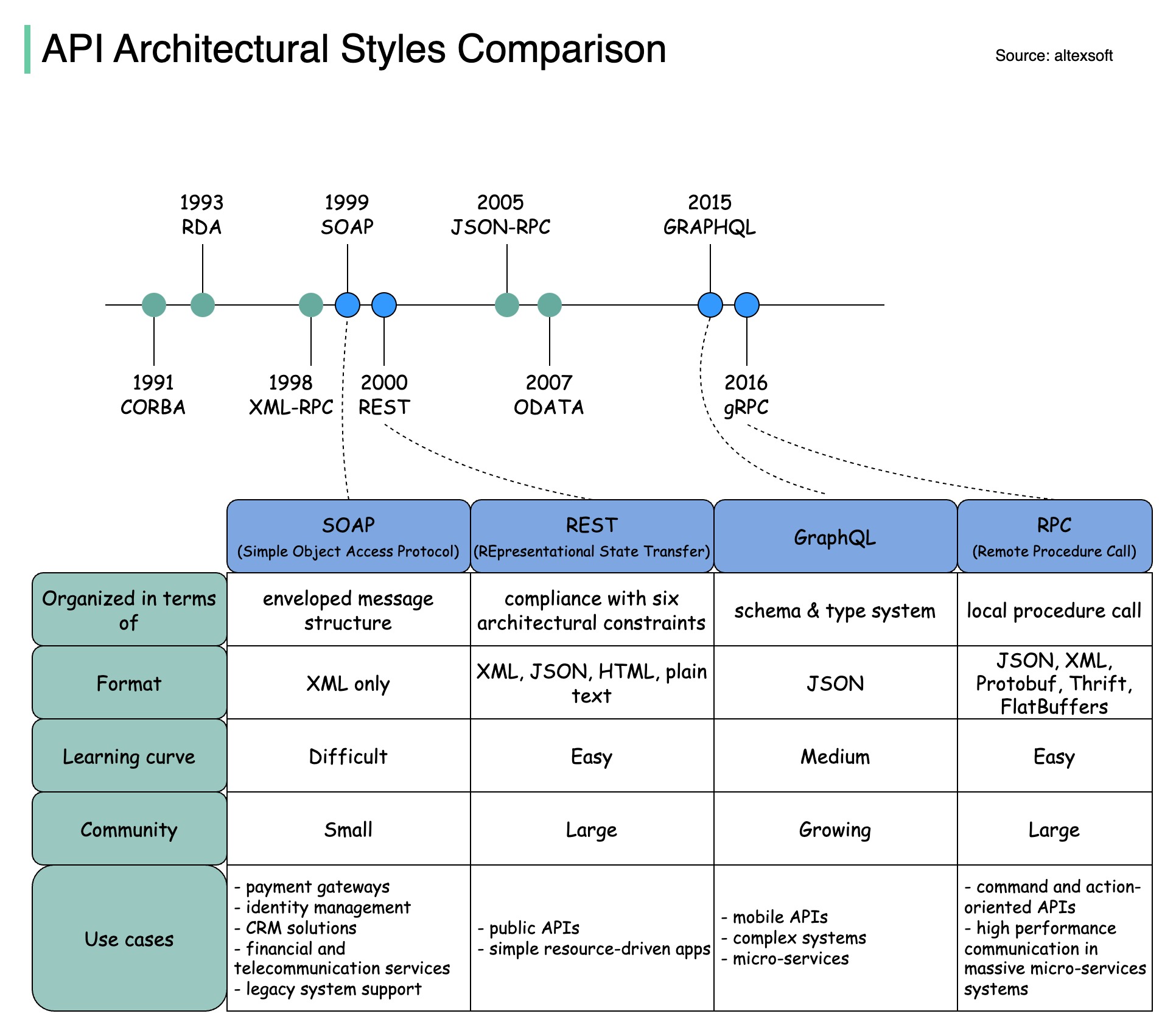
Le diagramme ci-dessous illustre la comparaison de la chronologie de l'API et des styles d'API.
Au fil du temps, différents styles architecturaux d'API sont publiés. Chacun d'eux a ses propres modèles de normalisation de l'échange de données.
Vous pouvez consulter les cas d’utilisation de chaque style dans le diagramme.
Le diagramme ci-dessous montre les différences entre le développement axé sur le code et le développement axé sur l'API. Pourquoi voulons-nous considérer la conception d’API en premier ?
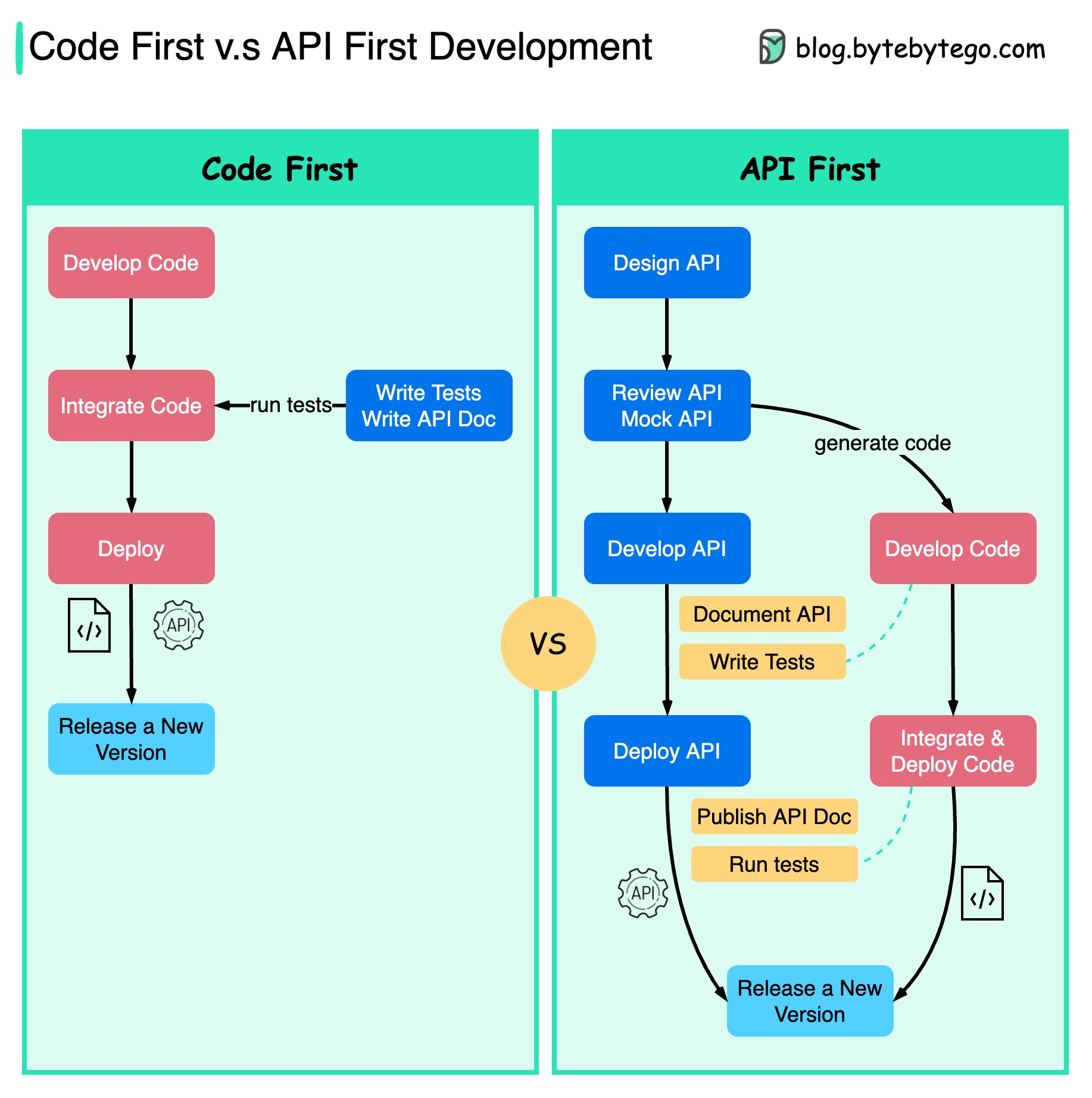
Il est préférable de réfléchir à la complexité du système avant d'écrire le code et de définir soigneusement les limites des services.
Nous pouvons simuler des requêtes et des réponses pour valider la conception de l'API avant d'écrire du code.
Les développeurs sont également satisfaits du processus car ils peuvent se concentrer sur le développement fonctionnel au lieu de négocier des changements soudains.
La possibilité d'avoir des surprises vers la fin du cycle de vie du projet est réduite.
Comme nous avons d'abord conçu l'API, les tests peuvent être conçus pendant le développement du code. D'une certaine manière, nous avons également TDD (Test Driven Design) lorsque nous utilisons le premier développement d'API.
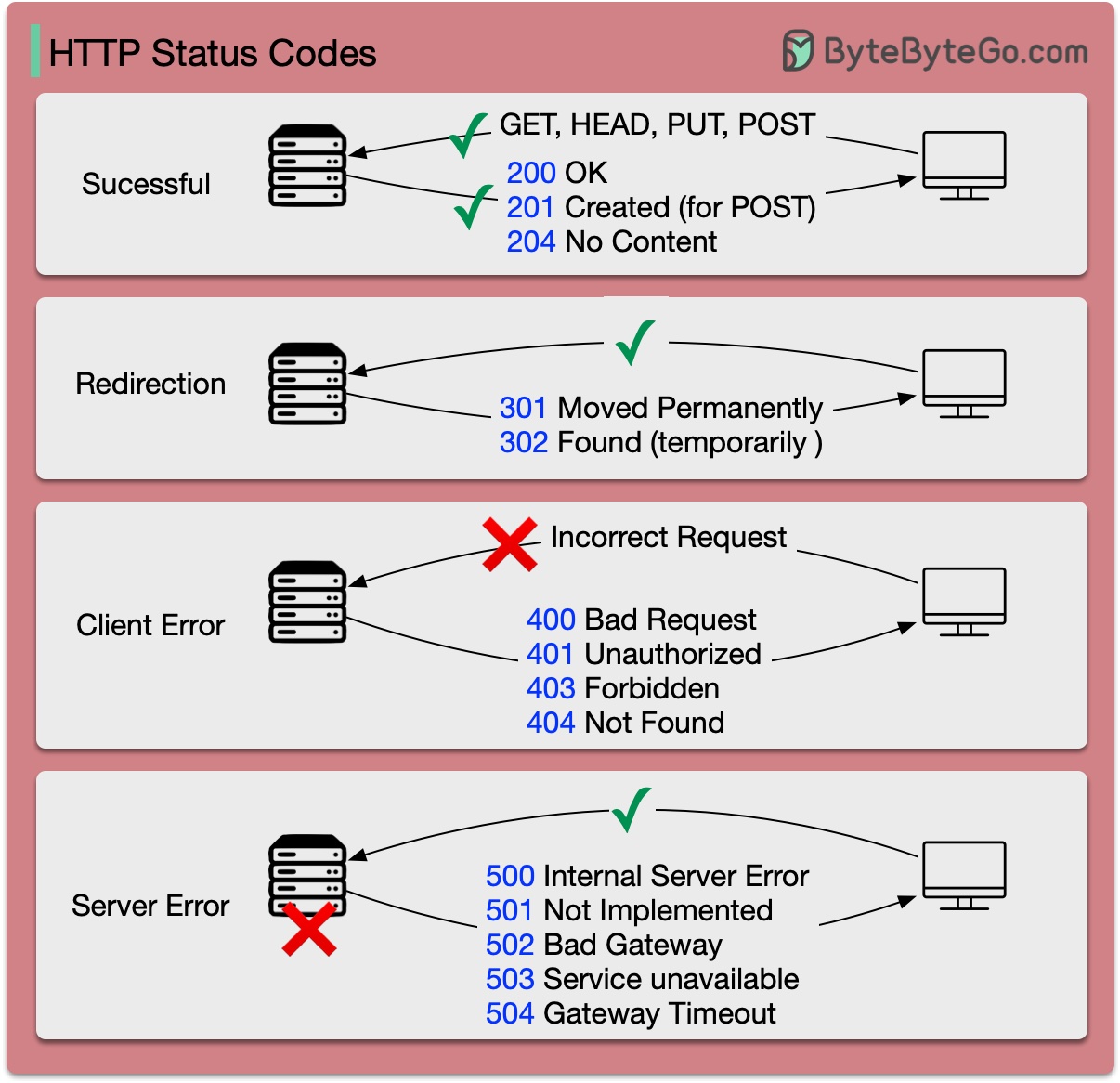
Les codes de réponse pour HTTP sont divisés en cinq catégories :
Informatif (100-199) Réussite (200-299) Redirection (300-399) Erreur client (400-499) Erreur de serveur (500-599)
Le diagramme ci-dessous montre les détails.
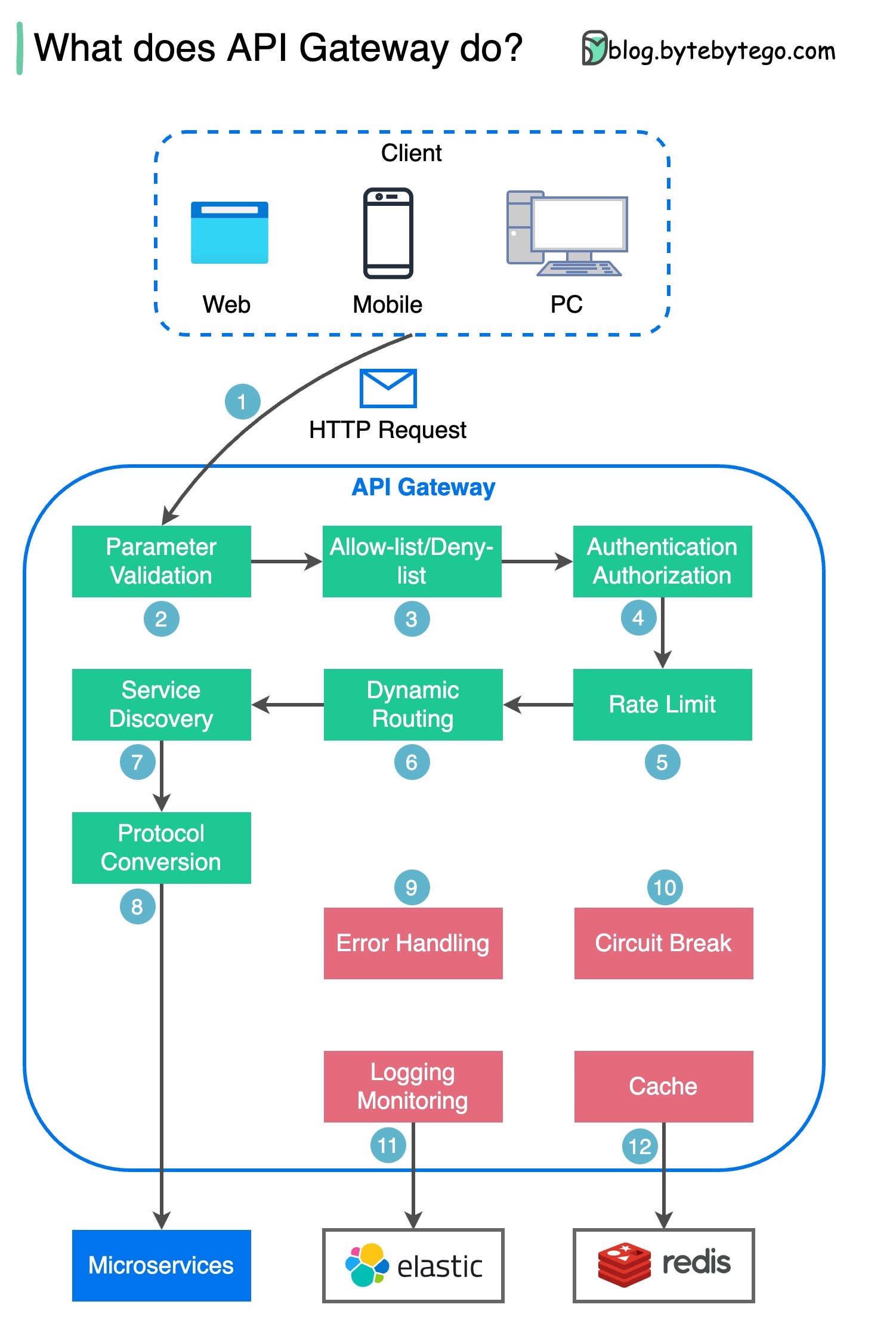
Étape 1 - Le client envoie une requête HTTP à la passerelle API.
Étape 2 : La passerelle API analyse et valide les attributs de la requête HTTP.
Étape 3 : La passerelle API effectue des vérifications de liste d'autorisation/liste de refus.
Étape 4 : La passerelle API communique avec un fournisseur d'identité pour l'authentification et l'autorisation.
Étape 5 - Les règles de limitation de débit sont appliquées à la demande. Si la limite est dépassée, la demande est rejetée.
Étapes 6 et 7 : Maintenant que la requête a réussi les vérifications de base, la passerelle API trouve le service pertinent vers lequel acheminer par correspondance de chemin.
Étape 8 - La passerelle API transforme la requête dans le protocole approprié et l'envoie aux microservices backend.
Étapes 9 à 12 : la passerelle API peut gérer correctement les erreurs et traite les erreurs si la récupération de l'erreur prend plus de temps (coupure de circuit). Il peut également exploiter la pile ELK (Elastic-Logstash-Kibana) pour la journalisation et la surveillance. Nous mettons parfois en cache des données dans la passerelle API.
Le diagramme ci-dessous montre des conceptions d'API typiques avec un exemple de panier d'achat.
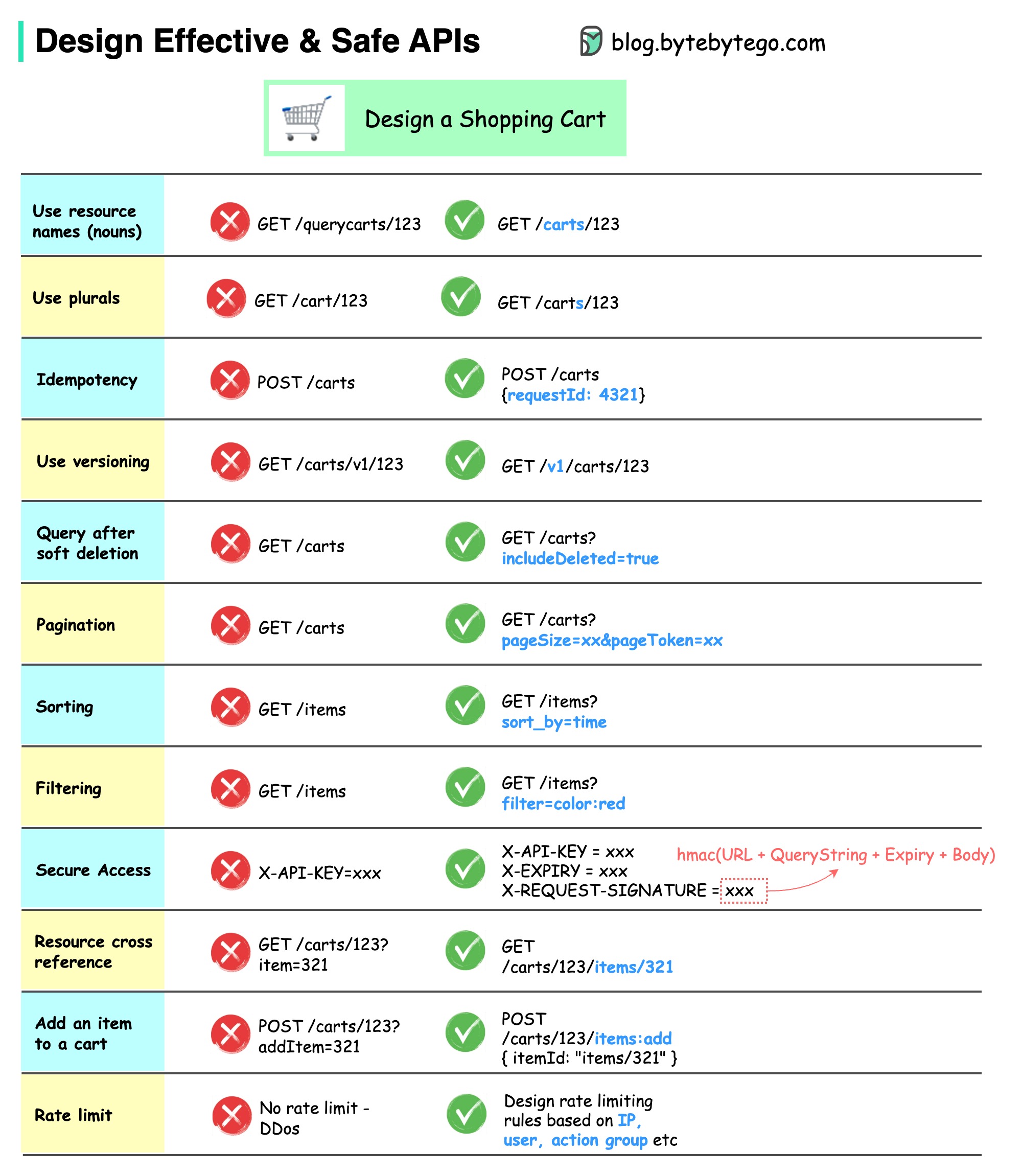
Notez que la conception d’API ne se limite pas à la conception de chemins d’URL. La plupart du temps, nous devons choisir les noms de ressources, les identifiants et les modèles de chemin appropriés. Il est tout aussi important de concevoir des champs d’en-tête HTTP appropriés ou de concevoir des règles efficaces de limitation de débit au sein de la passerelle API.
Comment les données sont-elles envoyées sur le réseau ? Pourquoi avons-nous besoin de tant de couches dans le modèle OSI ?
Le diagramme ci-dessous montre comment les données sont encapsulées et désencapsulées lors de la transmission sur le réseau.
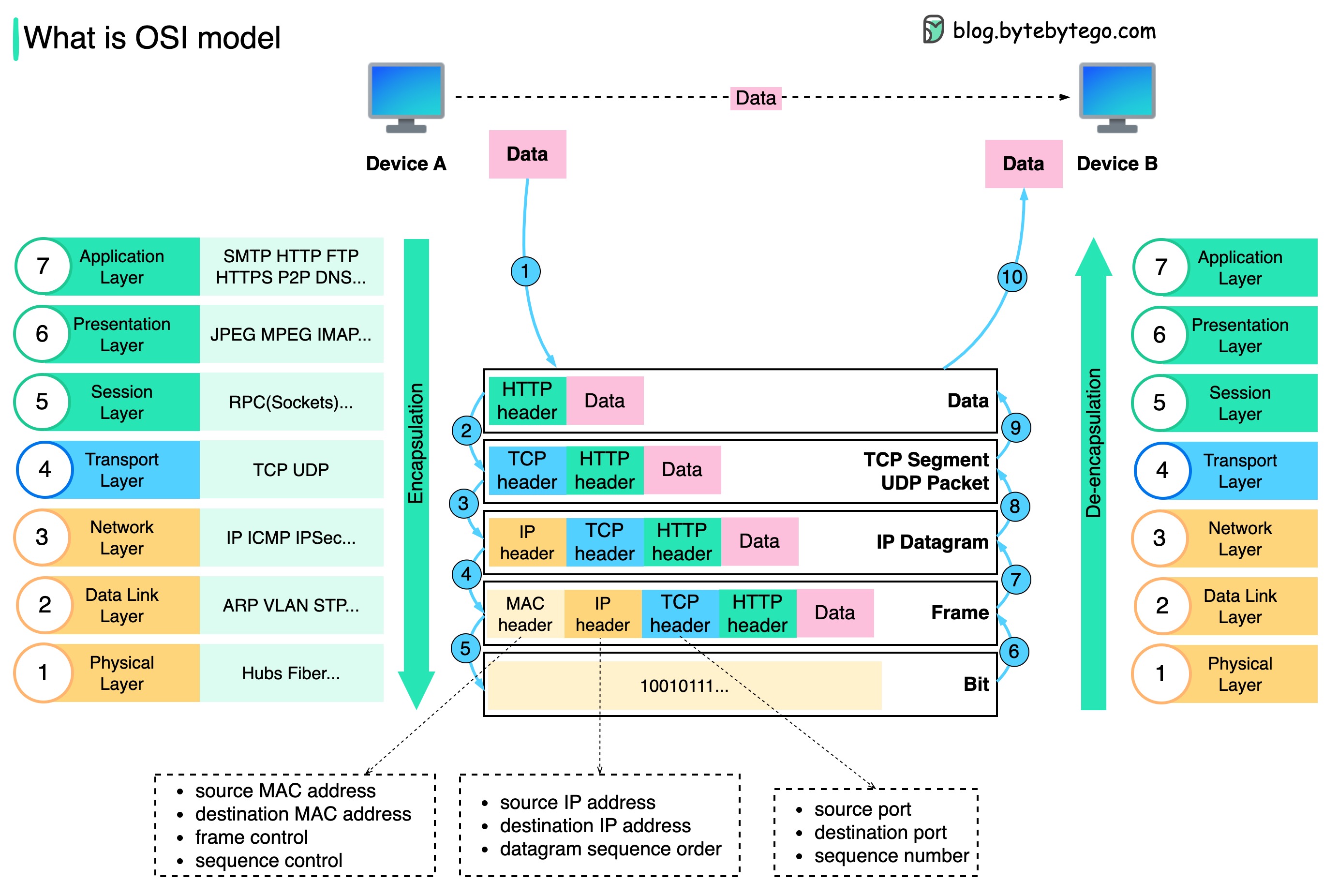
Étape 1 : Lorsque le périphérique A envoie des données au périphérique B via le réseau via le protocole HTTP, un en-tête HTTP lui est d'abord ajouté au niveau de la couche application.
Étape 2 : Ensuite, un en-tête TCP ou UDP est ajouté aux données. Il est encapsulé dans des segments TCP au niveau de la couche transport. L'en-tête contient le port source, le port de destination et le numéro de séquence.
Étape 3 : Les segments sont ensuite encapsulés avec un en-tête IP au niveau de la couche réseau. L'en-tête IP contient les adresses IP source/destination.
Étape 4 : Le datagramme IP reçoit un en-tête MAC au niveau de la couche liaison de données, avec des adresses MAC source/destination.
Étape 5 : Les trames encapsulées sont envoyées à la couche physique et envoyées sur le réseau en bits binaires.
Étapes 6 à 10 : lorsque le périphérique B reçoit les bits du réseau, il exécute le processus de désencapsulation, qui est un traitement inverse du processus d'encapsulation. Les en-têtes sont supprimés couche par couche et, finalement, le périphérique B peut lire les données.
Nous avons besoin de couches dans le modèle de réseau car chaque couche se concentre sur ses propres responsabilités. Chaque couche peut s'appuyer sur les en-têtes pour les instructions de traitement et n'a pas besoin de connaître la signification des données de la dernière couche.
Le schéma ci-dessous montre les différences entre un ??????? ????? et un ??????? ??????.
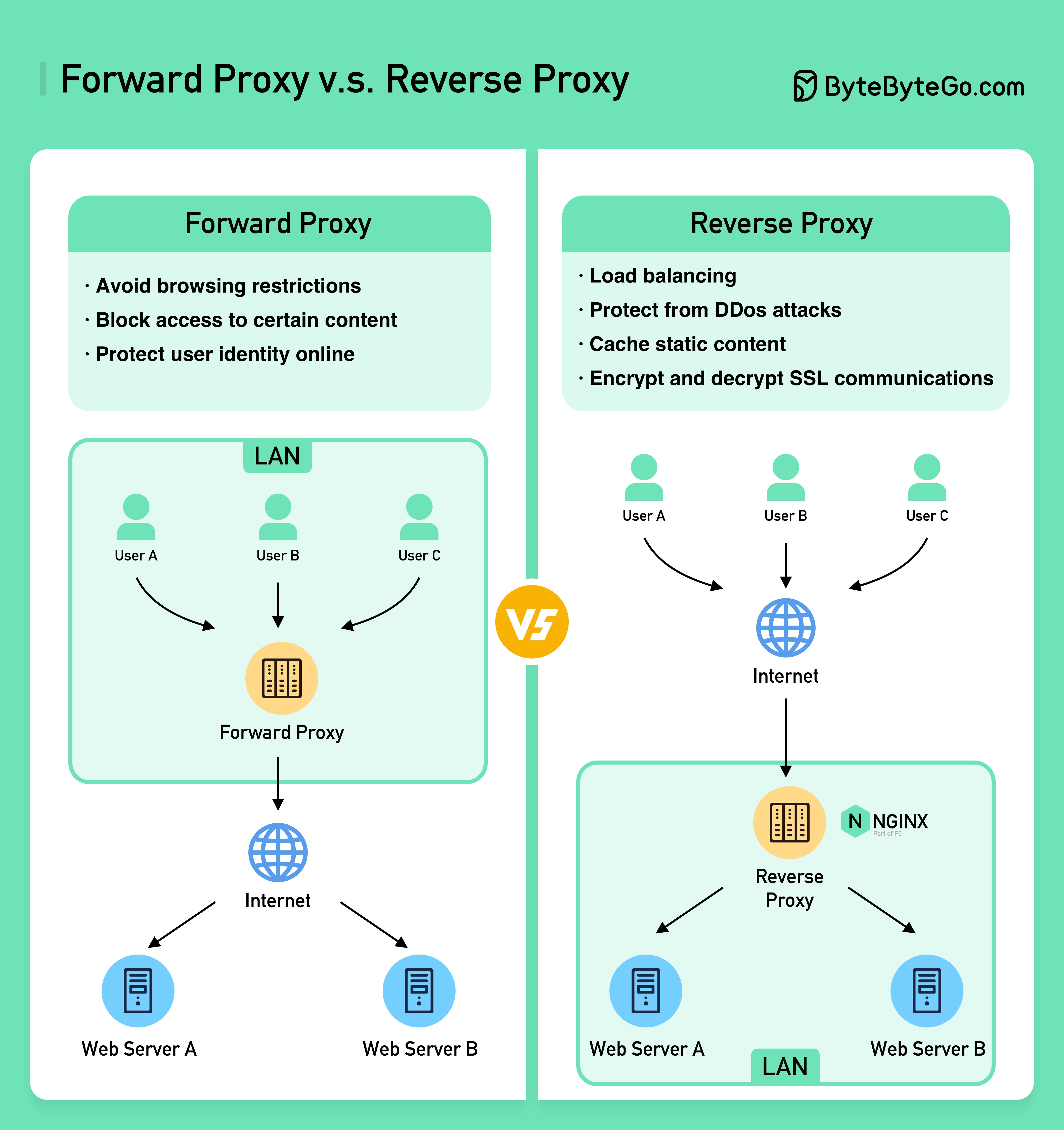
Un proxy de transfert est un serveur situé entre les appareils des utilisateurs et Internet.
Un proxy direct est couramment utilisé pour :
Un proxy inverse est un serveur qui accepte une demande du client, transmet la demande aux serveurs Web et renvoie les résultats au client comme si le serveur proxy avait traité la demande.
Un proxy inverse est utile pour :
Le diagramme ci-dessous montre 6 algorithmes courants.
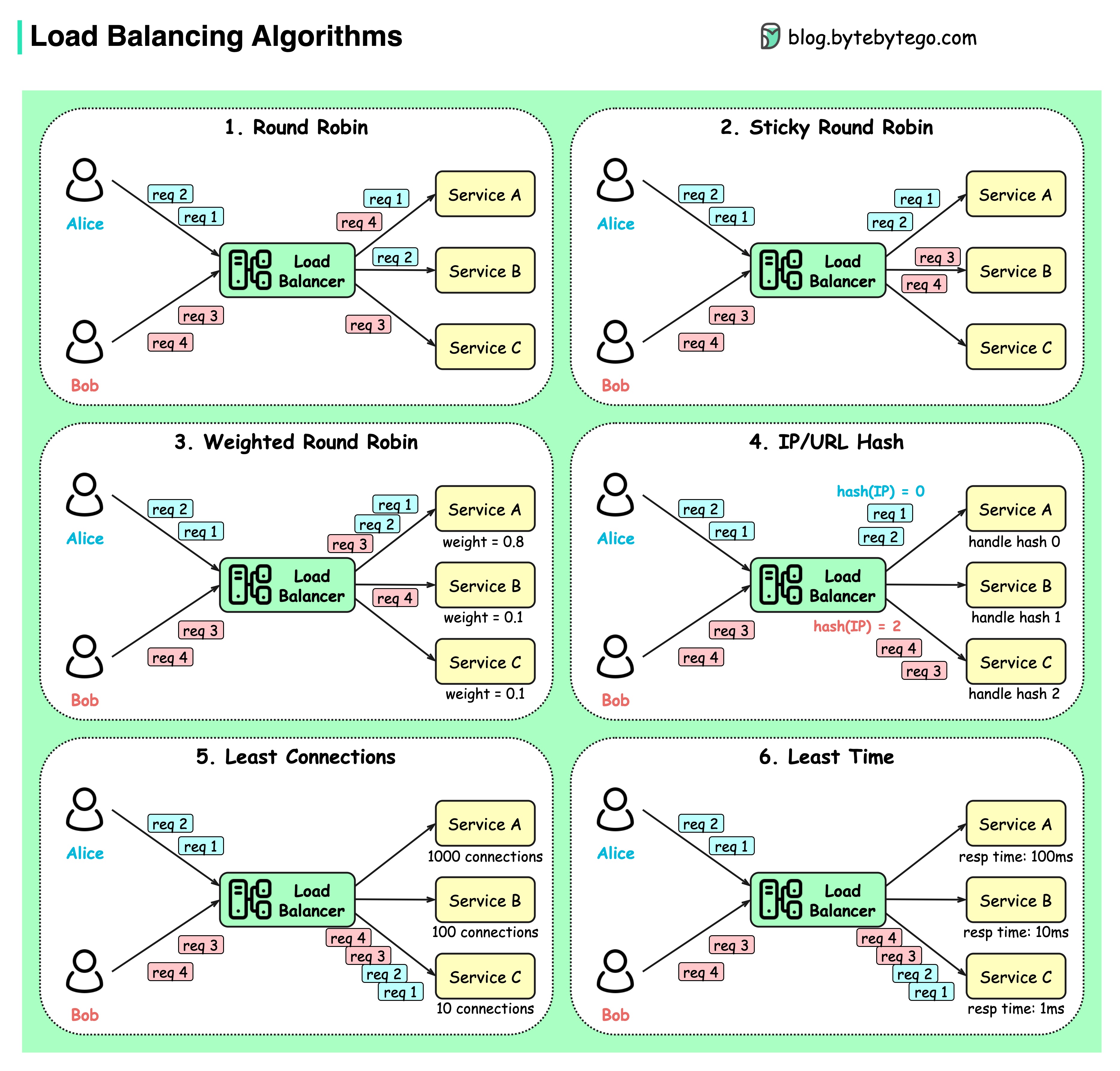
Tournoi à la ronde
Les demandes des clients sont envoyées à différentes instances de service dans un ordre séquentiel. Les services doivent généralement être apatrides.
Tournoi à la ronde collant
Il s’agit d’une amélioration de l’algorithme round-robin. Si la première requête d'Alice va au service A, les requêtes suivantes vont également au service A.
Tournoi circulaire pondéré
L'administrateur peut spécifier le poids de chaque service. Ceux avec un poids plus élevé traitent plus de demandes que les autres.
Hacher
Cet algorithme applique une fonction de hachage sur l'IP ou l'URL des requêtes entrantes. Les requêtes sont acheminées vers les instances pertinentes en fonction du résultat de la fonction de hachage.
Moins de connexions
Une nouvelle demande est envoyée à l'instance de service avec le moins de connexions simultanées.
Temps de réponse minimum
Une nouvelle demande est envoyée à l'instance de service avec le temps de réponse le plus rapide.
Le diagramme ci-dessous montre une comparaison de l'URL, de l'URI et de l'URN.
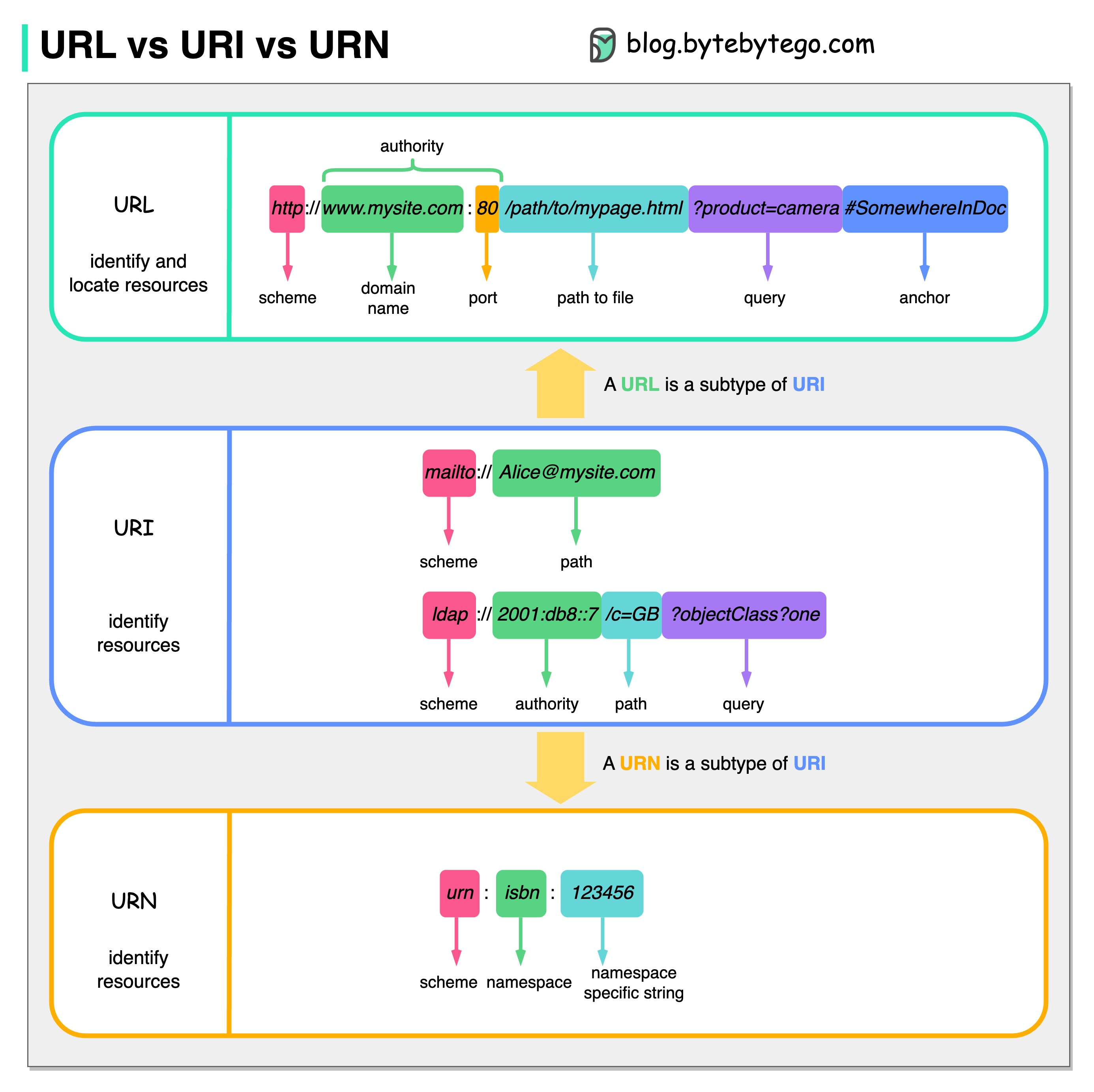
URI signifie Uniform Resource Identifier. Il identifie une ressource logique ou physique sur le Web. L'URL et l'URN sont des sous-types d'URI. L'URL localise une ressource, tandis que l'URN nomme une ressource.
Un URI est composé des parties suivantes : schéma :[//autorité]chemin[?query][#fragment]
URL signifie Uniform Resource Locator, le concept clé de HTTP. C'est l'adresse d'une ressource unique sur le web. Il peut être utilisé avec d'autres protocoles comme FTP et JDBC.
URN signifie Nom de ressource uniforme. Il utilise le schéma de l'urne. Les URN ne peuvent pas être utilisés pour localiser une ressource. Un exemple simple donné dans le diagramme est composé d'un espace de noms et d'une chaîne spécifique à l'espace de noms.
Si vous souhaitez en savoir plus sur le sujet, je recommanderais les éclaircissements du W3C.
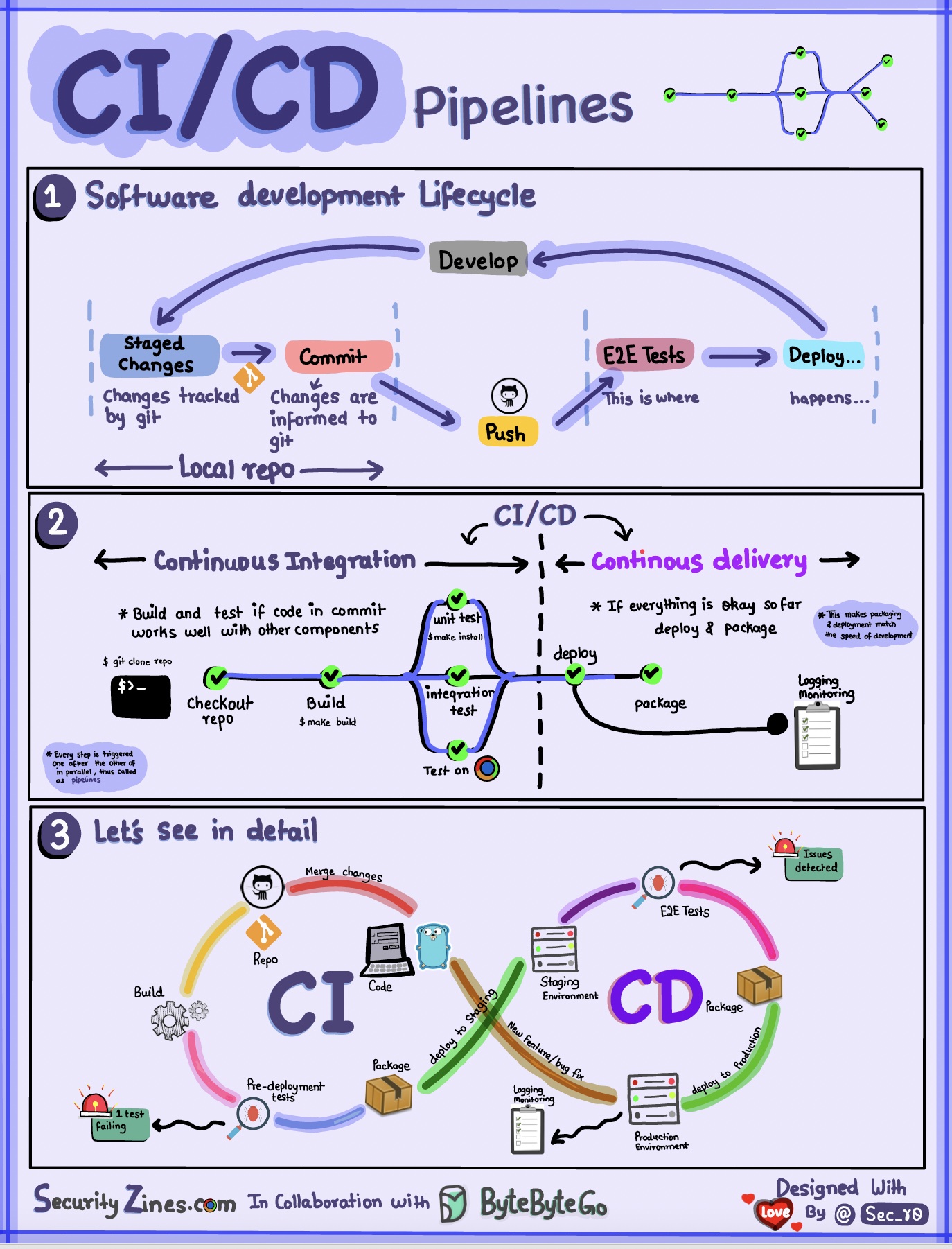
Section 1 – SDLC avec CI/CD
Le cycle de vie du développement logiciel (SDLC) comprend plusieurs étapes clés : développement, tests, déploiement et maintenance. CI/CD automatise et intègre ces étapes pour permettre des versions plus rapides et plus fiables.
Lorsque le code est poussé vers un référentiel git, il déclenche un processus de construction et de test automatisé. Des cas de test de bout en bout (e2e) sont exécutés pour valider le code. Si les tests réussissent, le code peut être automatiquement déployé en préparation/production. Si des problèmes sont détectés, le code est renvoyé au développement pour correction des bogues. Cette automatisation fournit un retour rapide aux développeurs et réduit le risque de bugs en production.
Section 2 - Différence entre CI et CD
L'intégration continue (CI) automatise le processus de création, de test et de fusion. Il exécute des tests chaque fois que le code est validé pour détecter rapidement les problèmes d'intégration. Cela encourage des validations de code fréquentes et des commentaires rapides.
La livraison continue (CD) automatise les processus de publication tels que les modifications d'infrastructure et le déploiement. Il garantit que les logiciels peuvent être publiés de manière fiable à tout moment grâce à des flux de travail automatisés. Le CD peut également automatiser les étapes de test manuel et d'approbation requises avant le déploiement en production.
Section 3 - Pipeline CI/CD
Un pipeline CI/CD typique comporte plusieurs étapes connectées :
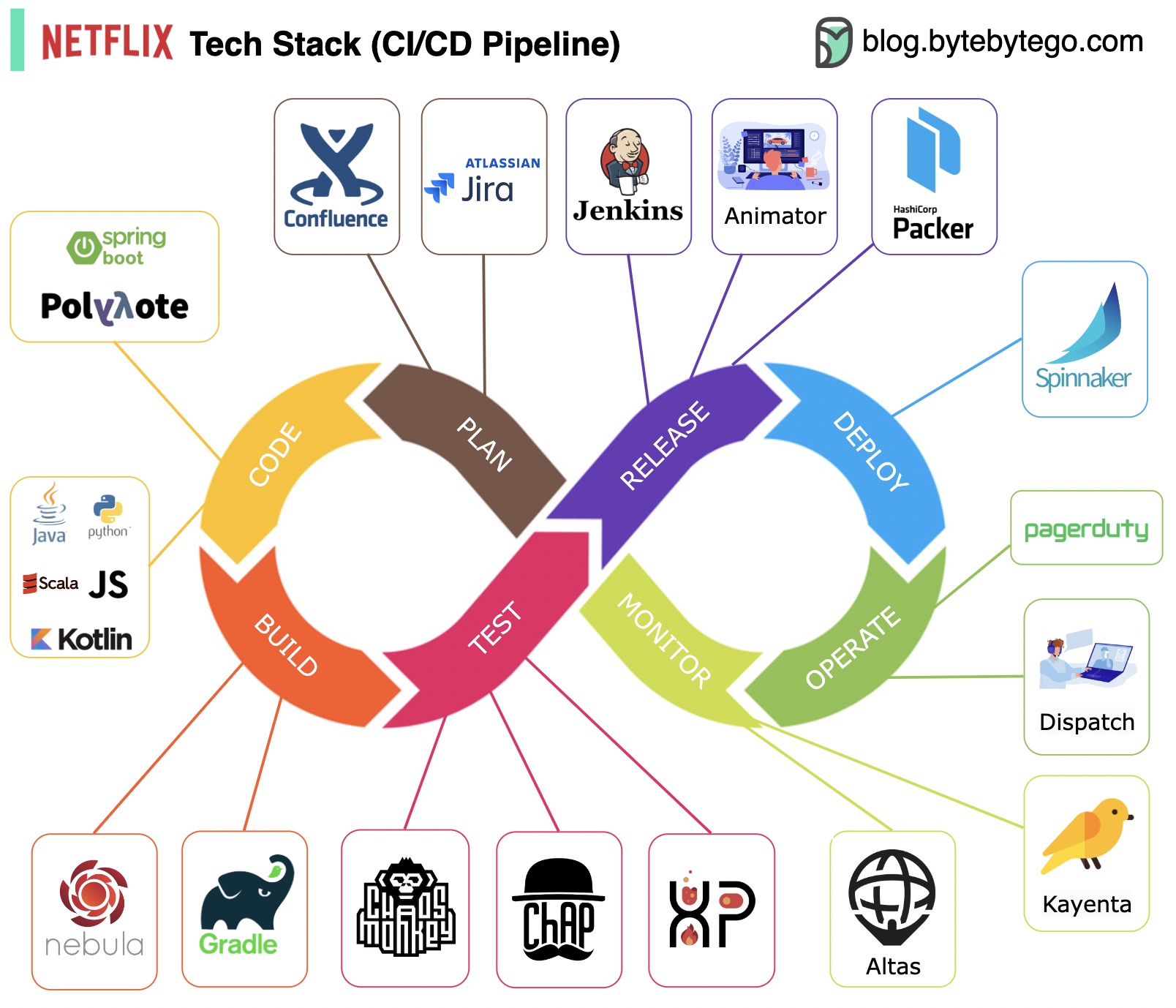
Planification : Netflix Engineering utilise JIRA pour la planification et Confluence pour la documentation.
Codage : Java est le langage de programmation principal du service backend, tandis que d'autres langages sont utilisés pour différents cas d'utilisation.
Build : Gradle est principalement utilisé pour la construction, et les plugins Gradle sont conçus pour prendre en charge divers cas d'utilisation.
Emballage : le package et les dépendances sont emballés dans une Amazon Machine Image (AMI) pour la publication.
Tests : les tests mettent l'accent sur l'accent mis par la culture de production sur la création d'outils de chaos.
Déploiement : Netflix utilise son Spinnaker auto-construit pour le déploiement du déploiement Canary.
Surveillance : Les métriques de surveillance sont centralisées dans Atlas et Kayenta est utilisé pour détecter les anomalies.
Rapport d'incident : les incidents sont répartis selon la priorité et PagerDuty est utilisé pour la gestion des incidents.
Ces modèles d'architecture sont parmi les plus couramment utilisés dans le développement d'applications, que ce soit sur les plateformes iOS ou Android. Les développeurs les ont introduits pour surmonter les limitations des modèles antérieurs. Alors, en quoi diffèrent-ils ?
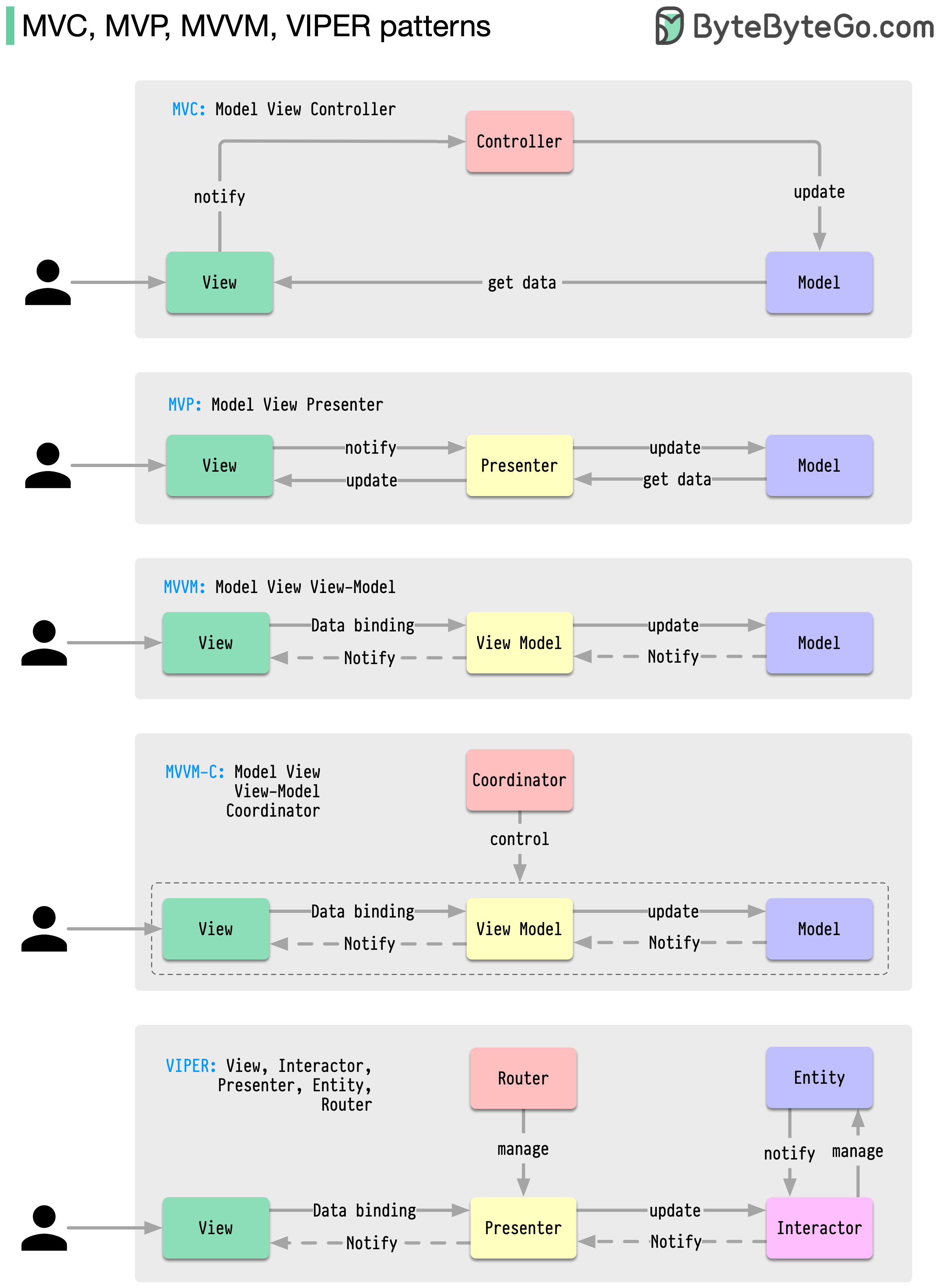
Les modèles sont des solutions réutilisables à des problèmes de conception courants, permettant un processus de développement plus fluide et plus efficace. Ils servent de modèles pour créer de meilleures structures logicielles. Voici quelques-uns des modèles les plus populaires :

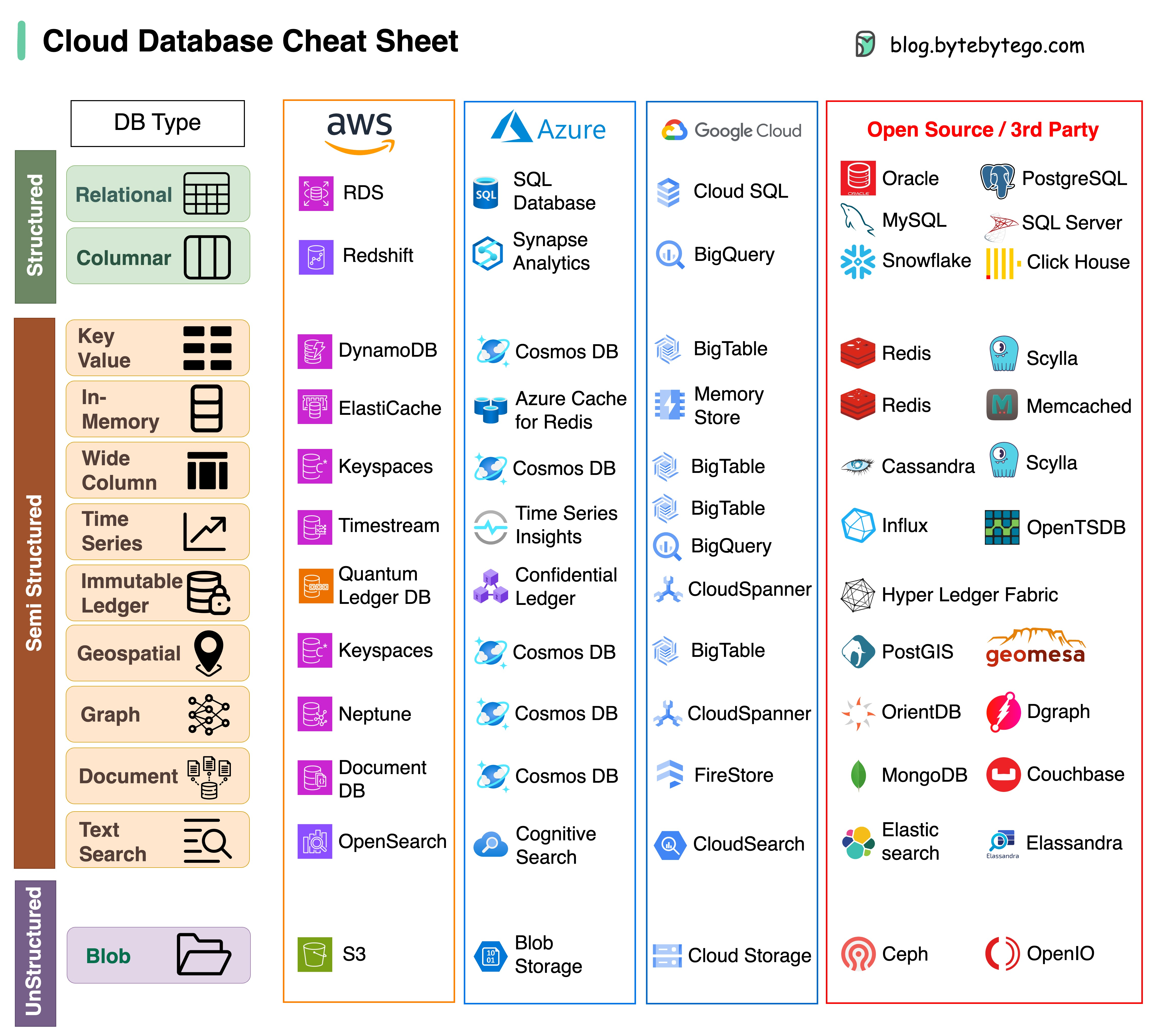
Choisir la bonne base de données pour votre projet est une tâche complexe. De nombreuses options de bases de données, chacune adaptée à des cas d’utilisation distincts, peuvent rapidement conduire à une lassitude décisionnelle.
Nous espérons que cette aide-mémoire fournira des instructions de haut niveau pour identifier le bon service qui correspond aux besoins de votre projet et éviter les pièges potentiels.
Remarque : Google dispose d'une documentation limitée pour ses cas d'utilisation de bases de données. Même si nous avons fait de notre mieux pour examiner ce qui était disponible et sommes parvenus à la meilleure option, certaines entrées devront peut-être être plus précises.
La réponse variera en fonction de votre cas d'utilisation. Les données peuvent être indexées en mémoire ou sur disque. De même, les formats de données varient, tels que les nombres, les chaînes, les coordonnées géographiques, etc. Le système peut être lourd en écriture ou en lecture. Tous ces facteurs affectent votre choix de format d'index de base de données.
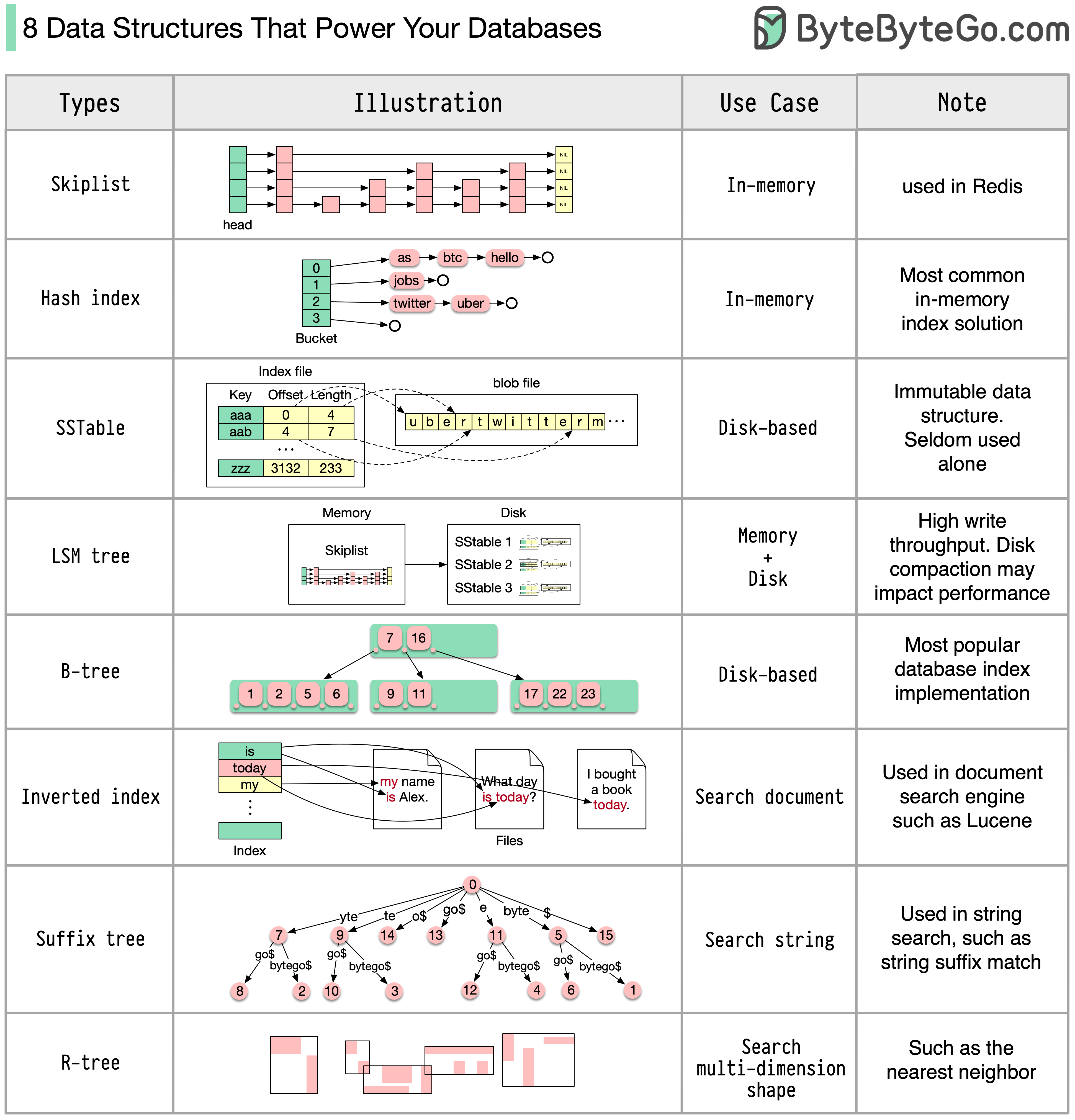
Voici quelques-unes des structures de données les plus couramment utilisées pour l'indexation des données :
Le diagramme ci-dessous montre le processus. Notez que les architectures des différentes bases de données sont différentes, le diagramme montre certaines conceptions courantes.
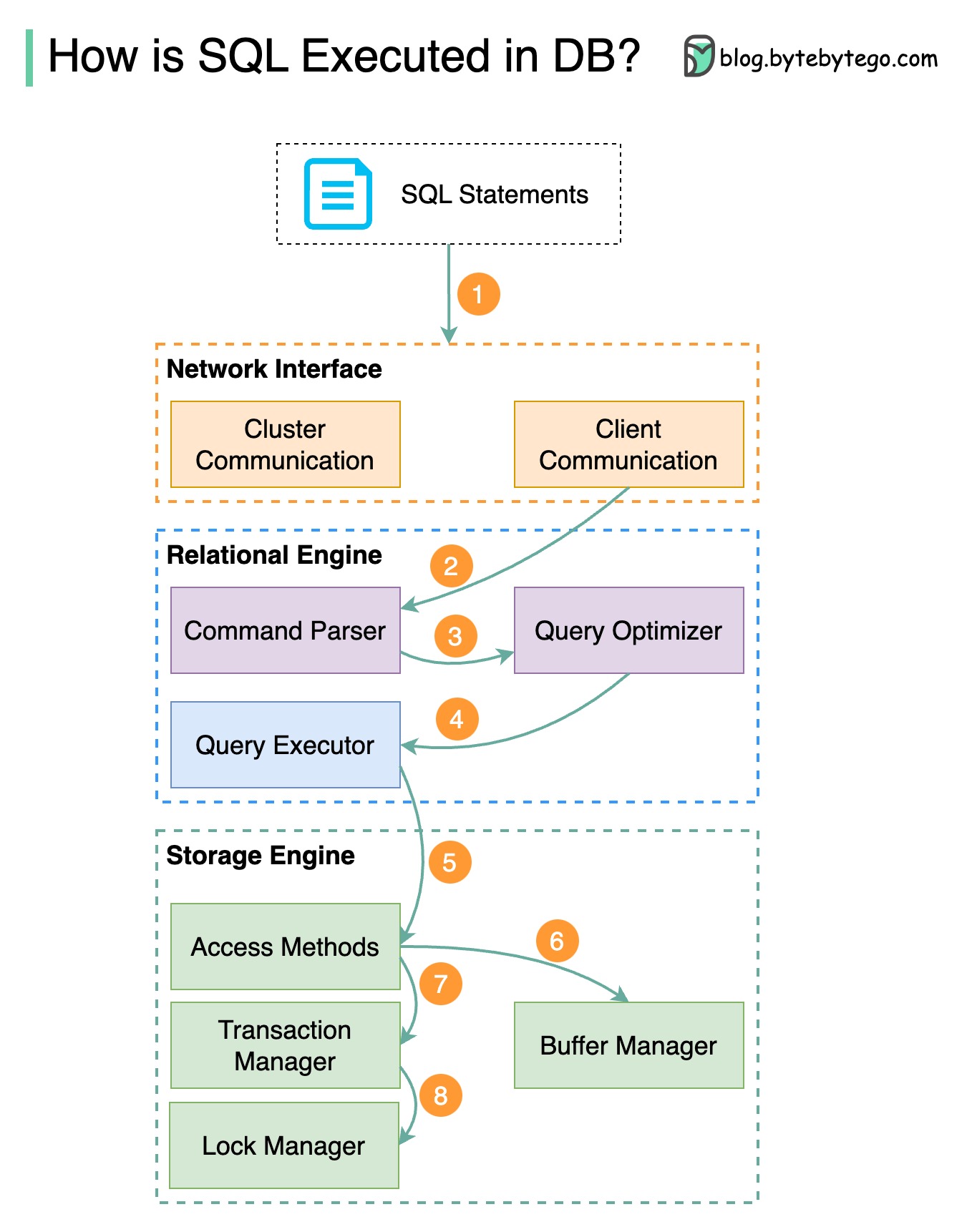
Étape 1 - Une instruction SQL est envoyée à la base de données via un protocole de couche transport (par exemple TCP).
Étape 2 - L'instruction SQL est envoyée à l'analyseur de commandes, où elle passe par une analyse syntaxique et sémantique, et une arborescence de requêtes est ensuite générée.
Étape 3 - L'arborescence des requêtes est envoyée à l'optimiseur. L'optimiseur crée un plan d'exécution.
Étape 4 - Le plan d'exécution est envoyé à l'exécuteur testamentaire. L'exécuteur récupère les données de l'exécution.
Étape 5 - Les méthodes d'accès fournissent la logique de récupération des données requise pour l'exécution, en récupérant les données du moteur de stockage.
Étape 6 - Les méthodes d'accès décident si l'instruction SQL est en lecture seule. Si la requête est en lecture seule (instruction SELECT), elle est transmise au gestionnaire de tampon pour un traitement ultérieur. Le gestionnaire de tampon recherche les données dans le cache ou les fichiers de données.
Étape 7 - Si l'instruction est une UPDATE ou un INSERT, elle est transmise au gestionnaire de transactions pour un traitement ultérieur.
Étape 8 - Lors d'une transaction, les données sont en mode verrouillé. Ceci est garanti par le gestionnaire de serrures. Il garantit également les propriétés ACID de la transaction.
Le théorème CAP est l’un des termes les plus connus en informatique, mais je parie que différents développeurs ont des compréhensions différentes. Examinons de quoi il s'agit et pourquoi cela peut prêter à confusion.
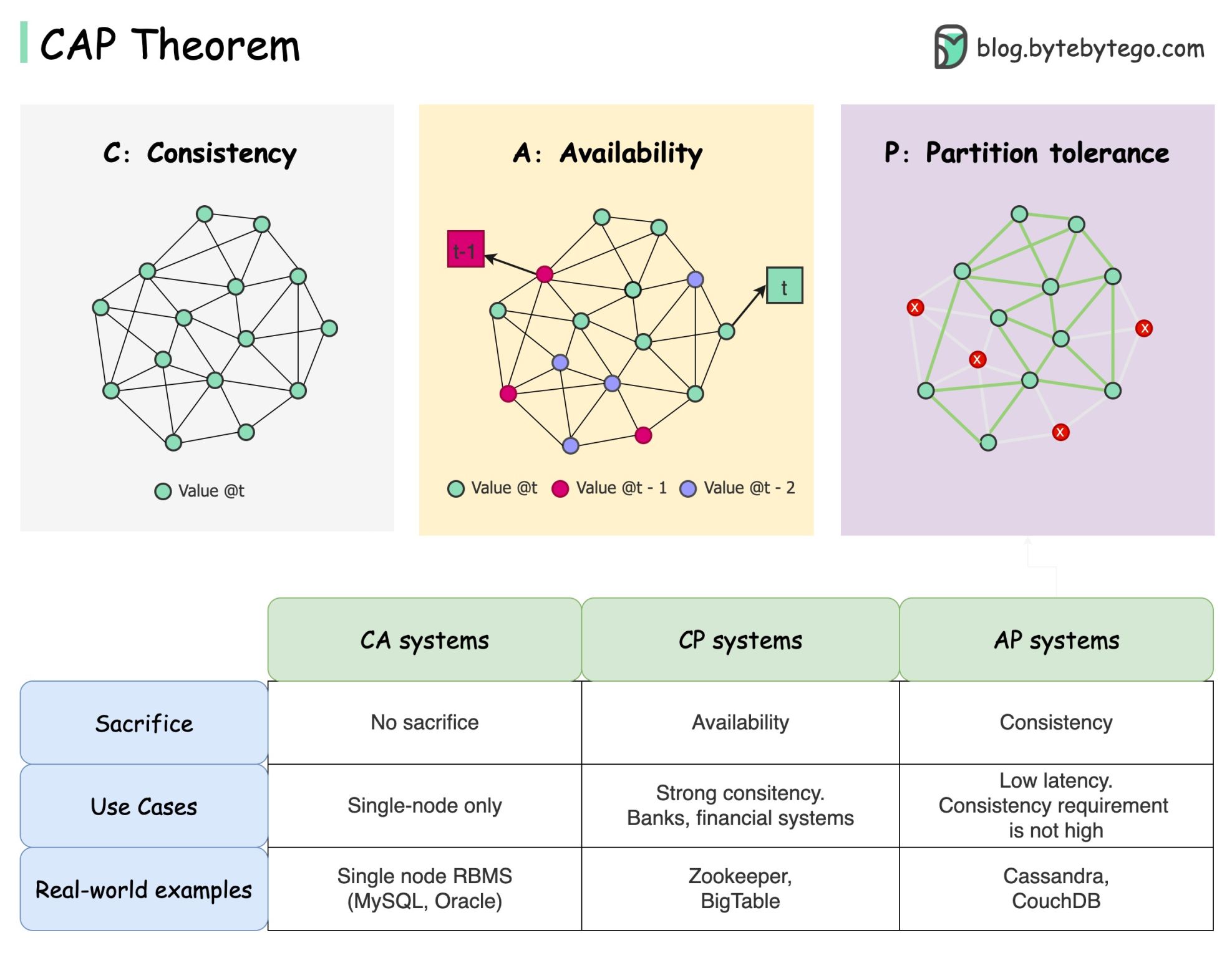
Le théorème CAP stipule qu'un système distribué ne peut pas fournir simultanément plus de deux de ces trois garanties.
Cohérence : la cohérence signifie que tous les clients voient les mêmes données en même temps, quel que soit le nœud auquel ils se connectent.
Disponibilité : la disponibilité signifie que tout client qui demande des données obtient une réponse même si certains nœuds sont en panne.
Partition Tolerance : une partition indique une rupture de communication entre deux nœuds. La tolérance de partition signifie que le système continue de fonctionner malgré les partitions réseau.
La formulation « 2 sur 3 » peut être utile, mais cette simplification pourrait être trompeuse .
Choisir une base de données n’est pas facile. Justifier notre choix uniquement sur la base du théorème de la PAC ne suffit pas. Par exemple, les entreprises ne choisissent pas Cassandra pour les applications de chat simplement parce qu'il s'agit d'un système AP. Il existe une liste de bonnes caractéristiques qui font de Cassandra une option souhaitable pour stocker les messages de discussion. Nous devons creuser plus profondément.
« Le CAP n'interdit qu'une infime partie de l'espace de conception : disponibilité et cohérence parfaites en présence de cloisons, qui sont rares ». Extrait de l'article : CAP douze ans plus tard : comment les « règles » ont changé.
Le théorème est d’environ 100 % de disponibilité et de cohérence. Une discussion plus réaliste porterait sur les compromis entre latence et cohérence lorsqu'il n'y a pas de partition réseau. Voir le théorème PACELC pour plus de détails.
Le théorème du CAP est-il réellement utile ?
Je pense que cela reste utile car cela ouvre notre esprit à une série de discussions de compromis, mais ce n’est qu’une partie de l’histoire. Nous devons creuser plus profondément lors du choix de la bonne base de données.
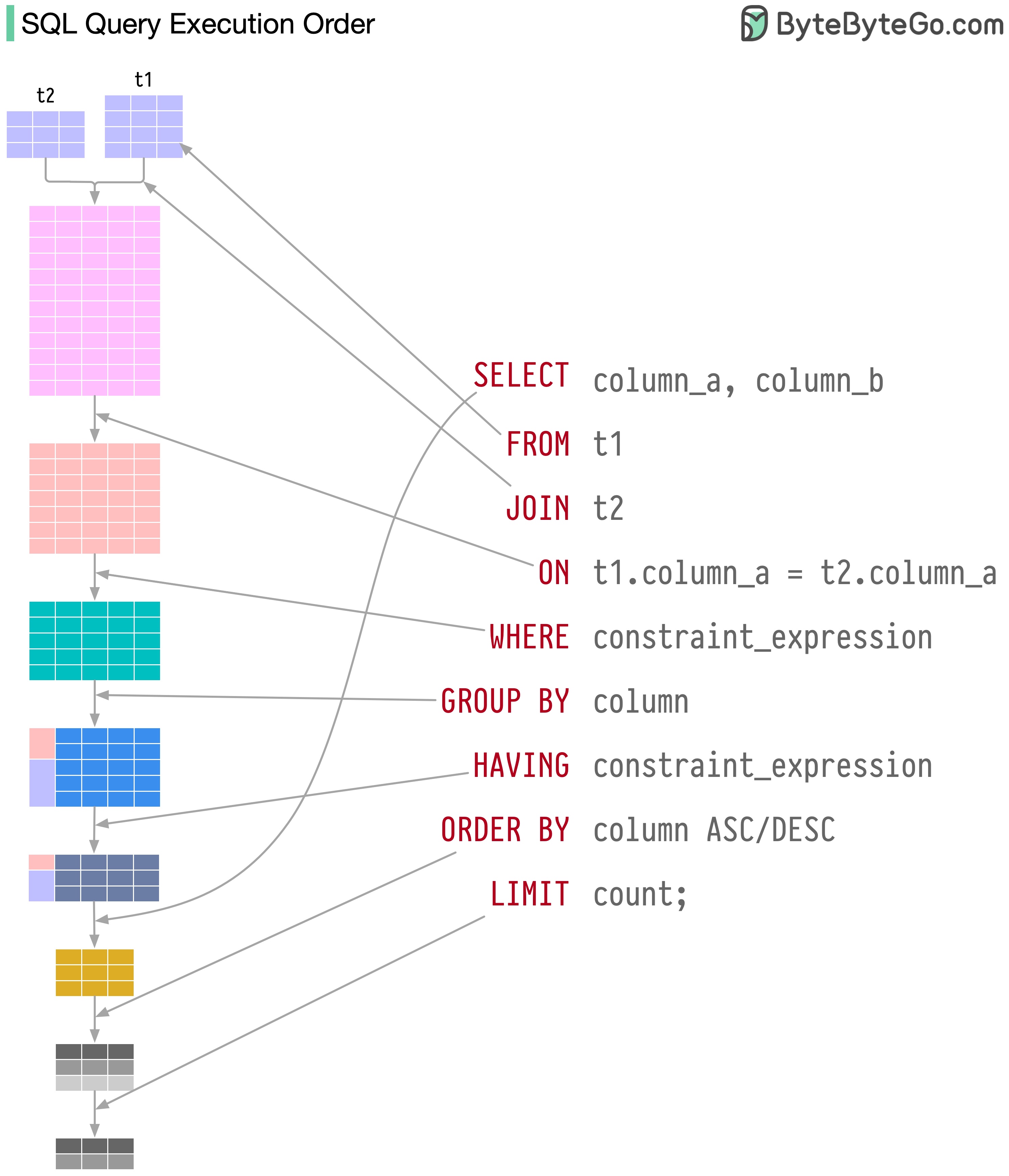
Les instructions SQL sont exécutées par le système de base de données en plusieurs étapes, notamment :
L'exécution de SQL est très complexe et implique de nombreuses considérations, telles que :
En 1986, SQL (Structured Query Language) est devenu un standard. Au cours des 40 années suivantes, il est devenu le langage dominant pour les systèmes de gestion de bases de données relationnelles. La lecture de la dernière norme (ANSI SQL 2016) peut prendre beaucoup de temps. Comment puis-je l'apprendre ?
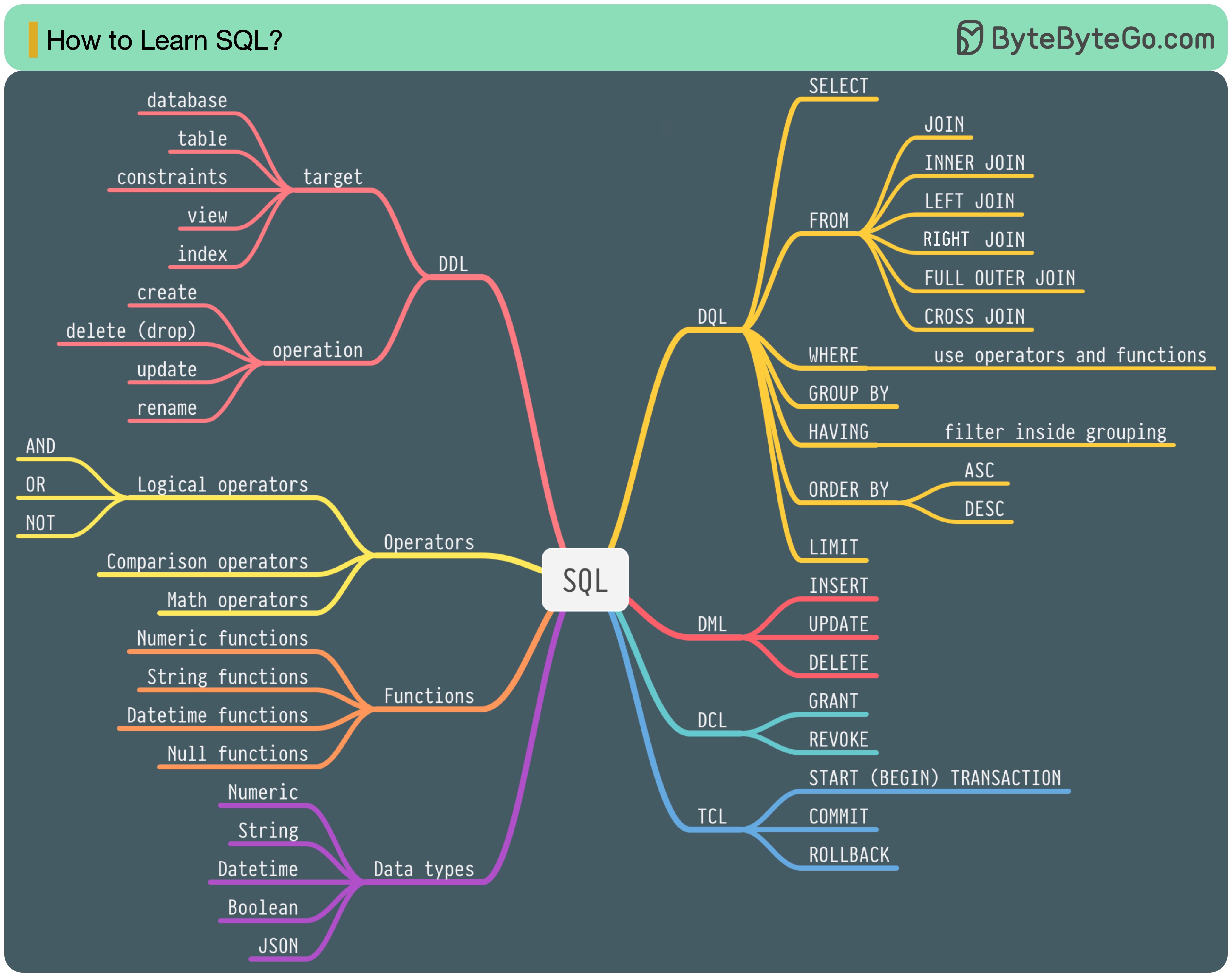
Il existe 5 composants du langage SQL :
Pour un ingénieur backend, vous devrez peut-être en connaître la plupart. En tant qu'analyste de données, vous devrez peut-être avoir une bonne compréhension de DQL. Sélectionnez les sujets qui vous intéressent le plus.
Ce diagramme illustre où nous mettons en cache les données dans une architecture typique.
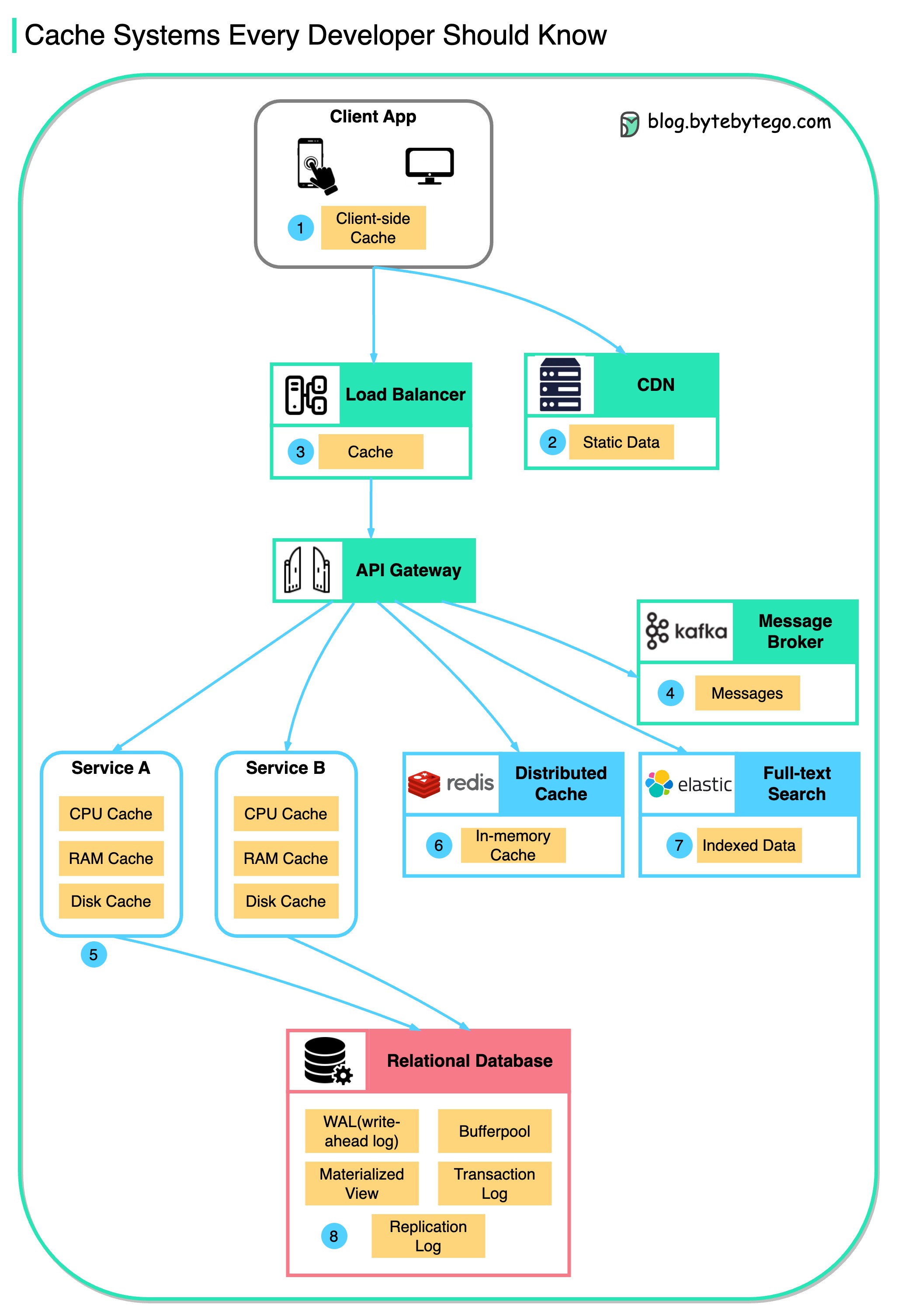
Il y a plusieurs couches le long du flux.
Il y a 3 raisons principales comme le montre le schéma ci-dessous.
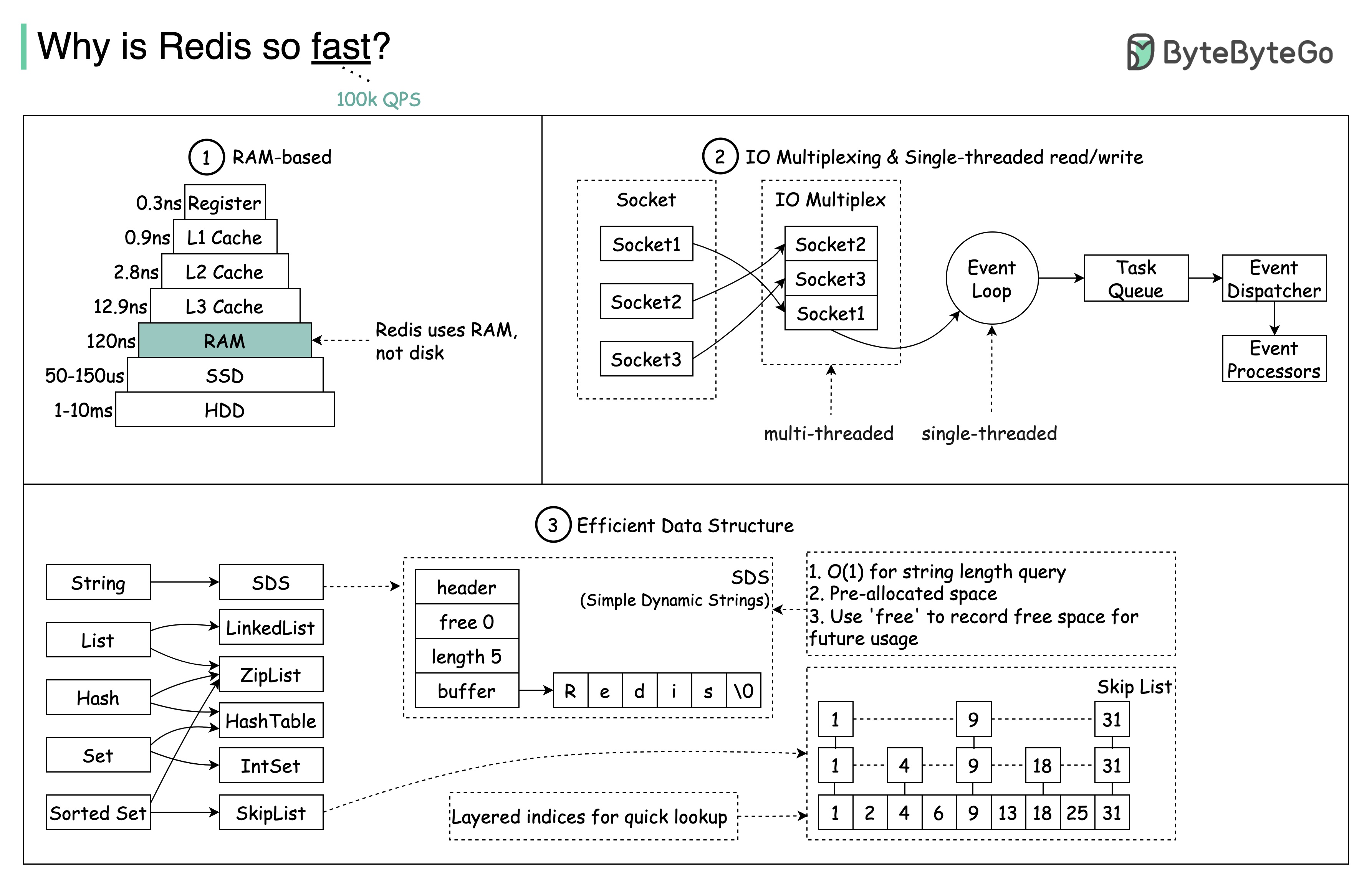
Question : Memcached est un autre magasin de mémoire populaire. Connaissez-vous les différences entre Redis et Memcached ?
Vous avez peut-être remarqué que le style de ce diagramme est différent de mes messages précédents. S'il vous plaît laissez-moi savoir lequel vous préférez.
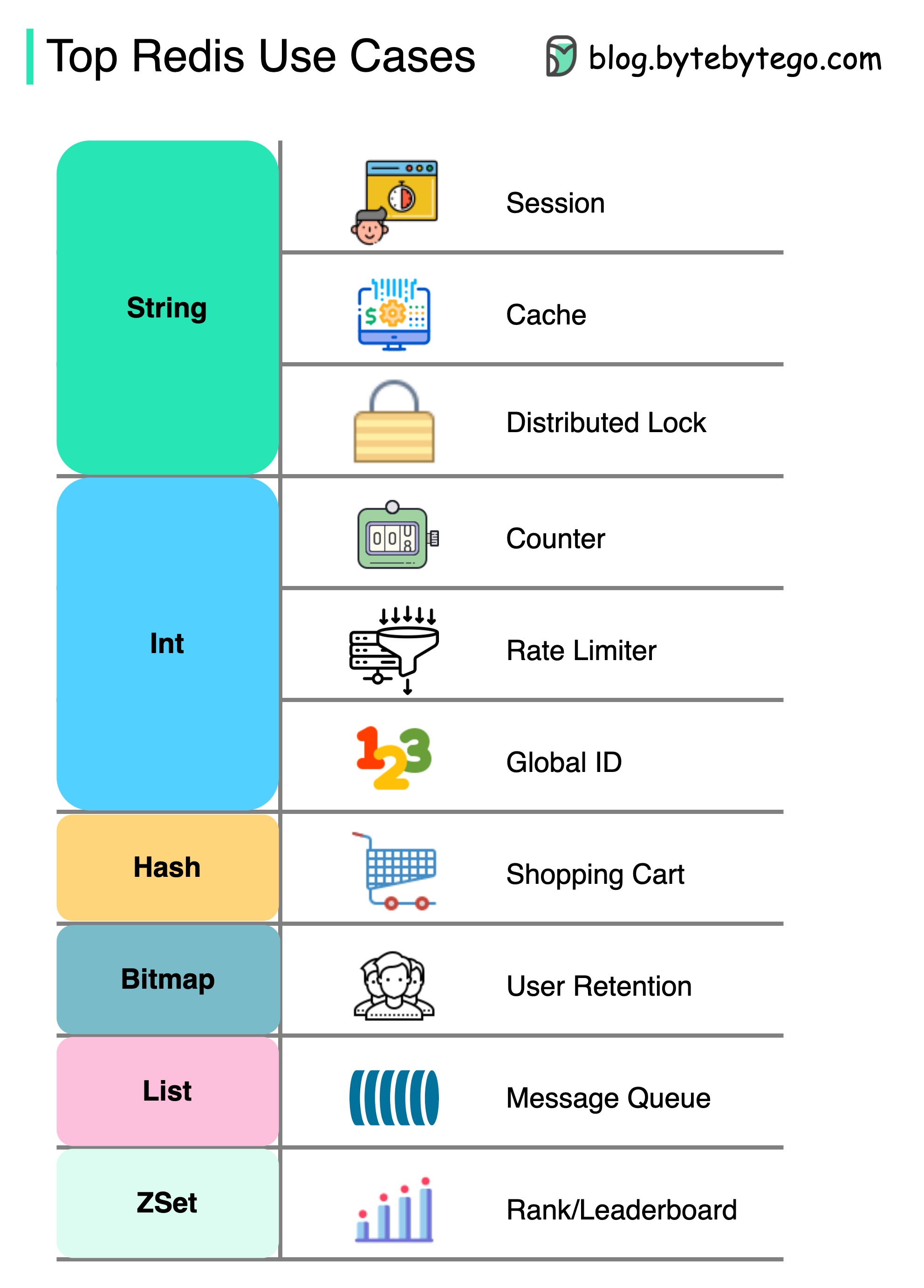
Il y a plus à redis que la simple mise en cache.
Redis peut être utilisé dans une variété de scénarios comme indiqué dans le diagramme.
Session
Nous pouvons utiliser Redis pour partager les données de session utilisateur entre différents services.
Cache
Nous pouvons utiliser Redis pour mettre en cache des objets ou des pages, en particulier pour les données Hotspot.
Verrouillage distribué
Nous pouvons utiliser une chaîne Redis pour acquérir des verrous entre les services distribués.
Comptoir
Nous pouvons compter combien de likes ou combien de lectures pour les articles.
Limiteur de taux
Nous pouvons appliquer un limiteur de taux pour certains IP utilisateur.
Générateur d'identité global
Nous pouvons utiliser Redis int pour Global ID.
Panier
Nous pouvons utiliser Redis Hash pour représenter les paires de valeurs clés dans un panier d'achat.
Calculer la rétention des utilisateurs
Nous pouvons utiliser Bitmap pour représenter quotidiennement la connexion de l'utilisateur et calculer la rétention des utilisateurs.
File d'attente de messages
Nous pouvons utiliser la liste pour une file d'attente de messages.
Classement
Nous pouvons utiliser ZSET pour trier les articles.
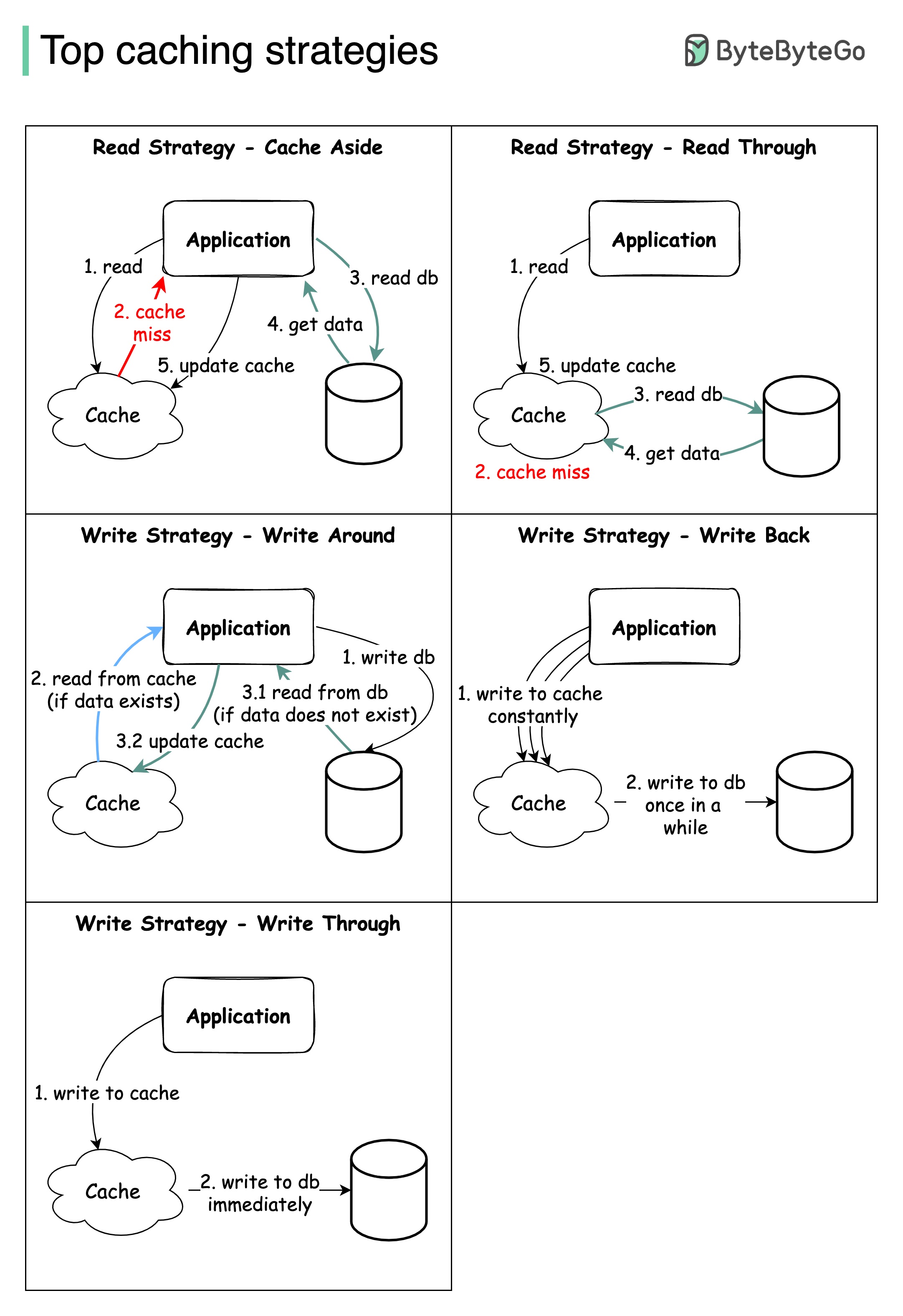
La conception de systèmes à grande échelle nécessite généralement une attention particulière à la mise en cache. Vous trouverez ci-dessous cinq stratégies de mise en cache qui sont fréquemment utilisées.
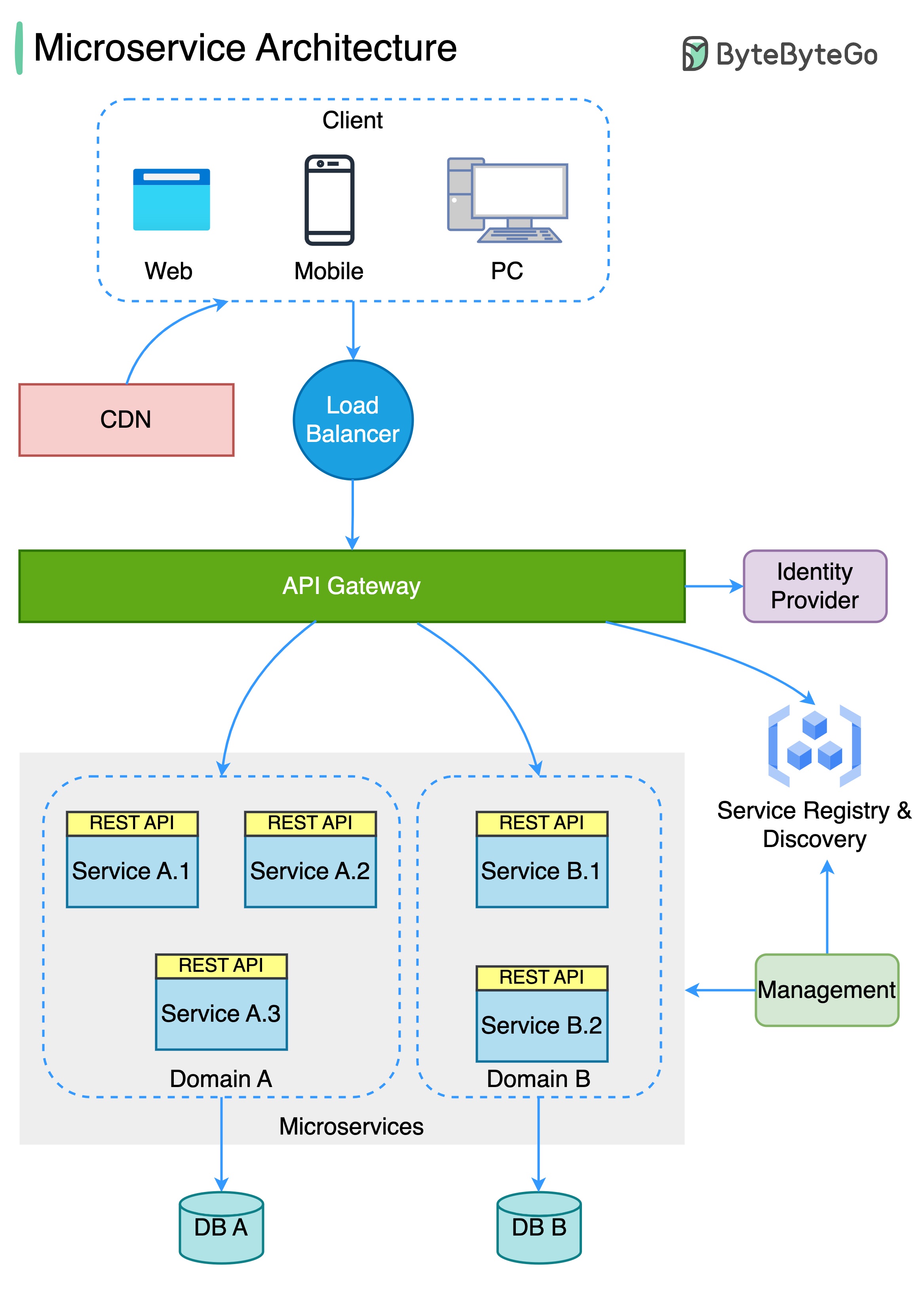
Le diagramme ci-dessous montre une architecture de microservice typique.
Avantages des microservices:
Une image vaut mille mots: 9 meilleures pratiques pour développer des microservices.
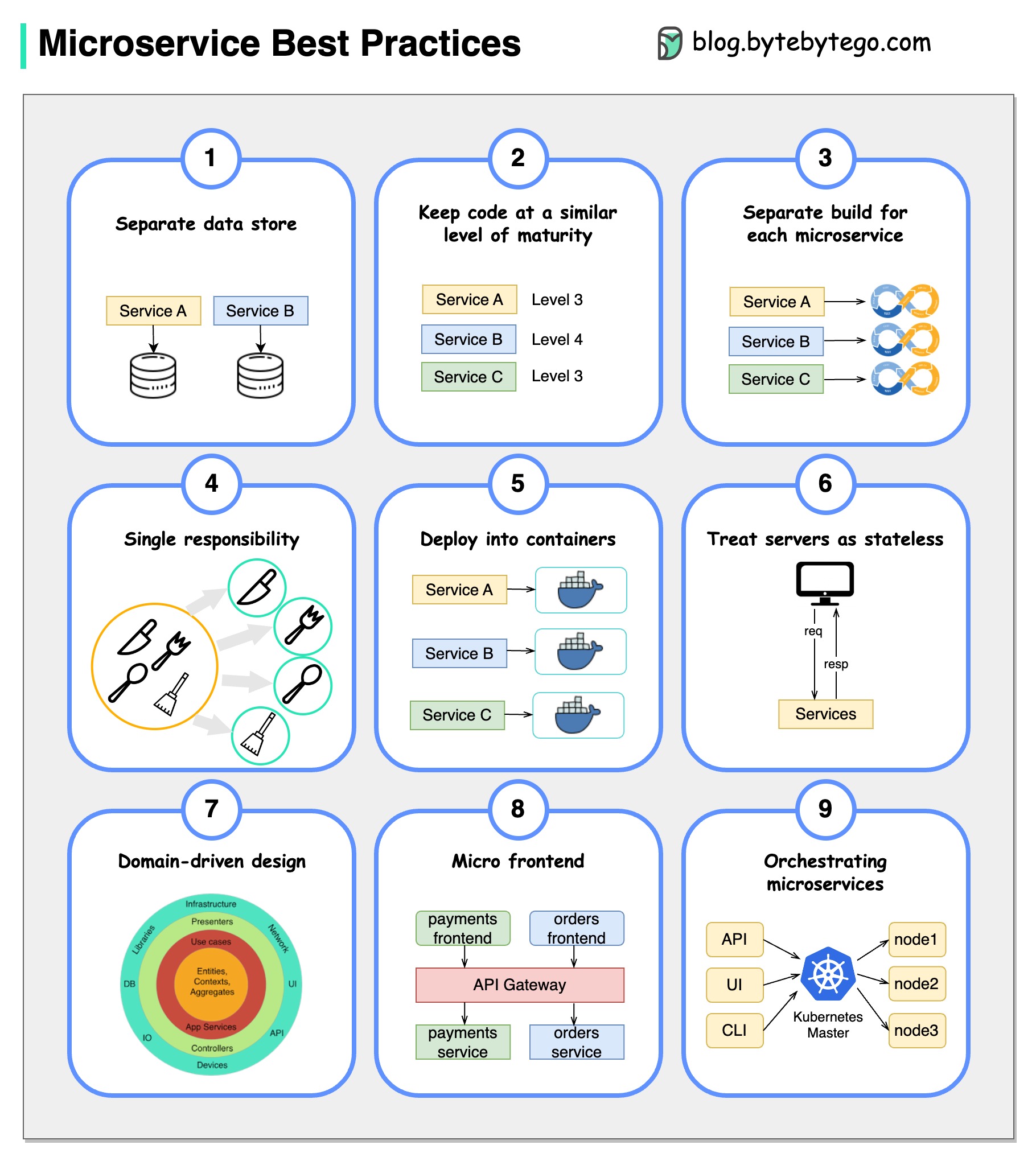
Lorsque nous développons des microservices, nous devons suivre les meilleures pratiques suivantes:
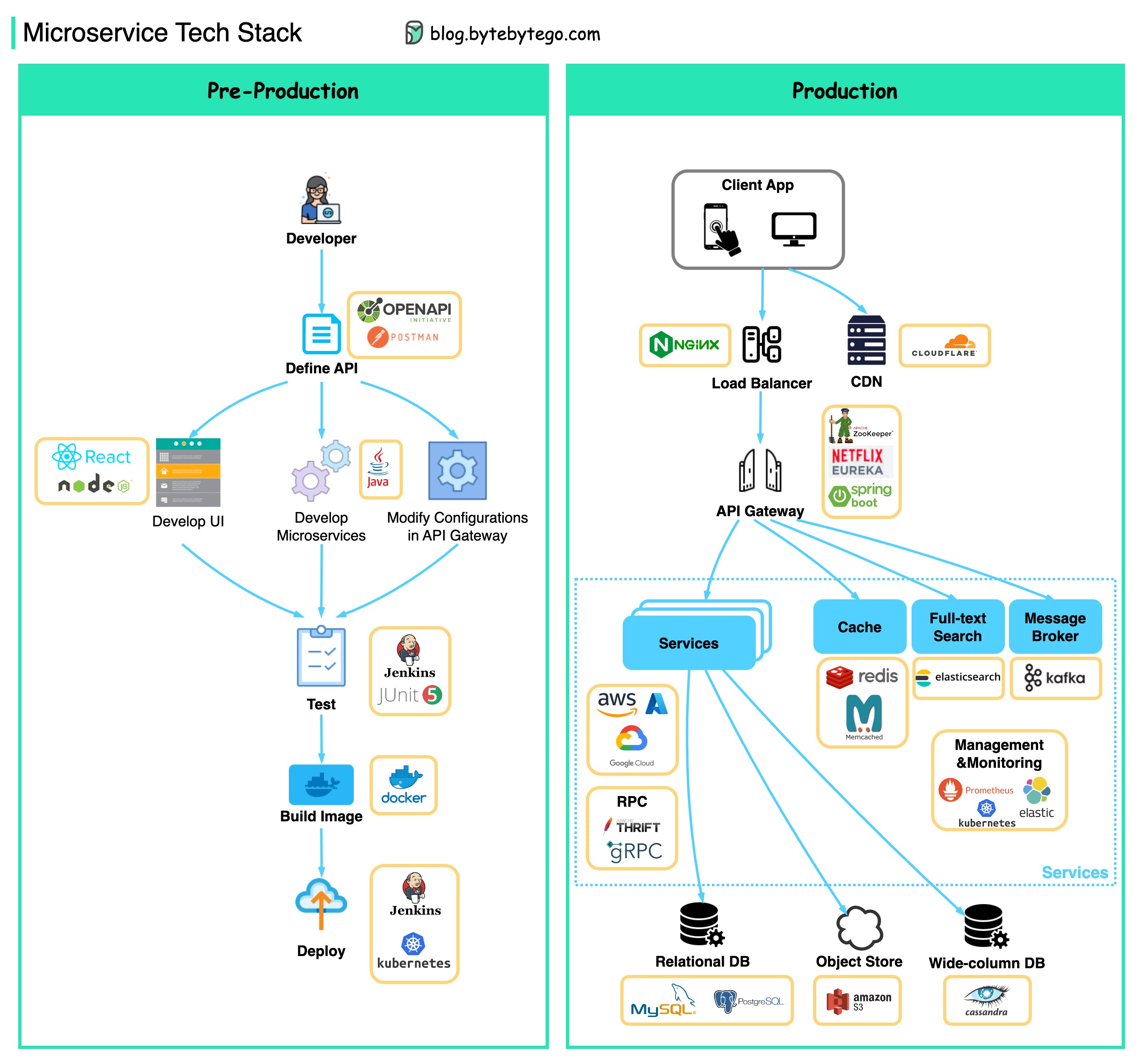
Ci-dessous, vous trouverez un diagramme montrant la pile technologique de microservice, à la fois pour la phase de développement et pour la production.
Il existe de nombreuses décisions de conception qui ont contribué à la performance de Kafka. Dans cet article, nous nous concentrerons sur deux. Nous pensons que ces deux-là ont le plus de poids.
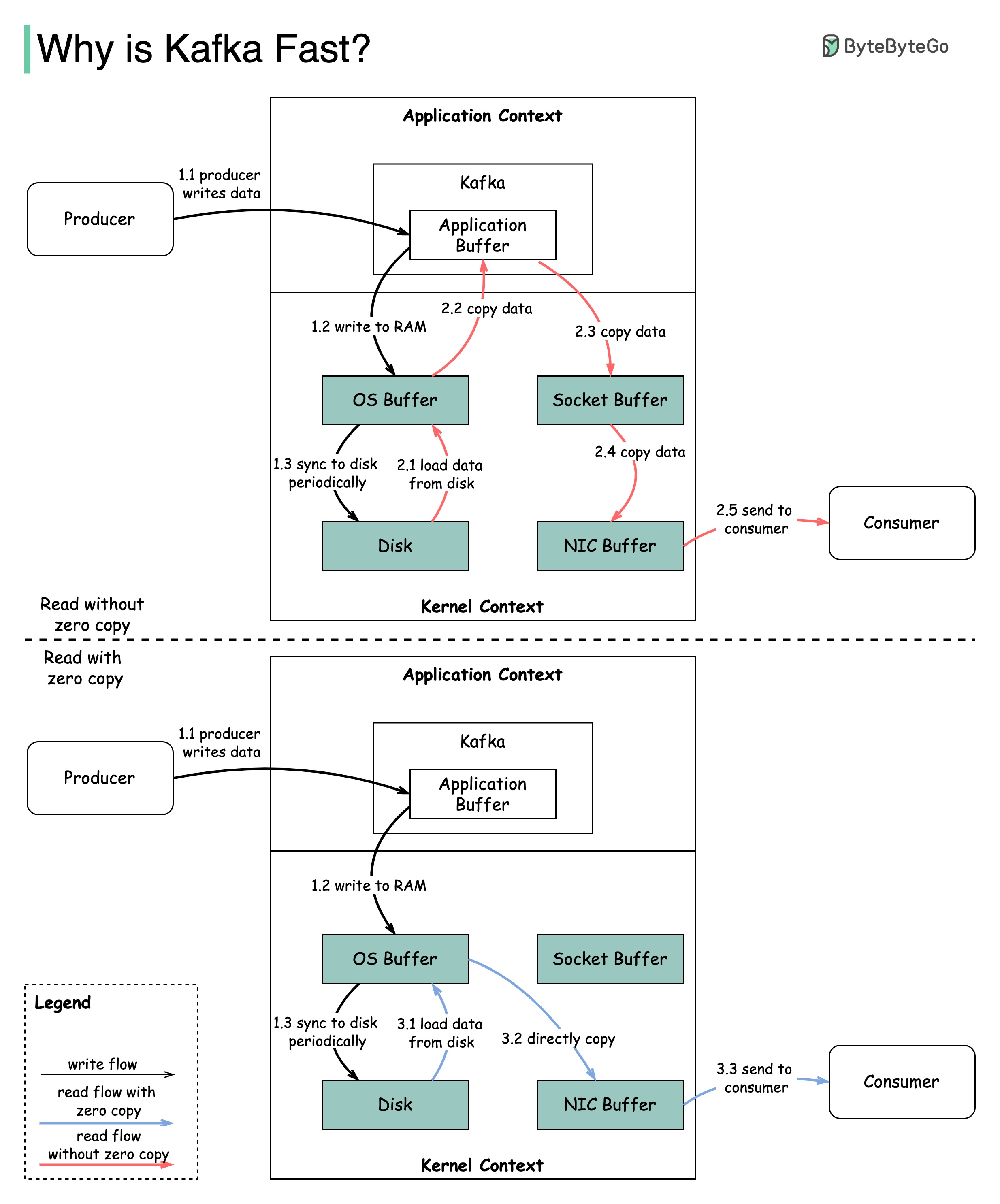
Le diagramme illustre comment les données sont transmises entre le producteur et le consommateur, et ce que signifie la copie zéro.
2.1 Les données sont chargées du disque au cache OS
2.2 Les données sont copiées du Cache OS à l'application Kafka
2.3 L'application Kafka copie les données dans le tampon de socket
2.4 Les données sont copiées du tampon de socket à la carte réseau
2.5 La carte réseau envoie des données au consommateur
3.1: Les données sont chargées du disque au Cache du système d'exploitation 3.2 Cache OS Cache directement les données de la carte réseau via SendFile () Commande 3.3 La carte réseau envoie des données au consommateur
Zero Copy est un raccourci pour enregistrer les multiples copies de données entre le contexte de l'application et le contexte du noyau.
Le diagramme ci-dessous montre l'économie du flux de paiement par carte de crédit.
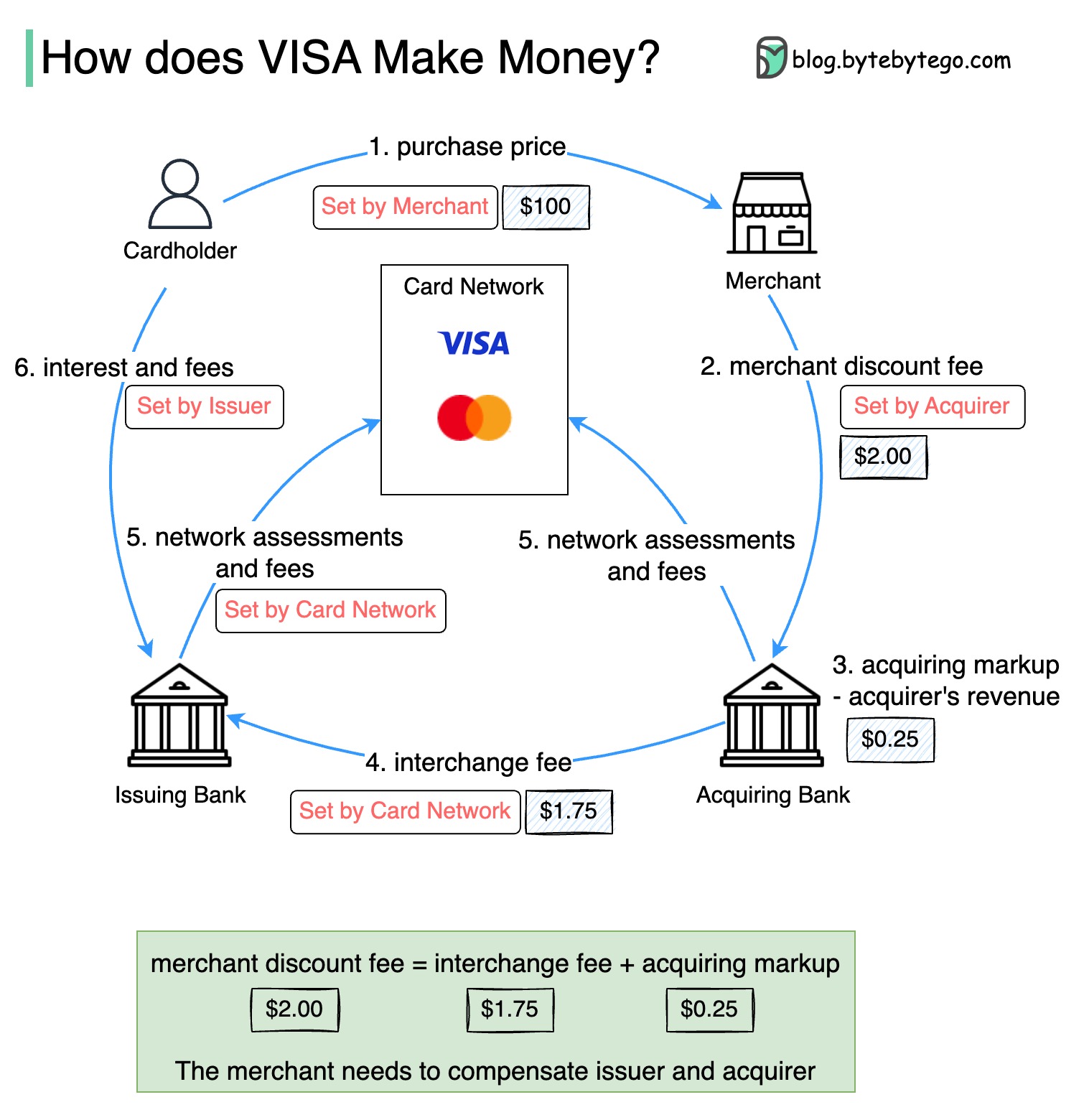
1. Le titulaire de la carte paie 100 $ marchand pour acheter un produit.
2. Le commerçant bénéficie de l'utilisation de la carte de crédit avec un volume de vente plus élevé et doit compenser l'émetteur et le réseau de cartes pour fournir le service de paiement. La banque acquéreuse fixe des frais avec le marchand, appelé «frais de réduction des marchands».
3 - 4. La banque acquéreuse conserve 0,25 $ en tant que majoration acquise, et 1,75 $ est versé à la banque émettrice en tant que frais d'échange. Les frais de réduction des marchands devraient couvrir les frais d'échange.
Les frais d'interchange sont fixés par le réseau de cartes car il est moins efficace pour chaque banque émettrice de négocier des frais avec chaque commerçant.
5. Le réseau de cartes met en place les évaluations et les frais de réseau avec chaque banque, qui paie le réseau de cartes pour ses services chaque mois. Par exemple, Visa facture une évaluation de 0,11%, plus des frais d'utilisation de 0,0195 $, pour chaque balayage.
6. Le titulaire de la carte paie la banque émettrice pour ses services.
Pourquoi la banque émettrice devrait-elle être indemnisée?
Visa, MasterCard et American Express agissent comme des réseaux de cartes pour la compensation et le règlement des fonds. La banque d'acquisition de carte et la banque émettrice de la carte peuvent être - et sont souvent - différentes. Si les banques devaient régler les transactions une par une sans intermédiaire, chaque banque devrait régler les transactions avec toutes les autres banques. C'est assez inefficace.
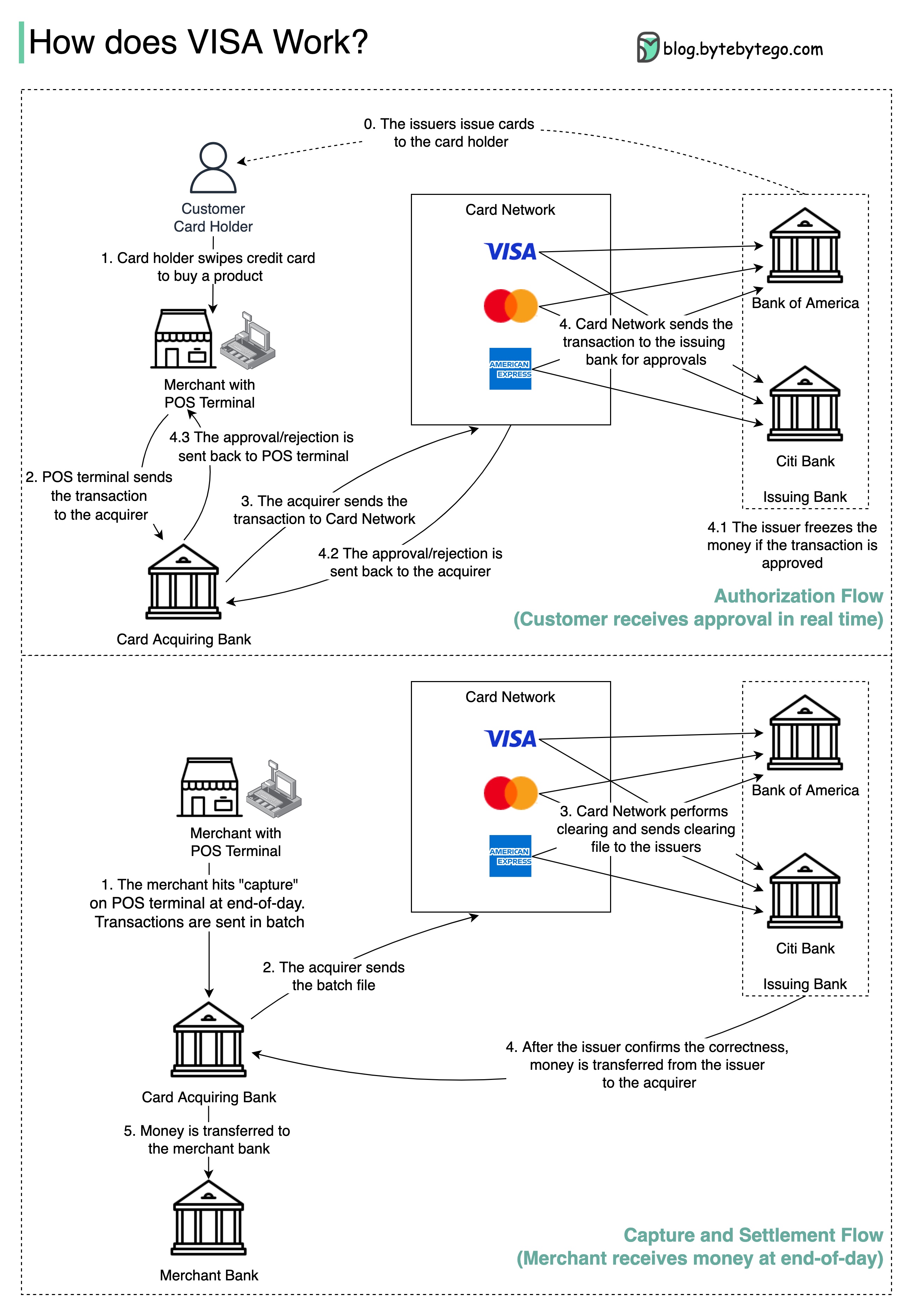
Le diagramme ci-dessous montre le rôle de Visa dans le processus de paiement par carte de crédit. Il y a deux flux impliqués. Le flux d'autorisation se produit lorsque le client glisse la carte de crédit. Le flux de capture et de règlement se produit lorsque le marchand veut obtenir l'argent à la fin de la journée.
Étape 0: La carte émettant la banque émet des cartes de crédit à ses clients.
Étape 1: Le titulaire de la carte souhaite acheter un produit et glisser la carte de crédit au terminal de point de vente (POS) dans la boutique du marchand.
Étape 2: Le terminal POS envoie la transaction à la banque acquéreuse, qui a fourni le terminal POS.
Étapes 3 et 4: La banque acquéreuse envoie la transaction au réseau de cartes, également appelé le schéma de cartes. Le réseau de cartes envoie la transaction à la banque émettrice pour approbation.
Étapes 4.1, 4.2 et 4.3: La banque émettrice gèle l'argent si la transaction est approuvée. L'approbation ou le rejet est renvoyé à l'acquéreur, ainsi que le terminal POS.
Étapes 1 et 2: Le marchand veut collecter l'argent à la fin de la journée, alors ils ont frappé «capture» sur le terminal POS. Les transactions sont envoyées à l'acquéreur en lot. L'acquéreur envoie le fichier batch avec des transactions au réseau de cartes.
Étape 3: Le réseau de cartes effectue une compensation pour les transactions collectées auprès de différents acquéreurs et envoie les fichiers de compensation à différentes banques émettrices.
Étape 4: Les banques émettrices confirment l'exactitude des dossiers de compensation et transfèrent de l'argent aux banques acquéreuses concernées.
Étape 5: La banque acquéreuse transfère ensuite de l'argent à la banque du marchand.
Étape 4: Le réseau de cartes clarifie les transactions de différentes banques acquéreuses. La compensation est un processus dans lequel les transactions de décalage mutuel sont effectuées, de sorte que le nombre de transactions totales est réduite.
Dans le processus, le réseau de cartes prend le fardeau de parler à chaque banque et reçoit des frais de service en retour.
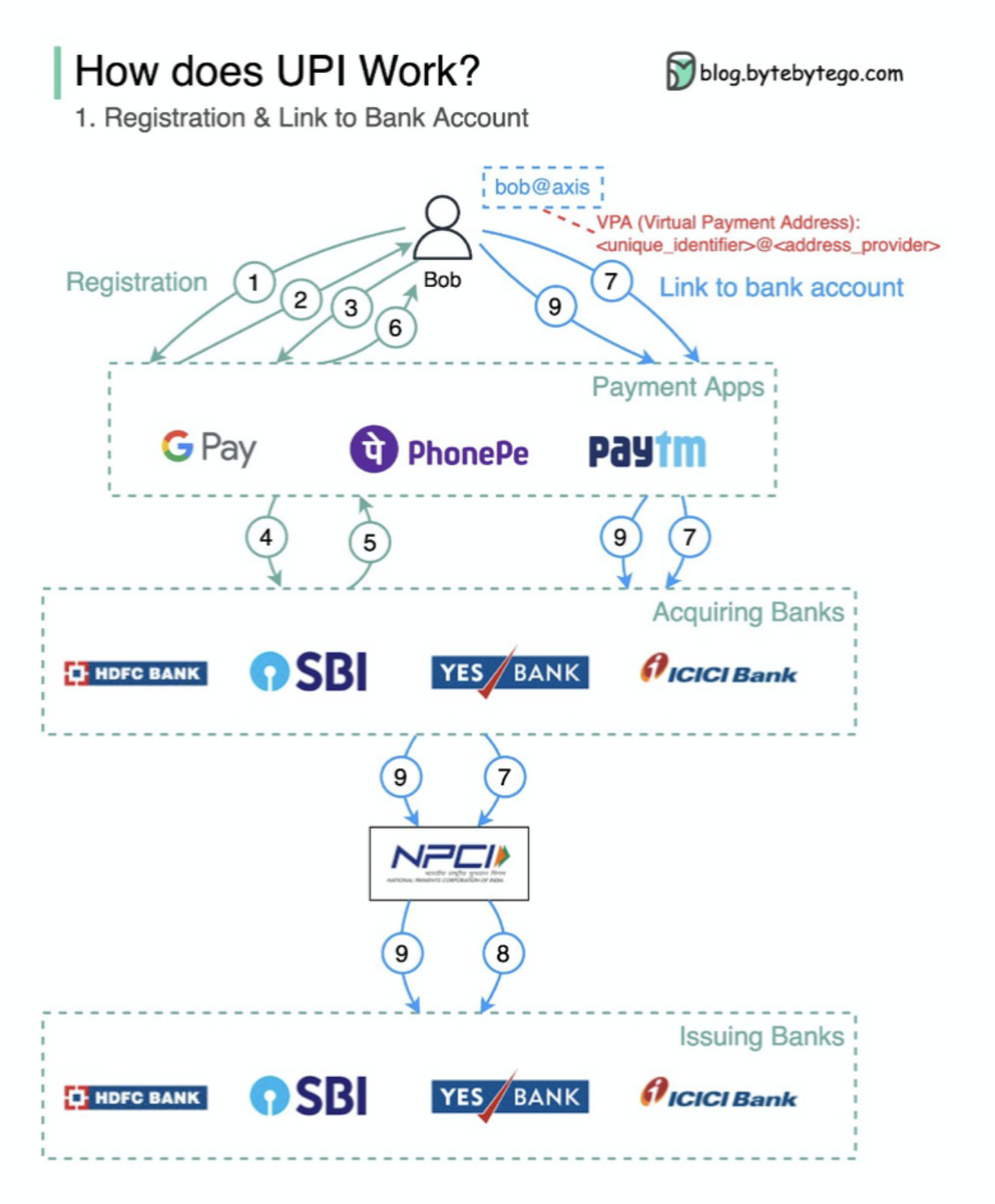
Qu'est-ce que UPI? UPI est un système de paiement en temps réel instantané développé par la National Payments Corporation of India.
Il représente aujourd'hui 60% des transactions de vente au détail numérique en Inde.
UPI = Langue de balisage de paiement + norme pour les paiements interopérables
Les concepts de DevOps, SRE et de l'ingénierie de la plate-forme ont émergé à différents moments et ont été développés par diverses individus et organisations.
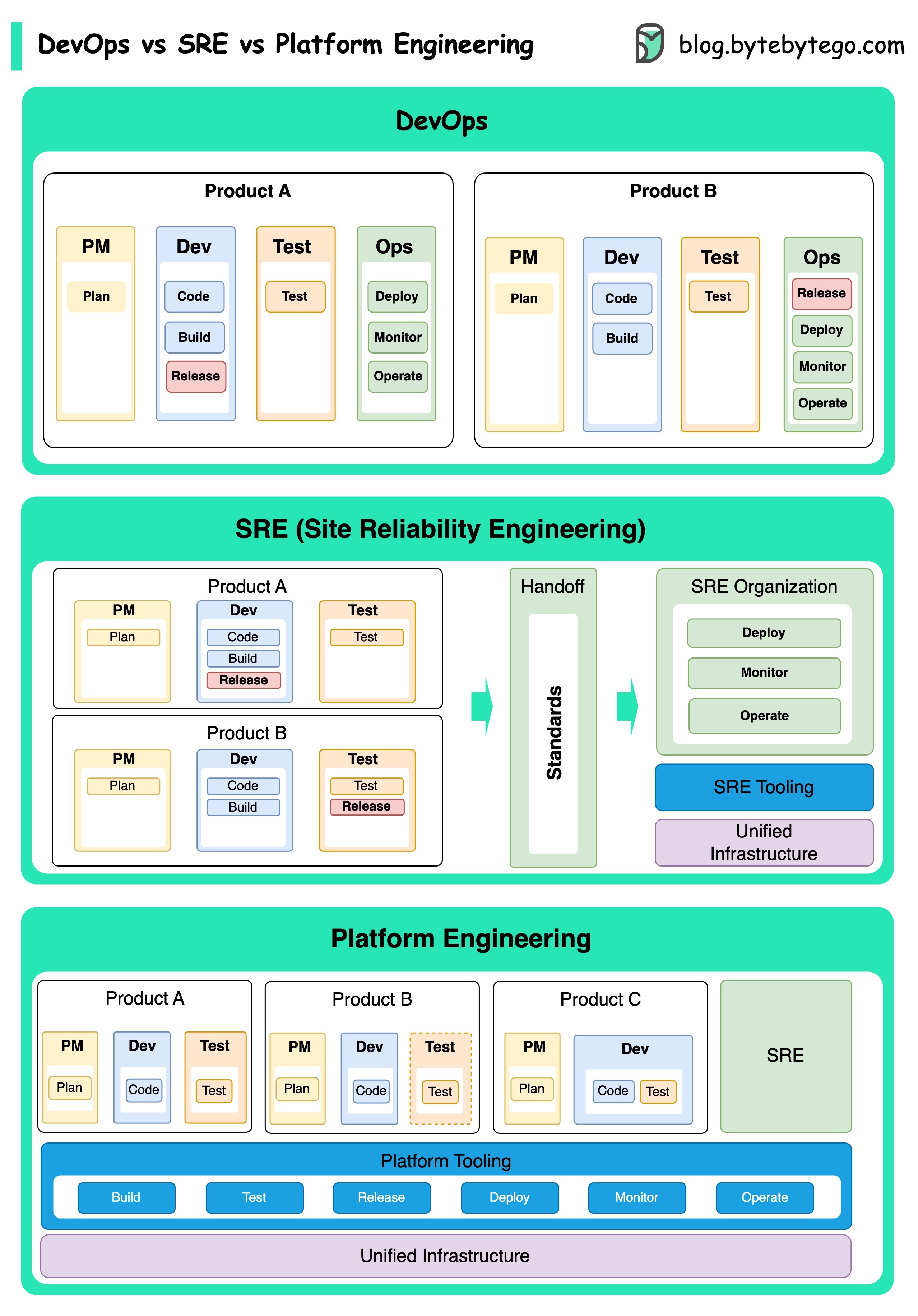
DevOps en tant que concept a été introduit en 2009 par Patrick Debois et Andrew Shafer lors de la conférence Agile. Ils ont cherché à combler le fossé entre le développement de logiciels et les opérations en promouvant une culture collaborative et une responsabilité partagée pour l'ensemble du cycle de vie du développement logiciel.
SRE, ou Ingénierie de fiabilité du site, a été lancé par Google au début des années 2000 pour relever les défis opérationnels dans la gestion des systèmes complexes à grande échelle. Google a développé des pratiques et des outils SRE, tels que le système de gestion des cluster Borg et le système de surveillance Monarch, pour améliorer la fiabilité et l'efficacité de leurs services.
L'ingénierie de la plate-forme est un concept plus récent, en s'appuyant sur les bases de l'ingénierie SRE. Les origines précises de l'ingénierie des plateformes sont moins claires, mais elle est généralement considérée comme une extension des pratiques DevOps et SRE, en mettant l'accent sur la fourniture d'une plate-forme complète pour le développement de produits qui soutient toute la perspective commerciale.
Il convient de noter que si ces concepts ont émergé à différents moments. Ils sont tous liés à la tendance plus large de l'amélioration de la collaboration, de l'automatisation et de l'efficacité du développement et des opérations logicielles.
K8S est un système d'orchestration de conteneurs. Il est utilisé pour le déploiement et la gestion des conteneurs. Sa conception est grandement affectée par le système interne de Google Borg.
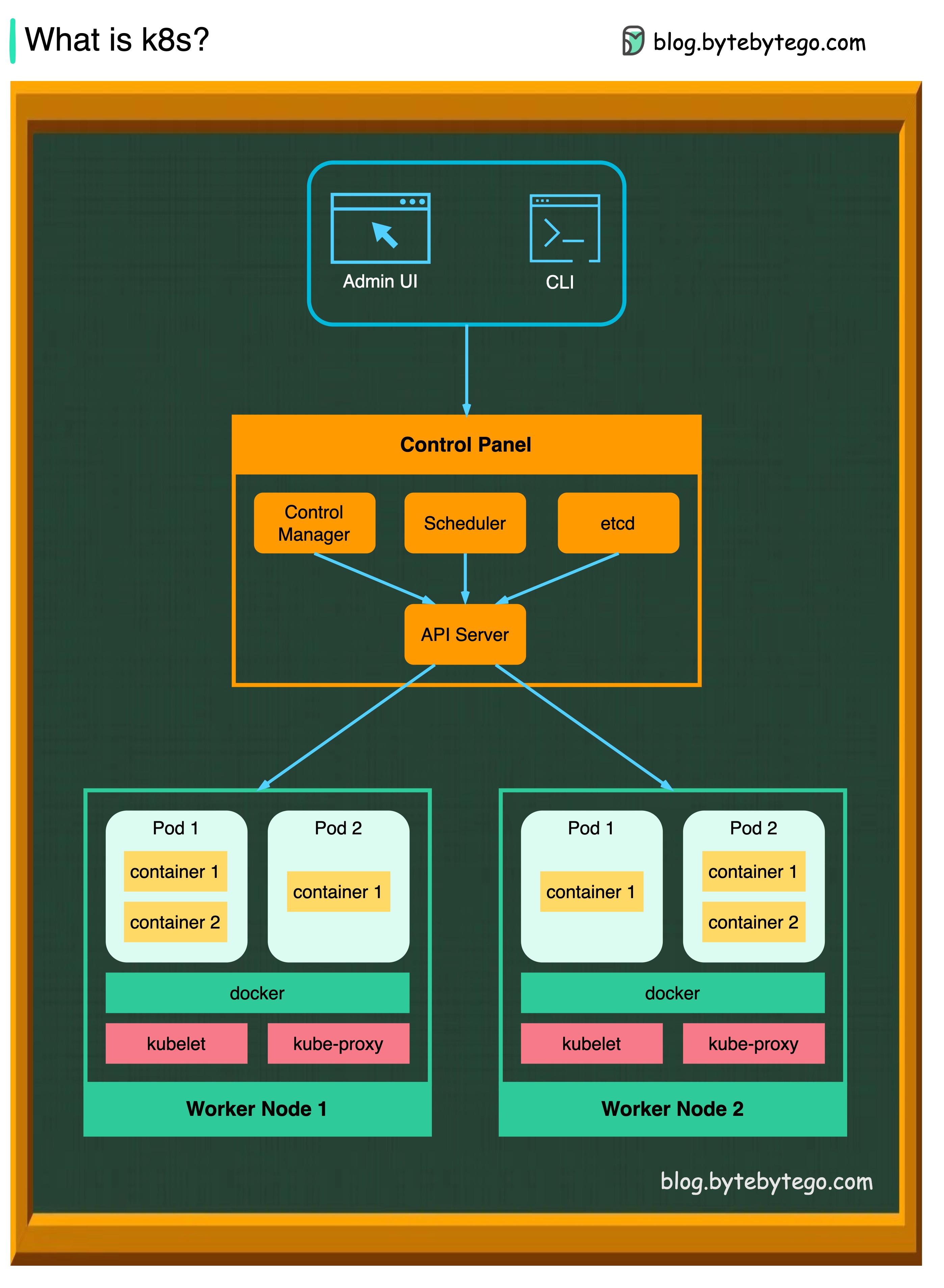
Un cluster K8S se compose d'un ensemble de machines de travailleurs, appelées nœuds, qui exécutent des applications conteneurisées. Chaque cluster a au moins un nœud de travailleur.
Le ou les nœuds de travailleur hébergent les pods qui sont les composants de la charge de travail de l'application. Le plan de contrôle gère les nœuds de travailleur et les gousses du cluster. Dans les environnements de production, le plan de contrôle passe généralement sur plusieurs ordinateurs, et un cluster exécute généralement plusieurs nœuds, offrant une tolérance aux défauts et une haute disponibilité.
Serveur API
Le serveur API parle à tous les composants du cluster K8S. Toutes les opérations sur les pods sont exécutées en parlant au serveur API.
Planificateur
Le planificateur regarde les charges de travail de pod et attribue des charges sur les pods nouvellement créés.
Responsable du contrôleur
Le gestionnaire de contrôleur exécute les contrôleurs, y compris le contrôleur de nœud, le contrôleur de travail, le contrôleur EndPointSlice et le contrôleur ServiceAccount.
Etcd
etcd est un magasin de valeurs de clé utilisé comme magasin de support de Kubernetes pour toutes les données de cluster.
Gousses
Un pod est un groupe de conteneurs et est la plus petite unité que K8s administre. Les pods ont une seule adresse IP appliquée à chaque conteneur dans le pod.
Kublet
Un agent qui s'exécute sur chaque nœud dans le cluster. Il garantit que les conteneurs fonctionnent dans un pod.
Proxy kube
Kube-Proxy est un proxy de réseau qui s'exécute sur chaque nœud de votre cluster. Il achemine le trafic dans un nœud du service. Il transmet des demandes de travail dans les conteneurs corrects.

Qu'est-ce que Docker?
Docker est une plate-forme open source qui vous permet de former, de distribuer et d'exécuter des applications dans des conteneurs isolés. Il se concentre sur la conteneurisation, fournissant des environnements légers qui encapsulent les applications et leurs dépendances.
Qu'est-ce que Kubernetes?
Kubernetes, souvent appelée K8S, est une plate-forme d'orchestration de conteneurs open source. Il fournit un cadre pour automatiser le déploiement, la mise à l'échelle et la gestion des applications conteneurisées sur un groupe de nœuds.
En quoi les deux sont-elles différentes les unes des autres?
Docker: Docker fonctionne au niveau du conteneur individuel sur un seul hôte du système d'exploitation.
Vous devez gérer manuellement chaque hôte et configurer les réseaux, les politiques de sécurité et le stockage pour plusieurs conteneurs associés peuvent être complexes.
Kubernetes: Kubernetes fonctionne au niveau du cluster. Il gère plusieurs applications conteneurisées sur plusieurs hôtes, offrant une automatisation pour des tâches telles que l'équilibrage de charge, la mise à l'échelle et la garantie de l'état des applications souhaité.
En bref, Docker se concentre sur la conteneurisation et l'exécution de conteneurs sur des hôtes individuels, tandis que Kubernetes est spécialisée dans la gestion et l'orchestration des conteneurs à grande échelle dans un groupe d'hôtes.
Le diagramme ci-dessous montre l'architecture de Docker et comment il fonctionne lorsque nous exécutons «Docker Build», «Docker Pull» et «Docker Run».
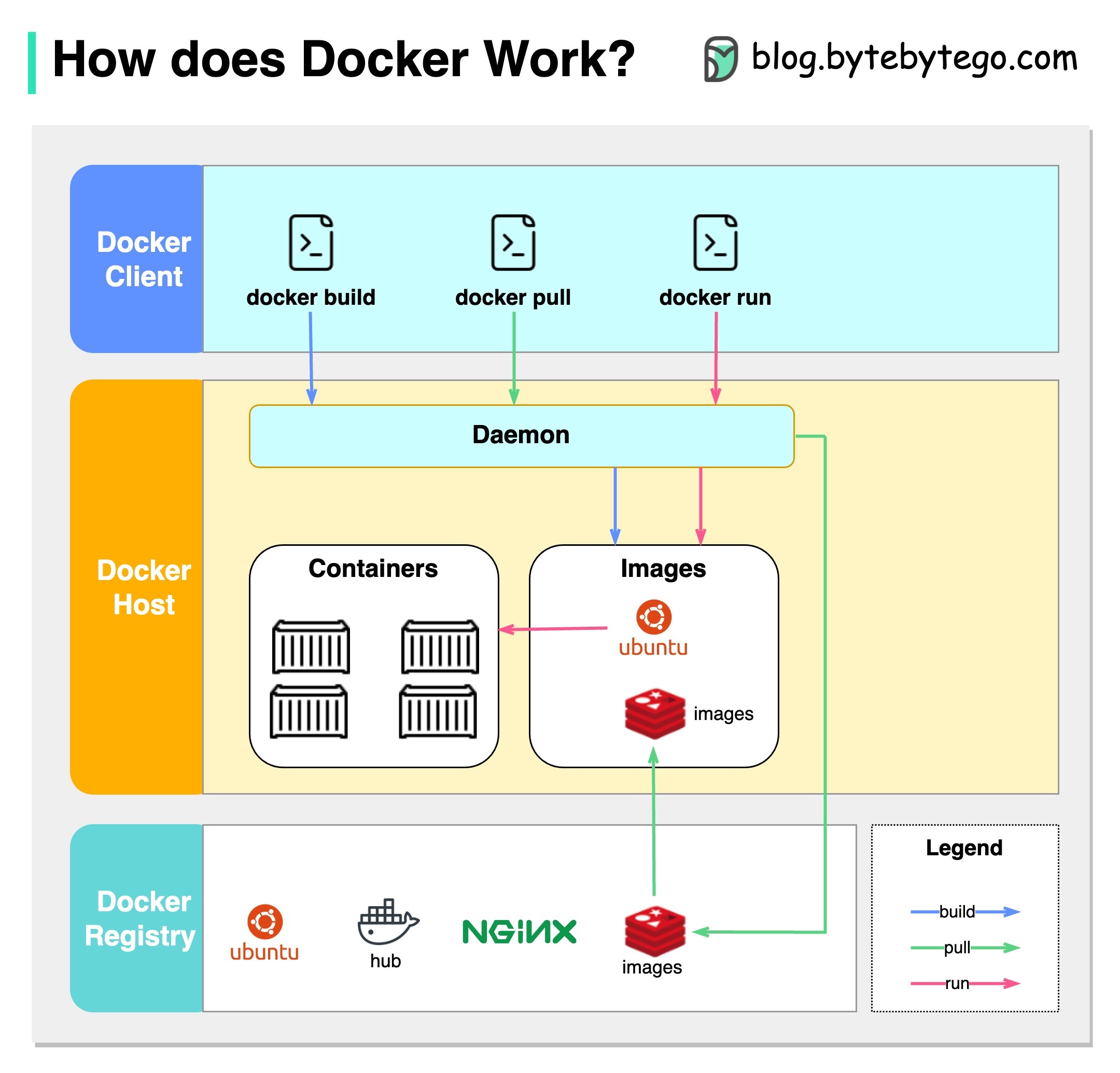
Il y a 3 composants dans l'architecture Docker:
Client docker
Le client Docker parle au démon Docker.
Hôte docker
Le démon Docker écoute les demandes de l'API Docker et gère des objets Docker tels que des images, des conteneurs, des réseaux et des volumes.
Registre Docker
Un registre Docker stocke des images Docker. Docker Hub est un registre public que n'importe qui peut utiliser.
Prenons l'exemple de la commande «Docker Run».
Pour commencer, il est essentiel d'identifier où notre code est stocké. L'hypothèse commune est qu'il n'y a que deux emplacements - l'un sur un serveur distant comme GitHub et l'autre sur notre machine locale. Cependant, ce n'est pas entièrement exact. Git maintient trois stockages locaux sur notre machine, ce qui signifie que notre code peut être trouvé à quatre endroits:
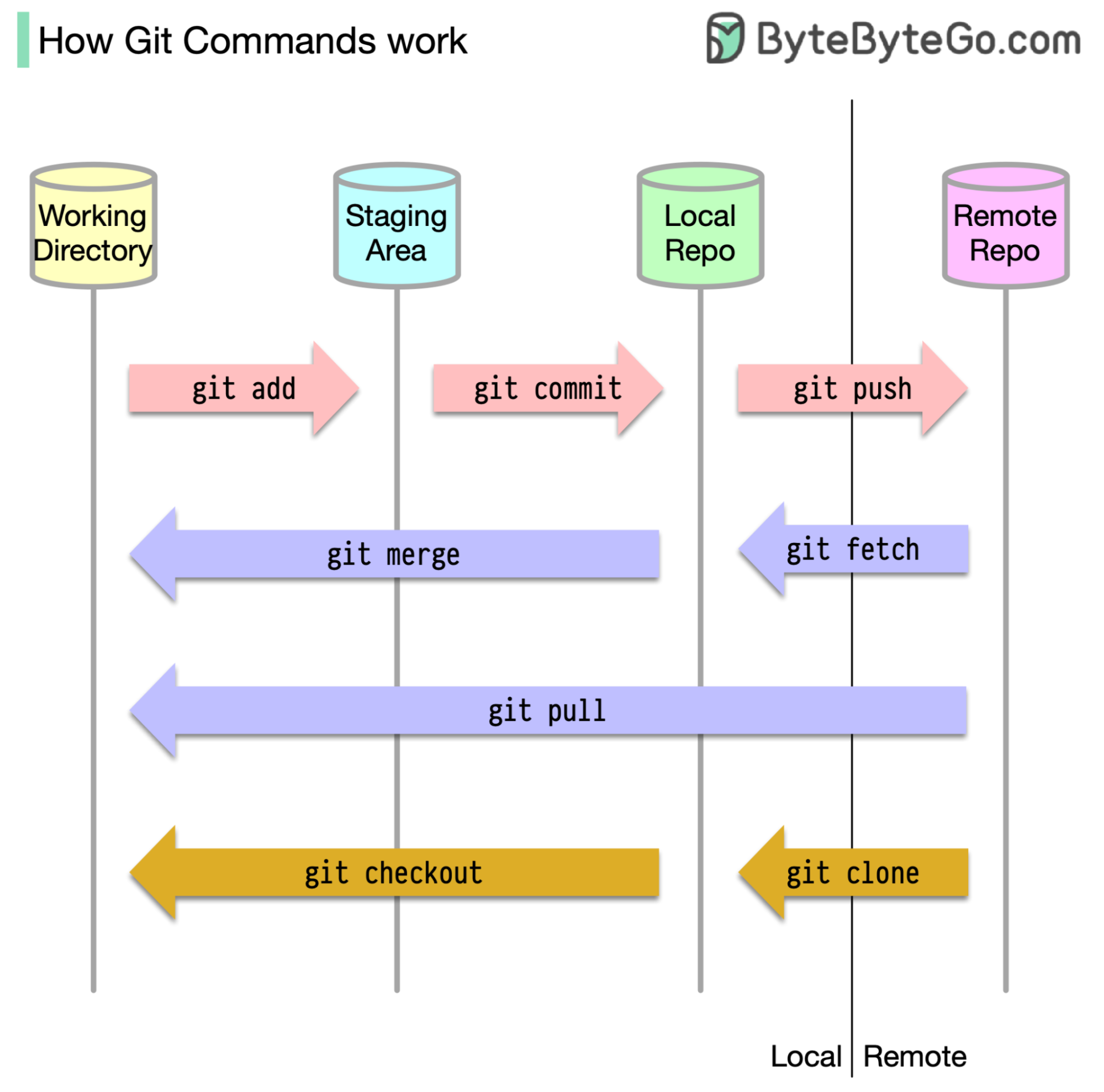
La plupart des commandes GIT déplacent principalement les fichiers entre ces quatre emplacements.
Le diagramme ci-dessous montre le flux de travail GIT.
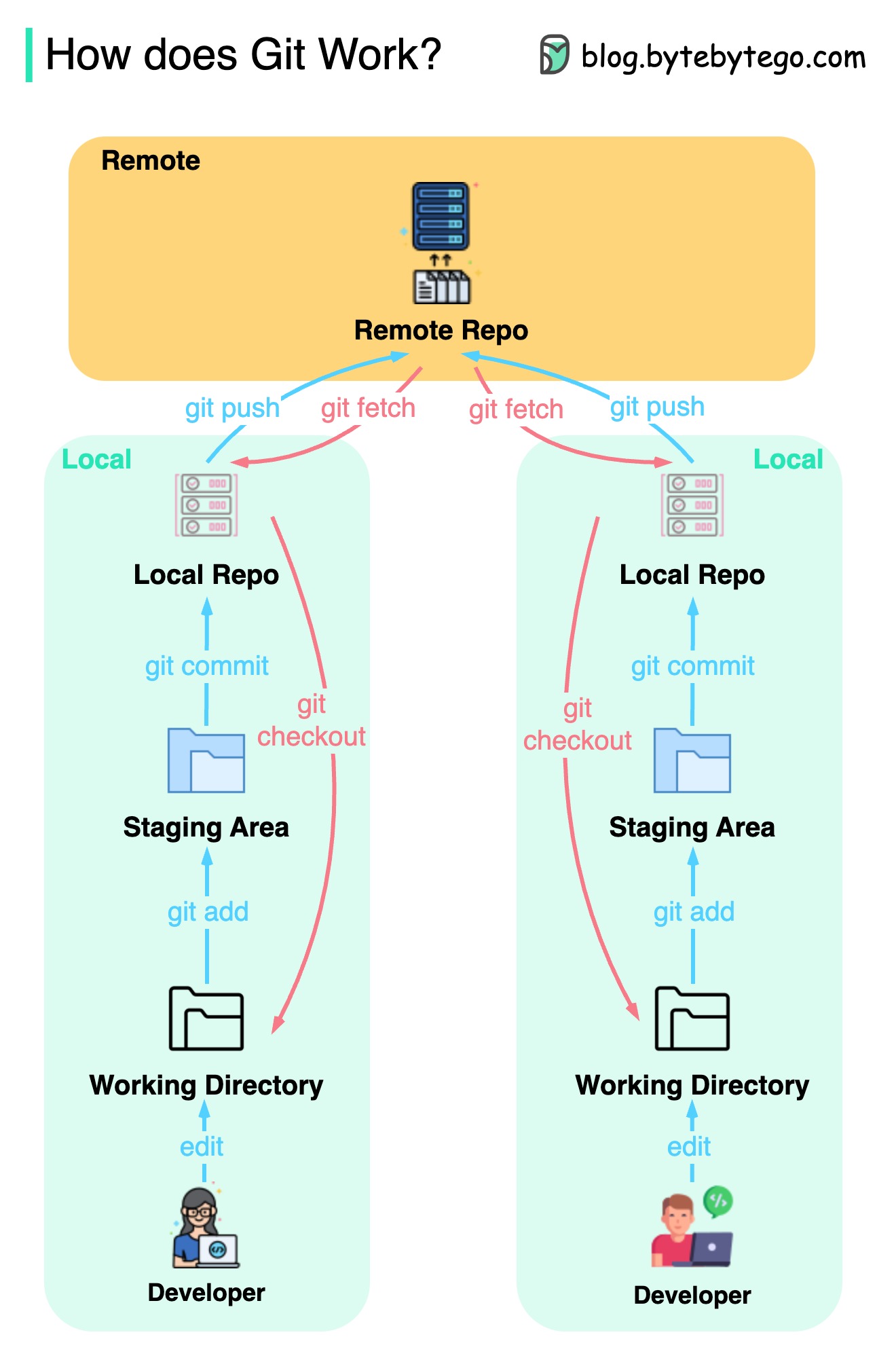
Git est un système de contrôle de version distribué.
Chaque développeur maintient une copie locale du référentiel principal et modifie et s'engage à la copie locale.
Le commit est très rapide car l'opération n'interagit pas avec le référentiel distant.
Si le référentiel distant se bloque, les fichiers peuvent être récupérés à partir des référentiels locaux.
Quelles sont les différences?


