SOLIDER
1.0.0

Bienvenue chez SOLIDE ! SOLIDER est un cadre d'apprentissage auto-supervisé sémantiquement contrôlable permettant d'apprendre des représentations humaines générales à partir d'images humaines massives non étiquetées, ce qui peut profiter au maximum aux tâches centrées sur l'humain en aval. Contrairement aux méthodes d'apprentissage auto-supervisées existantes, les connaissances préalables issues des images humaines sont utilisées dans SOLIDER pour créer des étiquettes pseudo-sémantiques et importer davantage d'informations sémantiques dans la représentation apprise. Pendant ce temps, différentes tâches en aval nécessitent toujours des ratios différents d’informations sémantiques et d’informations d’apparence, et une seule représentation apprise ne peut pas répondre à toutes les exigences. Pour résoudre ce problème, SOLIDER introduit un réseau conditionnel avec un contrôleur sémantique, qui peut répondre aux différents besoins des tâches en aval. Pour plus de détails, veuillez vous référer à notre article Au-delà de l'apparence : un cadre d'apprentissage auto-supervisé sémantique contrôlable pour les tâches visuelles centrées sur l'humain.
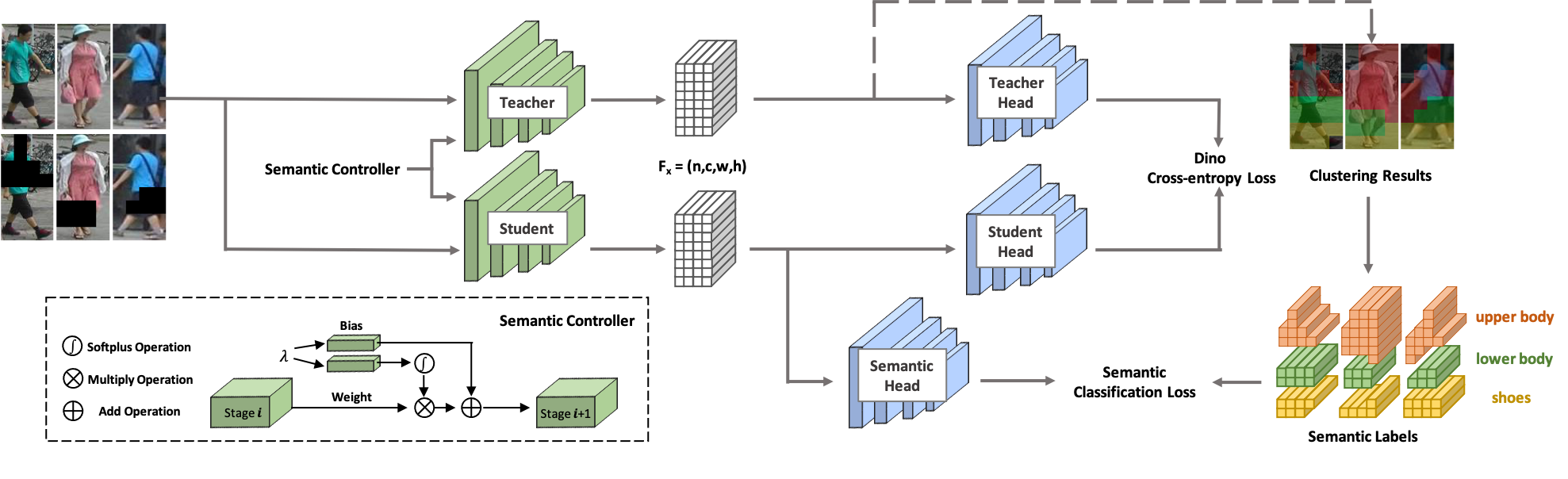
Cette base de code a été développée avec python version 3.7, PyTorch version 1.7.1, CUDA 10.1 et torchvision 0.8.2.
Nous utilisons LUPerson comme données de formation, qui consistent en des images humaines non étiquetées. Téléchargez LUPerson à partir de son lien officiel et décompressez-le.
sh run_solider.shsh run_dino.sh
sh resume_solider.shIl existe une démo pour exécuter le modèle SOLIDER formé, qui peut être intégré à l'inférence ou au réglage fin des tâches en aval.
python demo.pyNous utilisons Swin-Transformer comme épine dorsale, ce qui présente de grands avantages sur de nombreuses tâches de CV.
| Tâche | Ensemble de données | Swin minuscule (Lien) | Swin petit (Lien) | Base de natation (Lien) |
|---|---|---|---|---|
| Réidentification de la personne (mAP/R1) sans reclassement | Marché1501 | 91,6/96,1 | 93,3/96,6 | 93,9/96,9 |
| MSMT17 | 67,4/85,9 | 76,9/90,8 | 77,1/90,7 | |
| Réidentification de la personne (mAP/R1) avec reclassement | Marché1501 | 95,3/96,6 | 95,4/96,4 | 95,6/96,7 |
| MSMT17 | 81,5/89,2 | 86,5/91,7 | 86,5/91,7 | |
| Reconnaissance d'attributs (mA) | PETA_ZS | 74.37 | 76.21 | 76.43 |
| RAP_ZS | 74.23 | 75,95 | 76.42 | |
| PA100K | 84.14 | 86.25 | 86.37 | |
| Recherche de personne (mAP/R1) | CUHK-SYSU | 94,9/95,7 | 95,5/95,8 | 94,9/95,5 |
| PRW | 56,8/86,8 | 59,8/86,7 | 59,7/86,8 | |
| Détection des piétons (MR-2) | VillePersonnes | 10,3/40,8 | 10,0/39,2 | 9,7/39,4 |
| Analyse humaine (mIOU) | LÈVRE | 57.52 | 60.21 | 60,50 |
| Estimation de pose (AP/AR) | COCO | 74,4/79,6 | 76,3/81,3 | 76,6/81,5 |
Notre implémentation est principalement basée sur les bases de code suivantes. Nous remercions chaleureusement les auteurs pour leurs merveilleux travaux.
Si vous utilisez SOLIDER dans votre recherche, veuillez citer nos travaux en utilisant l'entrée BibTeX suivante :
@inproceedings{chen2023beyond,
title={Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks},
author={Weihua Chen and Xianzhe Xu and Jian Jia and Hao Luo and Yaohua Wang and Fan Wang and Rong Jin and Xiuyu Sun},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}


