meme search engine
1.0.0
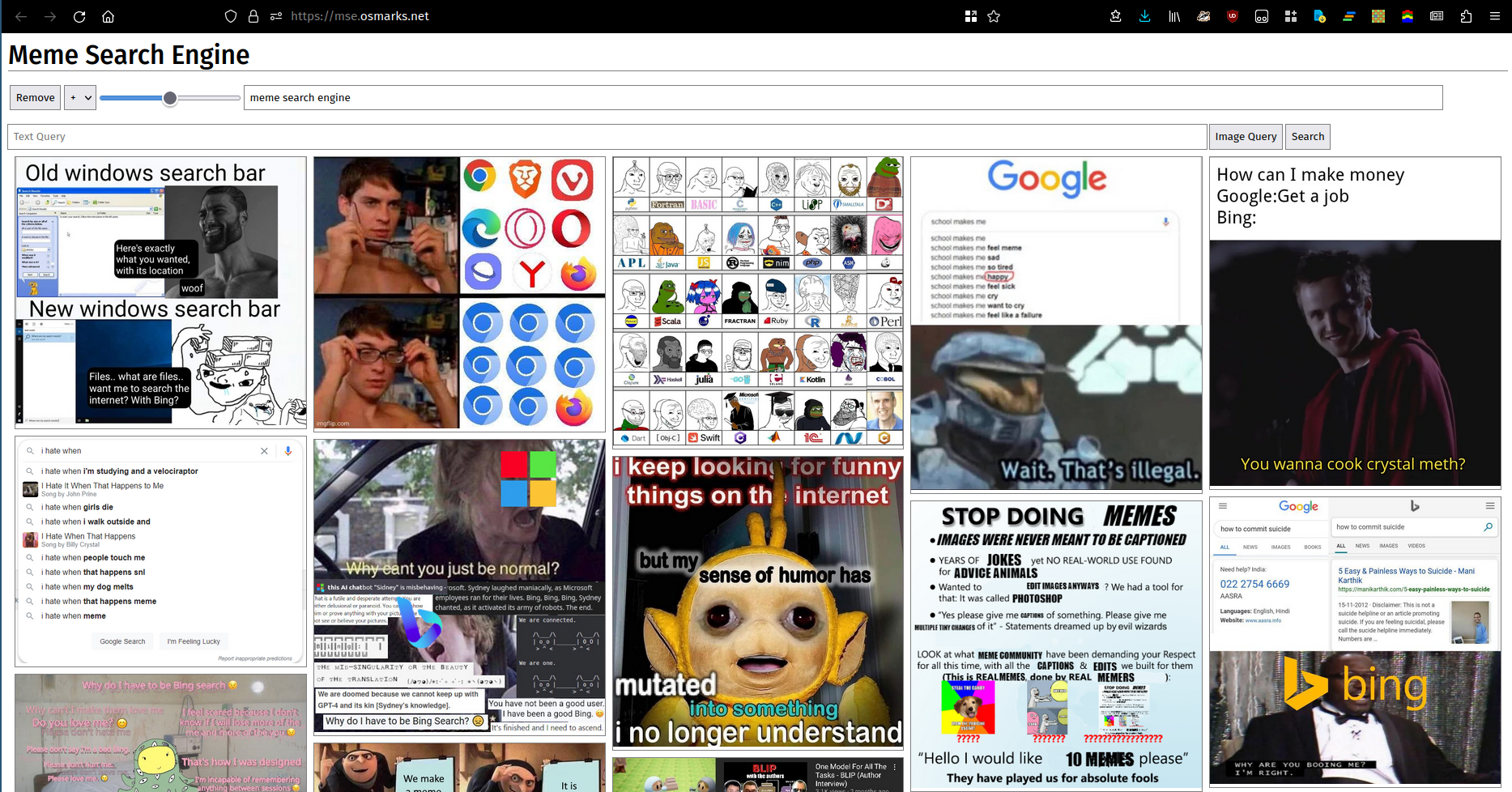
Avez-vous un gros dossier de mèmes dans lequel vous souhaitez effectuer une recherche sémantique ? Avez-vous un serveur Linux avec un GPU Nvidia ? Tu fais; c'est désormais obligatoire.
On dit qu’une image vaut mille mots. Malheureusement, de nombreux (la plupart ?) ensembles de mots ne peuvent pas être décrits de manière adéquate par des images. Quoi qu'il en soit, voici une photo. Vous pouvez utiliser une instance en cours d'exécution ici.
Ceci n’a pas été testé. Cela pourrait fonctionner. La nouvelle version de Rust simplifie certaines étapes (elle intègre sa propre vignette).
python -m http.server .pip à partir de requirements.txt (les versions ne devraient probablement pas nécessairement correspondre exactement si vous devez les modifier ; je viens de mettre ce que j'ai actuellement installé).transformers en raison de la prise en charge de SigLIP.thumbnailer.py (périodiquement, en même temps que le rechargement de l'index, idéalement)clip_server.py (en tant que service en arrière-plan).clip_server_config.json .device devrait probablement être cuda ou cpu . Le modèle fonctionnera ici.model estmodel_name est le nom du modèle à des fins de métriques.max_batch_size contrôle la taille maximale autorisée du lot. Des valeurs plus élevées se traduisent généralement par des performances légèrement meilleures (le goulot d'étranglement dans la plupart des cas se trouve ailleurs à l'heure actuelle) au prix d'une utilisation plus élevée de la VRAM.port est le port sur lequel exécuter le serveur HTTP.meme-search-engine (Rust) (également en tant que service d'arrière-plan).clip_server est l'URL complète du serveur backend.db_path est le chemin de la base de données SQLite d'images et de vecteurs d'intégration.files est l'endroit à partir duquel les fichiers mèmes seront lus. Les sous-répertoires sont indexés.port est le port sur lequel servir HTTP.enable_thumbs sur true pour diffuser des images compressées.npm install , node src/build.js .frontend_config.json .image_path est l'URL de base de votre serveur Web de mèmes (avec une barre oblique finale).backend_url est l'URL sur laquelle mse.py est exposé (barre oblique finale probablement facultative).clip_server.py . Voir ici pour plus d'informations sur MemeThresher, le nouveau système automatique d'acquisition/évaluation des mèmes (sous meme-rater ). Le déployer vous-même devrait être quelque peu délicat, mais devrait être à peu près réalisable :
crawler.py avec votre propre source et exécutez-le pour collecter un ensemble de données initial.mse.py avec un fichier de configuration comme celui fourni pour l'indexer.rater_server.py pour collecter un ensemble de données initial de paires.train.py pour entraîner un modèle. Vous devrez peut-être ajuster les hyperparamètres car je n'ai aucune idée de ceux qui sont bons.active_learning.py sur le meilleur point de contrôle disponible pour obtenir de nouvelles paires à évaluer.copy_into_queue.py pour copier les nouvelles paires dans la file d'attente rater_server.py .library_processing_server.py et planifiez l'exécution périodique meme_pipeline.py . Meme Search Engine utilise un index FAISS en mémoire pour contenir ses vecteurs d'intégration, car j'étais paresseux et cela fonctionne bien (~ 100 Mo de RAM totale utilisée pour mes 8 000 mèmes). Si vous souhaitez stocker beaucoup plus que cela, vous devrez passer à un index plus efficace/compact (voir ici). Comme les indices vectoriels sont conservés exclusivement en mémoire, vous devrez soit les conserver sur le disque, soit utiliser ceux qui sont rapides à créer/supprimer/ajouter (vraisemblablement des indices PCA/PQ). À un moment donné, si vous augmentez le trafic total, le modèle CLIP peut également devenir un goulot d'étranglement, car je n'ai pas non plus de stratégie de traitement par lots. L'indexation est actuellement liée au GPU car le nouveau modèle apparaît un peu plus lent pour les lots de grande taille et j'ai amélioré le pipeline de chargement des images. Vous souhaiterez peut-être également réduire les mèmes affichés pour réduire les besoins en bande passante.


