AI Guide and Demos zh_CN
1.0.0
En repensant au processus d'apprentissage passé, les vidéos des professeurs Ng Enda et Li Hongyi m'ont été d'une grande aide dans mon parcours d'apprentissage en profondeur. Leurs méthodes d’explication humoristiques et leurs explications simples et intuitives rendent l’apprentissage théorique ennuyeux vivant et intéressant.
Cependant, dans la pratique, de nombreux étudiants s'inquiéteront au début de la manière d'obtenir l'API des grands modèles étrangers. Bien qu'ils puissent éventuellement trouver une solution, la peur des difficultés pour la première fois retardera toujours la progression de l'apprentissage et changera progressivement. de « juste regarder la vidéo ». Je vois souvent des discussions similaires dans la zone de commentaires, j'ai donc décidé d'utiliser mon temps libre pour aider les étudiants à franchir ce seuil. C'est aussi l'intention initiale du projet.
Ce projet ne fournira pas de didacticiels sur l'accès scientifique à Internet et ne s'appuiera pas non plus sur des interfaces personnalisées pour la plate-forme, mais utilisera le SDK OpenAI, plus compatible, pour aider chacun à acquérir des connaissances plus générales.
Le projet débutera par de simples appels API et vous emmènera progressivement dans le monde des grands modèles. Au cours du processus, vous maîtriserez des compétences telles que le résumé vidéo IA , le réglage fin du LLM et la génération d'images IA .
Il est fortement recommandé de regarder le cours « Introduction à l'intelligence artificielle générative » du professeur Li Hongyi pour un apprentissage simultané : accès rapide aux liens liés au cours
Désormais, le projet propose également CodePlayground. Vous pouvez configurer l'environnement selon la documentation, exécuter le script avec une seule ligne de code et découvrir le charme de l'IA.
Les essais de thèse se trouvent dans PaperNotes, et les articles de base liés aux grands modèles seront téléchargés progressivement.
L'image de base est prête Si vous n'avez pas configuré votre propre environnement d'apprentissage en profondeur, vous pouvez aussi bien essayer Docker.
Faites un bon voyage!
--- : Connaissances de base, regardez-les si nécessaire ou ignorez-les temporairement. Les résultats du fichier de code seront affichés dans l'article, mais il est toujours recommandé d'exécuter le code manuellement. Il peut y avoir des besoins en mémoire vidéo.API : L'article utilise uniquement l'API des grands modèles, n'est pas soumis aux restrictions des appareils et peut être exécuté sans GPU.LLM : Pratique liée aux grands modèles de langage, les fichiers de code peuvent avoir des besoins en mémoire vidéo.SD : Stable Diffusion, une pratique liée aux diagrammes vincentiens, et les fichiers de code ont des besoins en mémoire vidéo.File et l'effet d'apprentissage sera le même.Setting -> Accelerator ->选择GPU .代码执行程序->更改运行时类型->选择GPU .| Guide | Étiqueter | Décrire | Déposer | En ligne |
|---|---|---|---|---|
| 00. Étapes d'obtention de l'API Alibaba Big Model | API | Nous vous guiderons étape par étape pour obtenir l'API. Si c'est la première fois que vous vous inscrivez, vous devez effectuer une vérification d'identité (reconnaissance faciale). | ||
| 01. Première introduction à l'API LLM : configuration de l'environnement et démonstration de dialogue multi-tours | API | Il s'agit d'une configuration et d'une démonstration d'introduction. Le code de conversation est modifié à partir des documents de développement Alibaba. | Code | Kaggle Colab |
| 02. Facile à démarrer : créez des applications d'IA via l'API et Gradio | API | Guidez comment utiliser Gradio pour créer une application d'IA simple. | Code | Colab |
| 03. Guide avancé : Personnaliser l'invite pour améliorer les capacités de résolution de problèmes de grands modèles | API | Vous apprendrez à personnaliser une invite pour améliorer la capacité des grands modèles à résoudre des problèmes mathématiques. Des versions Gradio et non-Gradio seront également fournies et les détails du code seront affichés. | Code | Kaggle Colab |
| 04. Comprendre LoRA : de la couche linéaire au mécanisme d'attention | --- | Avant d'entrer officiellement en pratique, vous devez connaître les concepts de base de LoRA. Cet article vous mènera de la mise en œuvre de la couche linéaire LoRA au mécanisme d'attention. | ||
05. Comprendre la série AutoModel de Hugging Face : classes de chargement automatique de modèles pour différentes tâches | --- | Le module que nous sommes sur le point d'utiliser est AutoModel dans Hugging Face. Cet article est également un prérequis (vous pouvez bien sûr l'ignorer et le lire plus tard lorsque vous avez des doutes). | Code | Kaggle Colab |
| 06. Commencez : déployez votre premier modèle de langage | LLM | Implémentant un déploiement de modèle de langage très basique, le projet n'a pas d'exigences strictes pour le GPU jusqu'à présent, vous pouvez continuer à apprendre. | Code app_fastapi.py app_flask.py | |
| 07. Explorez la relation entre les paramètres du modèle et la mémoire vidéo et l'impact des différentes précisions | --- | Comprendre la correspondance entre les paramètres du modèle et la mémoire vidéo et maîtriser les méthodes d'importation de différentes précisions rendra votre sélection de modèle plus habile. | ||
| 08. Essayez d'affiner le LLM : laissez-le écrire de la poésie Tang | LLM | Cet article est le même que 03. Guide avancé : personnalisation de l'invite pour améliorer les capacités de résolution de problèmes des grands modèles. Il se concentre essentiellement sur « l'utilisation » plutôt que sur « l'écriture ». Vous pouvez avoir une compréhension du processus global comme auparavant. section hyperparamètres pour voir l’impact sur le réglage fin. | Code | Kaggle Colab |
| 09. Compréhension approfondie de Beam Search : principes, exemples et implémentation du code | --- | En passant d'exemples à des démonstrations de code, expliquant les mathématiques de Beam Search, cela devrait dissiper une certaine confusion de la lecture précédente, et enfin fournir un exemple simple d'utilisation de la bibliothèque Hugging Face Transformers (vous pouvez l'essayer si vous avez sauté l'article précédent) . | Code | Kaggle Colab |
| 10. Top-K vs Top-P : stratégie d'échantillonnage et influence de la température dans les modèles génératifs | --- | Ensuite, pour vous montrer d'autres stratégies de génération. | Code | Kaggle Colab |
| 11. Exemple de réglage fin du DPO : optimisation du grand modèle de langage LLM en fonction des préférences humaines | LLM | Un exemple de réglage fin à l’aide de DPO. | Code | Kaggle Colab |
| 12. Attribution des fonctionnalités Inseq : interpréter visuellement la sortie de LLM | LLM | Exemples visuels de tâches de traduction et de génération de texte (à remplir). | Code | Kaggle Colab |
| 13. Comprendre les biais possibles dans l'IA | LLM | Aucune compréhension du code n'est requise et cela peut être utilisé comme une exploration amusante pendant les loisirs. | Code | Kaggle Colab |
| 14. PEFT : appliquez rapidement LoRA aux grands modèles | --- | Découvrez comment ajouter des couches LoRA après avoir importé le modèle. | Code | Kaggle Colab |
| 15. Utilisez l'API pour implémenter le résumé vidéo de l'IA : créez votre propre assistant vidéo IA | API et LLM | Vous apprendrez les principes qui sous-tendent les assistants de résumé vidéo IA courants et commencerez à mettre en œuvre le résumé vidéo IA. | Code-version complète Code-version allégée ?scénario | Kaggle Colab |
| 16. Utilisez LoRA pour affiner la diffusion stable : démontez le four d'alchimie et implémentez votre première peinture IA | SD | Utilisez LoRA pour affiner le modèle de diagramme de Vincent et vous pouvez désormais également fournir vos fichiers LoRA à d'autres. | Code Code-version allégée | Kaggle Colab |
| 17. Une brève discussion sur la quantification du modèle RTN : asymétrique vs symétrique.md | --- | Pour mieux comprendre le comportement de quantification du modèle RTN, cet article utilise INT8 comme exemple pour l'expliquer. | Code | Kaggle Colab |
| 18. Aperçu de la technologie de quantification des modèles et analyse du format de fichier GGUF/GGML | --- | Il s'agit d'un article de présentation qui peut résoudre certains de vos doutes lors de l'utilisation de GGUF/GGML. | ||
| 19a. Du chargement à la conversation : exécuter localement de grands modèles LLM quantifiés (GPTQ et AWQ) à l'aide de Transformers. 19b. Du chargement à la conversation : exécuter localement de grands modèles LLM quantifiés (GGUF) à l'aide de Llama-cpp-python | LLM | Vous allez déployer un modèle quantitatif avec 7 milliards (7B) de paramètres sur votre ordinateur. Notez que cet article ne nécessite pas de carte graphique. 19 a Utilisation de Transformers, impliquant le chargement de modèles aux formats GPTQ et AWQ. 19 b Utilisation de Llama-cpp-python, impliquant le chargement de modèle au format GGUF. De plus, vous compléterez également la fonction d'interaction de dialogue de grand modèle local. | Transformateurs de code Code-Llama-cpp-python ?scénario | |
| 20. Pratique d'introduction à RAG : du fractionnement de documents à la base de données vectorielles et à la construction de questions et réponses | LLM | Pratiques liées au RAG. Découvrez comment fonctionne la segmentation de texte récursive. | Code | |
| 21. BPE vs WordPièce : comprendre le principe de fonctionnement du Tokenizer et la méthode de segmentation des sous-mots | --- | Opérations de base de Tokenizer. Découvrez les méthodes courantes de segmentation de sous-mots : BPE et WordPièce. Comprendre le masque d'attention (Attention Mask) et les ID de type de jeton (Token Type ID). | Code | Kaggle Colab |
| 22. Devoir - Bert peaufine les réponses aux questions extractives | Il s'agit d'un devoir qui utilise BERT pour affiner les tâches de questions et réponses en aval. Vous pouvez l'essayer et essayer de rejoindre le « concours » de Kaggle. Un article guide avec tous les conseils sera donné après une semaine. Vous pouvez choisir d'étudier maintenant. ou laissez-le pour plus tard. L'article d'introduction ne couvrira pas la description du devoir et deux versions du code seront téléchargées pour l'apprentissage, alors ne vous inquiétez pas. Il n’y aura pas de date limite ici. | Code - Affectation | Kaggle Colab |
Conseil
Si vous préférez extraire l'entrepôt pour lire .md localement, lorsqu'une erreur de formule se produit, veuillez utiliser Ctrl+F ou Command+F , recherchez \_ et remplacez tout par _ .
Lectures complémentaires :
| Guide | Décrire |
|---|---|
| a. Utilisez HFD pour accélérer le téléchargement des modèles et des ensembles de données Hugging Face. | Si vous estimez que le téléchargement du modèle est trop lent, vous pouvez vous référer à cet article pour la configuration. Si vous rencontrez des erreurs 443 liées au proxy, vous pouvez également essayer de consulter cet article. |
| b. Vérification rapide des commandes de ligne de commande de base (applicable à Linux/Mac) | Une vérification rapide des commandes de ligne de commande contient essentiellement toutes les commandes impliquées dans l'entrepôt actuel. Vérifiez-la lorsque vous êtes confus. |
| c. Solutions à certains problèmes | Nous allons résoudre ici certains problèmes qui peuvent être rencontrés lors du fonctionnement du projet. - Comment extraire l'entrepôt distant pour écraser toutes les modifications locales ? - Comment afficher et supprimer les fichiers téléchargés par Hugging Face, et comment modifier le chemin de sauvegarde ? |
| d. Comment charger le modèle GGUF (solution pour Shared/Shared/Split/00001-of-0000...) | - Découvrez les nouvelles fonctionnalités de Transformers à propos de GGUF. - Utilisez Transformers/Llama-cpp-python/Ollama pour charger les fichiers de modèle au format GGUF. - Apprenez à fusionner des fichiers GGUF fragmentés. - Résolvez le problème selon lequel LLama-cpp-python ne peut pas être déchargé. |
| e. Amélioration des données : analyse des méthodes courantes de torchvision.transforms | - Comprendre les méthodes d'amélioration des données d'image couramment utilisées. Code | |
| f. Fonction de perte d'entropie croisée nn.CrossEntropyLoss() Explication détaillée et rappel des points clés (PyTorch) | - Comprendre les principes mathématiques de la perte d'entropie croisée et de la mise en œuvre de PyTorch. - Apprenez à quoi faire attention lors de la première utilisation. |
| g. Explication détaillée de la couche d'intégration nn.Embedding() et rappel des points clés (PyTorch) | - Comprendre les concepts d'intégration de couches et d'intégrations de mots. - Visualisez l'intégration à l'aide de modèles pré-entraînés. Code | |
| h. Utilisez Docker pour configurer rapidement l'environnement d'apprentissage en profondeur (Linux) h. Introduction aux commandes de base de Docker et à la résolution des erreurs courantes | - Utilisez deux lignes de commandes pour configurer l'environnement d'apprentissage en profondeur - Introduction aux commandes de base de Docker - Résolvez trois erreurs courantes lors de l'utilisation |
Explication du dossier :
Démos
Tous les fichiers de code y seront stockés.
données
Il n'est pas nécessaire de prêter attention à ce dossier pour stocker de petites données pouvant être utilisées dans le code.
GenAI_PDF
Voici les fichiers PDF des devoirs du cours [Introduction à l'intelligence artificielle générative]. Je les ai téléchargés car ils ont été initialement enregistrés dans Google Drive.
Guide
Tous les documents d’orientation y seront hébergés.
actifs
Voici les images utilisées dans le fichier .md. Il n'est pas nécessaire de prêter attention à ce dossier.
Notes papier
Essai de thèse.
CodePlayground
Quelques exemples de scripts de code intéressants (version Toy).
LISEZMOI.md
résumer.py ?script
Résumé vidéo/audio/sous-titres AI.
chat.py ?script
Conversation sur l'IA.
Introduction aux ressources d'apprentissage sur l'intelligence artificielle générative
Page d'accueil du cours
Officiel | Vidéo autorisée : YouTube |
La production et le partage de la version miroir chinoise ont été autorisés par le professeur Li Hongyi. Merci au professeur pour votre partage altruiste de connaissances !
L'image chinoise PS réalisera pleinement toutes les fonctions du code de travail (opération locale). Kaggle est une plateforme en ligne qui peut être directement connectée en Chine. Le contenu de Chinese Colab et Kaggle est cohérent. Choisissez-en un pour terminer l’étude.
En fonction des besoins réels, sélectionnez une méthode ci-dessous pour préparer l'environnement d'apprentissage, cliquez sur ► ou sur le texte pour développer .
Kaggle (connexion directe nationale, recommandée) : lisez l'article « Kaggle : Guide d'utilisation du GPU gratuit, une alternative idéale à Colab » pour en savoir plus.
Colab (nécessite un accès scientifique à Internet)
Les fichiers de code du projet sont synchronisés sur les deux plateformes.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install gitmacOS :
Installez d'abord Homebrew :
/bin/bash -c " $( curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh ) "Puis exécutez :
brew install gitFenêtres :
Téléchargez et installez depuis Git pour Windows.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install wget curlmacOS :
brew install wget curlFenêtres :
Téléchargez et installez à partir des sites Web officiels de Wget pour Windows et Curl.
Visitez le site officiel d'Anaconda, entrez votre adresse e-mail et vérifiez votre e-mail. Vous devriez pouvoir voir :
Cliquez sur Download Now , sélectionnez la version appropriée et téléchargez-la (Anaconda et Miniconda sont disponibles) :

Linux (Ubuntu) :
Installer Anaconda
Visitez repo.anaconda.com pour la sélection de version.
# 下载 Anaconda 安装脚本(以最新版本为例)
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
# 运行安装脚本
bash Anaconda3-2024.10-1-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcInstaller Miniconda (recommandé)
Visitez repo.anaconda.com/miniconda pour la sélection de version. Miniconda est une version simplifiée d'Anaconda, contenant uniquement Conda et Python.
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcmacOS :
Remplacez en conséquence l'URL dans la commande Linux.
Installer Anaconda
Visitez repo.anaconda.com pour la sélection de version.
Installer Miniconda (recommandé)
Visitez repo.anaconda.com/miniconda pour la sélection de version.
Entrez la commande suivante dans le terminal. Si les informations de version s'affichent, l'installation est réussie.
conda --versioncat << ' EOF ' > ~/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirror.nju.edu.cn/anaconda/pkgs/main
- https://mirror.nju.edu.cn/anaconda/pkgs/r
- https://mirror.nju.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirror.nju.edu.cn/anaconda/cloud
pytorch: https://mirror.nju.edu.cn/anaconda/cloud
EOF[!note]
De nombreuses sources miroirs qui étaient disponibles l'année dernière ne le sont plus. Pour la configuration actuelle des autres sites miroirs, vous pouvez vous référer à ce très joli document de NTU : Mirror Usage Help.
Remarque : Si Anaconda ou Miniconda est déjà installé, pip sera inclus dans le système et aucune installation supplémentaire n'est requise.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install python3-pipmacOS :
brew install python3Fenêtres :
Téléchargez et installez Python, en vous assurant que l'option "Ajouter Python au PATH" est cochée.
Ouvrez une invite de commande et entrez :
python -m ensurepip --upgradeEntrez la commande suivante dans le terminal. Si les informations de version s'affichent, l'installation est réussie.
pip --versionpip config set global.index-url https://mirrors.aliyun.com/pypi/simpleExtrayez le projet avec la commande suivante :
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNIl n'y a pas de limite de version, elle peut être supérieure :
conda create -n aigc python=3.9 Appuyez sur y et entrez pour continuer. Une fois la création terminée, activez l'environnement virtuel :
conda activate aigcEnsuite, vous devez installer les dépendances de base. Reportez-vous au site officiel de PyTorch, en prenant CUDA 11.8 comme exemple (si la carte graphique ne prend pas en charge 11.8, vous devez modifier la commande), choisissez l'une des deux à installer :
# pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# conda
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidiaNous avons maintenant configuré avec succès tous les environnements requis et sommes prêts à commencer l'apprentissage :) Les dépendances restantes seront répertoriées séparément dans chaque article.
[!note]
Les images Docker ont des dépendances préinstallées, il n'est donc pas nécessaire de les réinstaller.
Installez d'abord jupyter-lab , qui est beaucoup plus facile à utiliser que jupyter notebook .
pip install jupyterlabUne fois l'installation terminée, exécutez la commande suivante :
jupyter-lab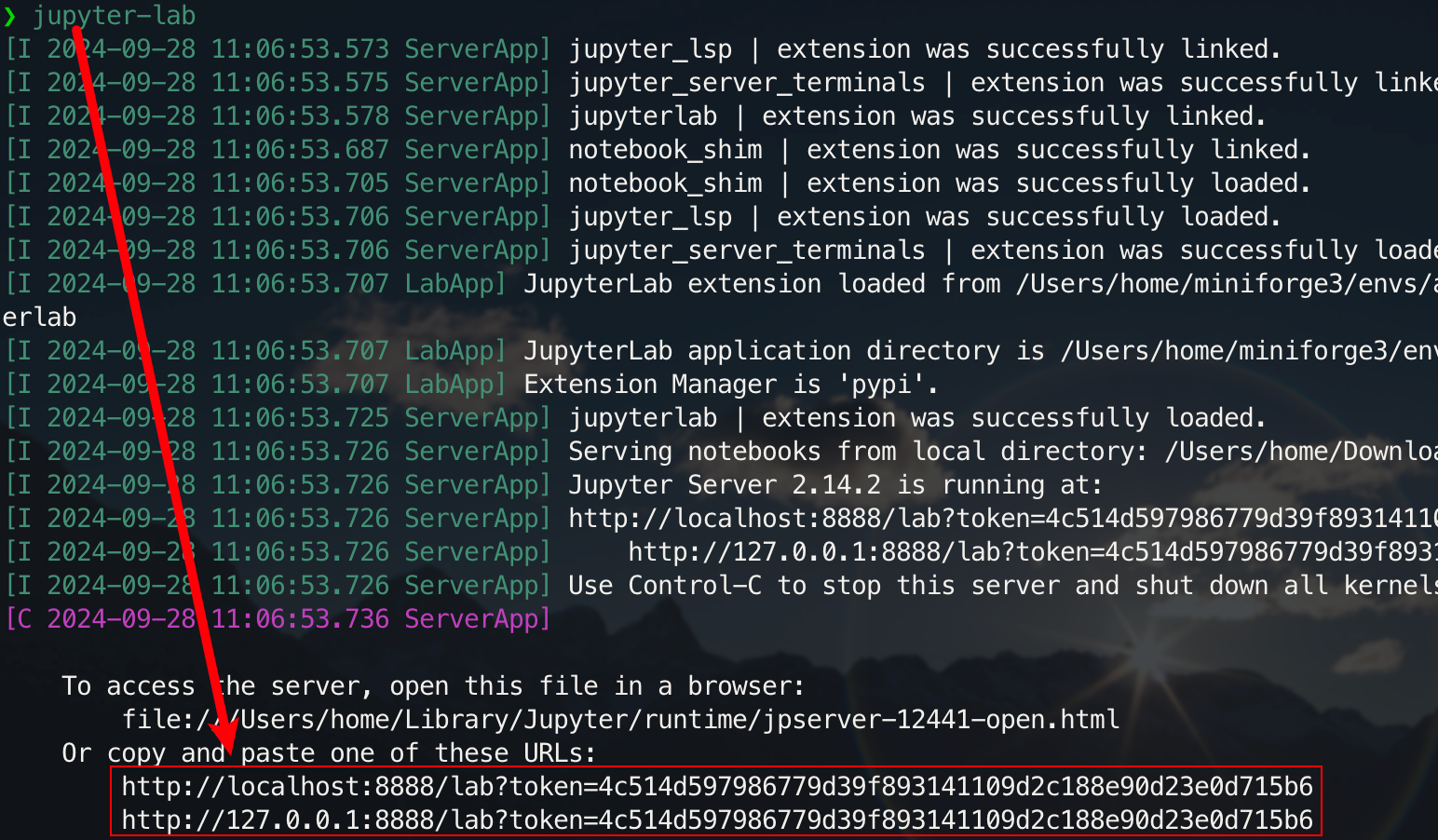
Vous pourrez désormais y accéder via le lien contextuel, généralement situé sur le port 8888. Pour l'interface graphique, maintenez Ctrl enfoncée sous Windows/Linux, maintenez Command enfoncée sous Mac, puis cliquez sur le lien pour accéder directement. À ce stade, vous aurez une image complète du projet :
Les étudiants qui n'ont pas installé Docker peuvent lire l'article « Utiliser Docker pour configurer rapidement un environnement d'apprentissage en profondeur (Linux) ». Il est recommandé aux débutants de lire « Introduction aux commandes de base de Docker et à la résolution des erreurs courantes ».
Toutes les versions sont préinstallées avec des outils communs tels que sudo , pip , conda , wget , curl et vim , et les sources d'images nationales de pip et conda ont été configurées. En même temps, il intègre zsh et quelques plug-ins de ligne de commande pratiques (complétion automatique des commandes, coloration syntaxique et outil de saut de répertoire z ). De plus, jupyter notebook et jupyter lab ont été préinstallés et le terminal par défaut est défini sur zsh pour faciliter le développement de l'apprentissage en profondeur. L'affichage chinois dans le conteneur a été optimisé pour éviter les caractères tronqués. L'adresse miroir domestique de Hugging Face est également préconfigurée.
pytorch/pytorch:2.5.1-cuda11.8-cudnn9-devel . La version par défaut python est 3.11.10. La version peut être modifiée directement via conda install python==版本号.Installation appropriée :
wget , curl : outils de téléchargement en ligne de commandevim , nano : éditeur de textegit : outil de contrôle de versiongit-lfs : Git LFS (stockage de fichiers volumineux)zip , unzip : outils de compression et décompression de fichiershtop : outil de surveillance du systèmetmux , screen : outils de gestion de sessionbuild-essential : outils de compilation (tels que gcc , g++ )iputils-ping , iproute2 , net-tools : outils réseau (fournissant des commandes telles que ping , ip , ifconfig , netstat , etc.)ssh : outil de connexion à distancersync : outil de synchronisation de fichierstree : Afficher les arborescences de fichiers et de répertoireslsof : Afficher les fichiers actuellement ouverts sur le systèmearia2 : outil de téléchargement multi-threadlibssl-dev : bibliothèque de développement OpenSSLinstallation du pip :
jupyter notebook , jupyter lab : environnement de développement interactifvirtualenv : Outil de gestion d'environnement virtuel Python, vous pouvez utiliser conda directementtensorboard : outil de visualisation de formation en deep learningipywidgets : bibliothèque de widgets Jupyter pour afficher correctement les barres de progressionPlugin :
zsh-autosuggestions : auto-complétion des commandeszsh-syntax-highlighting : coloration syntaxiquez : accéder rapidement au répertoireLa version dl (Deep Learning) est basée sur base et installe en plus des outils et bibliothèques de base qui peuvent être utilisés en deep learning :
Installation appropriée :
ffmpeg : outil de traitement audio et vidéolibgl1-mesa-glx : Dépendance de la bibliothèque graphique (résout certains problèmes liés aux graphiques du framework d'apprentissage en profondeur)installation du pip :
numpy , scipy : calculs numériques et calculs scientifiquespandas : analyse des donnéesmatplotlib , seaborn : visualisation de donnéesscikit-learn : Outils d'apprentissage automatiquetensorflow , tensorflow-addons : un autre framework d'apprentissage profond populairetf-keras : implémentation TensorFlow de l'interface Kerastransformers , datasets : outils PNL fournis par Hugging Facenltk , spacy : outils de traitement du langage naturelSi des bibliothèques supplémentaires sont nécessaires, elles peuvent être installées manuellement avec la commande suivante :
pip install --timeout 120 <替换成库名> Ici, --timeout 120 définit un délai d'attente de 120 secondes pour garantir qu'il reste suffisamment de temps pour l'installation même si le réseau est médiocre. Si vous ne le configurez pas, vous risquez de rencontrer une situation dans laquelle le package d'installation échoue en raison d'un délai de téléchargement dans un environnement domestique.
Notez que toutes les images ne tireront pas l'entrepôt à l'avance.
En supposant que vous avez installé et configuré Docker, vous n'avez besoin que de deux lignes de commandes pour terminer la configuration de l'environnement d'apprentissage en profondeur. Pour le projet en cours, vous pouvez faire une sélection après avoir consulté la description de la version. L' image_name:tag correspondante des deux est la suivante. suit :
hoperj/quickstart:base-torch2.5.1-cuda11.8-cudnn9-develhoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develLa commande pull est :
docker pull < image_name:tag >Ce qui suit utilise la version dl comme exemple pour démontrer la commande Choisissez l’une des méthodes à terminer.
docker pull dockerpull.org/hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develdocker pull hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develLes fichiers peuvent être téléchargés via Baidu Cloud Disk (Alibaba Cloud Disk ne prend pas en charge le partage de fichiers compressés volumineux).
Les fichiers du même nom ont le même contenu.
.tar.gzest une version compressée. Après le téléchargement, décompressez-le avec la commande suivante :gzip -d dl.tar.gz
En supposant dl.tar soit téléchargé dans ~/Downloads , passez ensuite au répertoire correspondant :
cd ~ /DownloadsChargez ensuite l'image :
docker load -i dl.tarDans ce mode, le conteneur utilisera directement la configuration réseau de l'hôte et tous les ports sont égaux aux ports de l'hôte sans mappage séparé. Si vous avez uniquement besoin de mapper un port spécifique, remplacez
--network hostpar-p port:port.
docker run --gpus all -it --name ai --network host hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel /bin/zsh Pour les étudiants qui ont besoin d'utiliser un proxy, ajoutez -e pour définir les variables d'environnement. Vous pouvez également vous référer à l'article détaillé a :
Supposons que le numéro de port HTTP/HTTPS du proxy est 7890 et que SOCKS5 est 7891 :
-e http_proxy=http://127.0.0.1:7890-e https_proxy=http://127.0.0.1:7890-e all_proxy=socks5://127.0.0.1:7891Intégré à la commande précédente :
docker run --gpus all -it
--name ai
--network host
-e http_proxy=http://127.0.0.1:7890
-e https_proxy=http://127.0.0.1:7890
-e all_proxy=socks5://127.0.0.1:7891
hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel
/bin/zsh[!conseil]
Découvrez à l'avance les opérations courantes :
- Démarrez le conteneur :
docker start <容器名>- Exécutez le conteneur :
docker exec -it <容器名> /bin/zsh
- Quitter dans le conteneur :
Ctrl + Douexit.- Arrêter le conteneur :
docker stop <容器名>- Supprimer un conteneur :
docker rm <容器名>
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNjupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root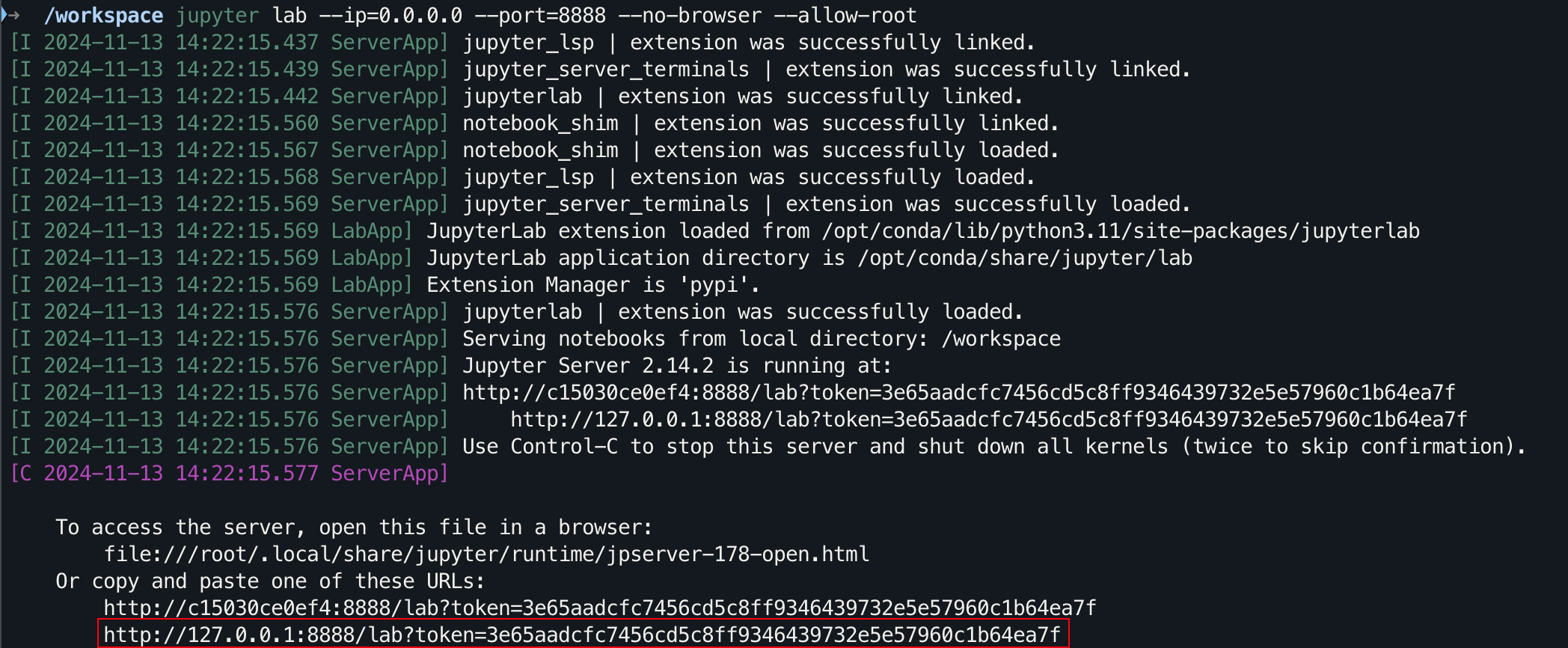
Pour l'interface graphique, maintenez Ctrl enfoncée sous Windows/Linux, maintenez Command enfoncée sous Mac, puis cliquez sur le lien pour accéder directement.
Merci pour votre STAR ?, j'espère que cela vous aidera.


