Darwin
1.0.0
Organisation : Université de Nouvelle-Galles du Sud (UNSW) AI4Science & GreenDynamics AI
Darwin est un projet open source dédié au pré-entraînement et à l'affinement du modèle LLaMA sur la littérature scientifique et les ensembles de données. Spécialement conçu pour le domaine scientifique en mettant l'accent sur la science des matériaux, la chimie et la physique, Darwin intègre des connaissances scientifiques structurées et non structurées pour améliorer l'efficacité des modèles de langage dans la recherche scientifique.
Avis d'utilisation et de licence : Darwin est sous licence et destiné à un usage de recherche uniquement. L'ensemble de données est sous licence CC BY NC 4.0, permettant une utilisation non commerciale. Les modèles formés à l’aide de cet ensemble de données ne doivent pas être utilisés en dehors des fins de recherche. La différence de poids est également sous licence CC BY NC 4.0
[2024.11.20]
Réalisations clés
Informations sur les performances du modèle
Stratégies et informations sur les données
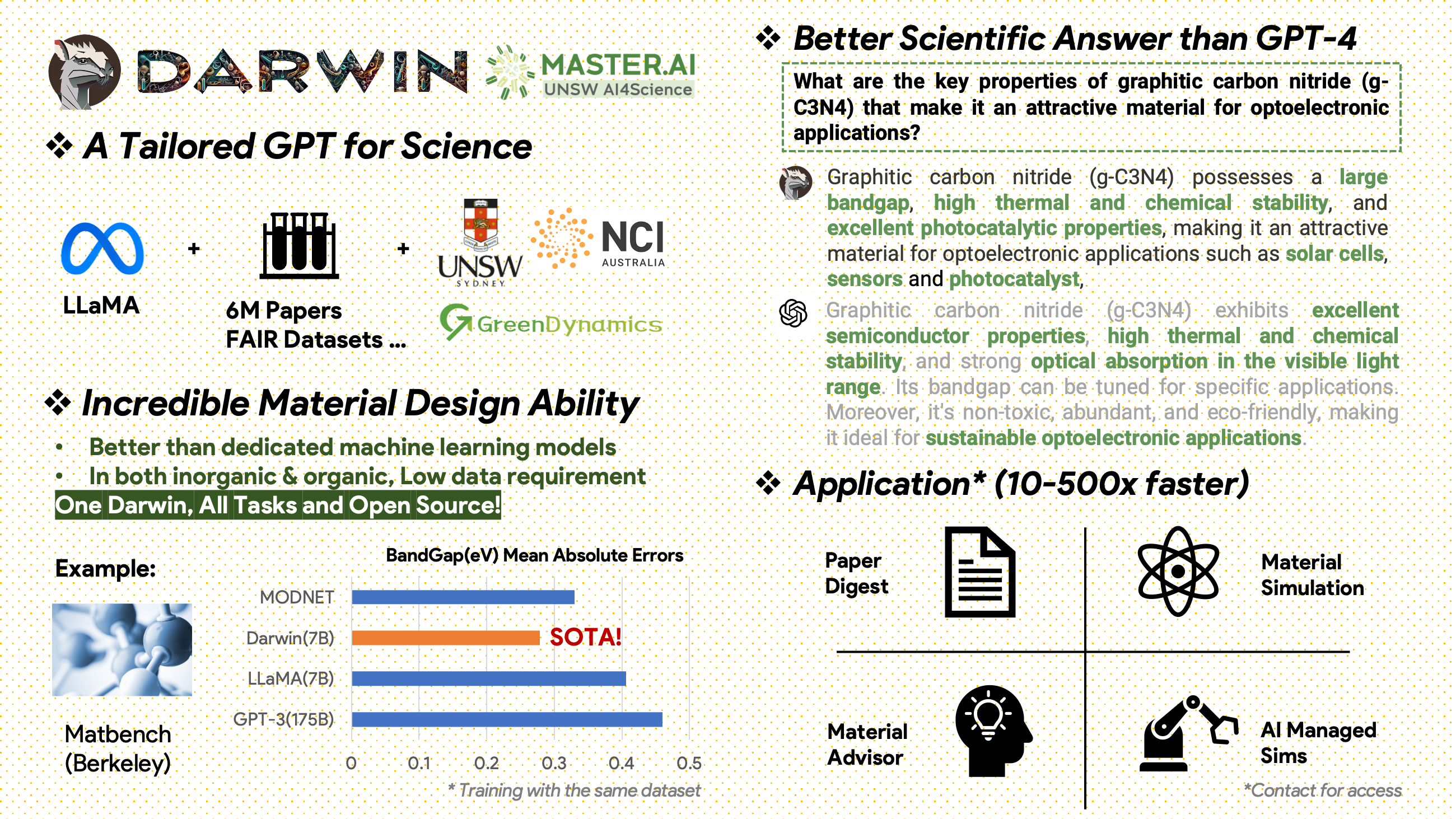
[2024.02.15] SOTA dans MatBench par Material Projects : DARWIN est le modèle SOTA dans les tâches expérimentales de prédiction de bande interdite et les tâches de classification métallique, meilleur que GPT3.5 affiné et les modèles ML dédiés. https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15]Version Google Colab disponible : Essayez notre DARWIN avec Google Colab : inference.ipynb
Darwin, basé sur le modèle 7B LLaMA, est formé sur plus de 100 000 points de données de suivi d'instructions générés par le générateur d'instructions scientifiques (SIG) Darwin à partir de divers ensembles de données scientifiques FAIR et d'un corpus de littérature. En se concentrant sur l'exactitude factuelle des réponses du modèle, Darwin représente un pas important vers l'exploitation des grands modèles linguistiques (LLM) pour la découverte scientifique. Les évaluations humaines préliminaires indiquent que Darwin 7B surpasse le GPT-4 en termes de questions et réponses scientifiques et que le GPT-3 affiné dans la résolution de problèmes chimiques (comme gptChem).
Nous développons activement Darwin pour des expériences scientifiques plus avancées, et nous intégrons également Darwin à LangChain pour résoudre des tâches scientifiques plus complexes (comme un assistant de recherche privé pour ordinateurs personnels).
Veuillez noter que Darwin est encore en développement et que de nombreuses limitations doivent être corrigées. Plus important encore, nous devons encore peaufiner Darwin pour une sécurité maximale. Nous encourageons les utilisateurs à signaler tout comportement préoccupant afin de contribuer à améliorer la sécurité et les considérations éthiques du modèle.
LIEN DE DÉMO
Installez d'abord la configuration requise :
pip install -r requirements.txtTéléchargez les points de contrôle des poids Darwin-7B depuis onedrive. Une fois le modèle téléchargé, vous pouvez essayer notre démo :
python inference.py < your path to darwin-7b >Veuillez noter que l'inférence nécessite au moins 10 Go de mémoire GPU pour Darwin 7B.
Pour affiner davantage notre Darwin-7b avec différents ensembles de données, vous trouverez ci-dessous une commande qui fonctionne sur une machine équipée de 4 GPU A100 80G.
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 FalseNos données proviennent de deux sources principales :
Un corpus de littérature brute contenant 6 millions d'articles sur la science des matériaux, la chimie et la physique a été publié après 2000. Les éditeurs comprennent ACS, RSC, Springer Nature, Wiley et Elsevier. Nous les remercions pour leur soutien.
Ensembles de données FAIR - Nous avons collecté des données à partir de 16 ensembles de données FAIR.
Nous avons développé Darwin-SIG pour générer des instructions scientifiques. Il peut mémoriser des textes longs à partir de textes de littérature complète (en moyenne ~ 5 000 mots) et générer des données de questions et réponses (Q&A) basées sur des mots-clés de littérature scientifique (à partir de l'API Web of Science)
Remarque : Vous pouvez également utiliser GPT3.5 ou GPT-4 pour la génération, mais ces options peuvent être coûteuses.
Veuillez noter que nous ne pouvons pas partager l'ensemble de données de formation en raison d'accords avec les éditeurs.
Ce projet est un effort collaboratif des acteurs suivants :
UNSW et GreenDynamics : Tong Xie, Shaozhou Wang
UNSW : Imran Razzak, Cody Huang
Centre USYD & DARE : Clara Grazian
GreenDynamics : Yuwei Wan, Yixuan Liu
Bram Hoex et Wenjie Zhang de UNSW Engineering ont conseillé tout le monde.
Si vous utilisez les données ou le code de ce référentiel dans votre travail, veuillez le citer en conséquence.
Modèle de langage large fondamental DAWRIN et réglage fin des instructions semi-automatiques
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
GPT-3 et LLaMA affinés pour la découverte de matériaux (formation à tâche unique)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
Ce projet a fait référence aux projets open source suivants :
Un merci spécial à NCI Australie pour son support HPC.
Nous élargissons continuellement l'équipe de développement de Darwin. Rejoignez-nous dans ce voyage passionnant pour faire progresser la recherche scientifique avec l’IA !
Pour les postes de doctorat ou de postdoctorat, veuillez contacter [email protected] ou [email protected] pour plus de détails.
Pour d'autres postes, veuillez visiter www.greendynamics.com.au


