ShapeGPT
1.0.0

Page du projet • Article Arxiv • Démo • FAQ • Citation
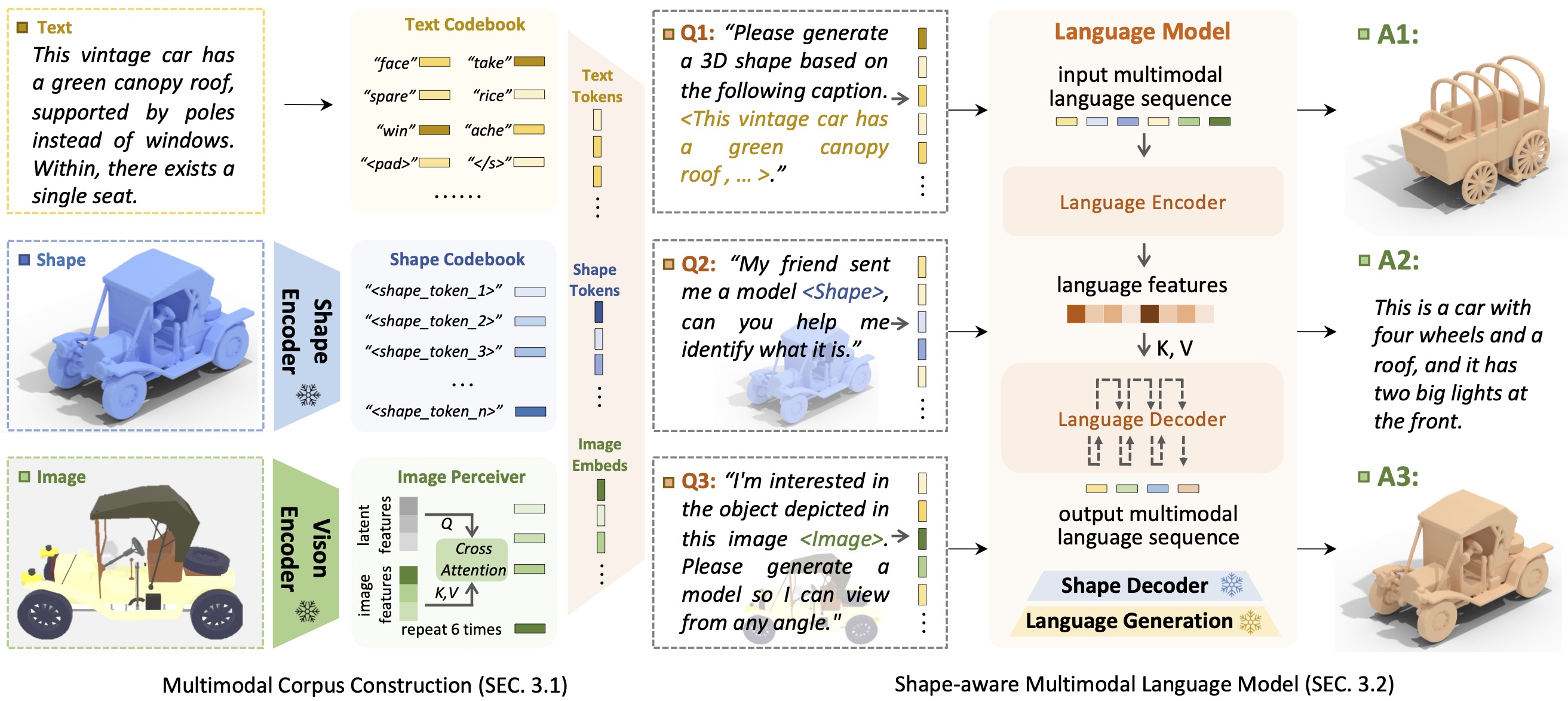
Introduction à ShapeGPTShapeGPT est un modèle de langage multimodal centré sur la forme unifié et convivial permettant d'établir un corpus multimodal et de développer des modèles de langage sensibles aux formes sur plusieurs tâches de forme .
L'avènement de grands modèles de langage, permettant une flexibilité grâce à des approches basées sur l'instruction, a révolutionné de nombreuses tâches génératives traditionnelles, mais les grands modèles de données 3D, en particulier dans la gestion globale des formes 3D avec d'autres modalités, sont encore sous-explorés. En réalisant des générations de formes basées sur des instructions, les modèles de formes génératifs multimodaux polyvalents peuvent bénéficier de manière significative à divers domaines tels que la construction virtuelle 3D et la conception assistée par réseau. Dans ce travail, nous présentons ShapeGPT, un cadre multimodal inclus dans la forme permettant d'exploiter de solides modèles de langage pré-entraînés pour traiter plusieurs tâches pertinentes pour la forme. Plus précisément, ShapeGPT utilise un cadre mot-phrase-paragraphe pour discrétiser les formes continues en mots de forme, assemble ensuite ces mots pour former des phrases et intègre la forme au texte pédagogique pour les paragraphes multimodaux. Pour apprendre ce modèle de langage de forme, nous utilisons un programme de formation en trois étapes, comprenant la représentation de forme, l'alignement multimodal et la génération basée sur des instructions, pour aligner les livres de codes de langage de forme et apprendre les corrélations complexes entre ces modalités. Des expériences approfondies démontrent que ShapeGPT atteint des performances comparables dans les tâches liées à la forme, notamment la conversion texte-forme, la forme-texte, la complétion de forme et l'édition de forme.
Si vous trouvez que notre code ou notre article vous aide, pensez à citer :
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
Grâce au modèle T5, Motion-GPT, Perceiver-IO et SDFusion, notre code leur emprunte partiellement. Notre approche s'inspire de Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox et 3DShape2VecSet.
Ce code est distribué sous une LICENCE MIT.
Notez que notre code dépend d'autres bibliothèques, notamment PyTorch3D et PyTorch Lightning, et utilise des ensembles de données qui ont chacun leurs propres licences respectives qui doivent également être respectées.


