paxml
paxml release 1.4.0
Pax est un framework permettant de configurer et d'exécuter des expériences d'apprentissage automatique sur Jax.
Nous nous référons à cette page pour une documentation plus exhaustive sur le démarrage d'un projet Cloud TPU. La commande suivante est suffisante pour créer une VM Cloud TPU avec 8 cœurs à partir d'une machine d'entreprise.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR Si vous utilisez des tranches TPU Pod, veuillez vous référer à ce guide. Exécutez toutes les commandes depuis une machine locale à l'aide de gcloud avec l'option --worker=all :
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "Les sections de démarrage rapide suivantes supposent que vous exécutez sur un TPU à hôte unique, vous pouvez donc vous connecter à la machine virtuelle et y exécuter les commandes.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEAprès avoir connecté la VM en SSH, vous pouvez installer la version stable de paxml à partir de PyPI ou la version dev à partir de github.
Pour installer la version stable de PyPI (https://pypi.org/project/paxml/) :
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html Si vous rencontrez des problèmes avec les dépendances transitives et que vous utilisez l'environnement natif de machine virtuelle Cloud TPU, veuillez accéder à la branche de version correspondante rX.YZ et télécharger paxml/pip_package/requirements.txt . Ce fichier inclut les versions exactes de toutes les dépendances transitives nécessaires dans l'environnement natif de VM Cloud TPU, dans lequel nous construisons/testons la version correspondante.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtPour installer la version de développement depuis github et pour faciliter l'édition du code :
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=TrueVeuillez visiter notre dossier Docs pour les documentations et les didacticiels Jupyter Notebook. Veuillez consulter la section suivante pour obtenir des instructions sur l'exécution de Jupyter Notebooks sur une VM Cloud TPU.
Vous pouvez exécuter les exemples de notebooks dans la machine virtuelle TPU dans laquelle vous venez d'installer paxml. ####Étapes pour activer un notebook dans une v4-8
ssh dans la VM TPU avec transfert de port gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
installez le notebook jupyter sur la machine virtuelle TPU et rétrogradez markupsafe
pip install notebook
pip install markupsafe==2.0.1
exporter le chemin jupyter export PATH=/home/$USER/.local/bin:$PATH
scp les exemples de notebooks sur votre VM TPU gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
démarrez jupyter notebook à partir de la machine virtuelle TPU et notez le jeton généré par jupyter notebook jupyter notebook --no-browser --port=8080
puis dans votre navigateur local allez sur : http://localhost:8080/ et entrez le jeton fourni
Remarque : Si vous devez commencer à utiliser un deuxième ordinateur portable alors que le premier ordinateur portable occupe toujours les TPU, vous pouvez exécuter pkill -9 python3 pour libérer les TPU.
Remarque : NVIDIA a publié une version mise à jour de Pax avec la prise en charge du H100 FP8 et de larges améliorations des performances du GPU. Veuillez visiter le référentiel NVIDIA Rosetta pour plus de détails et d'instructions d'utilisation.
Le flux de travail PGLE (Profile Guided Latency Estimator) mesure le temps d'exécution réel du calcul et des collectifs, les informations de profil sont renvoyées au compilateur XLA pour une meilleure décision de planification.
L’estimateur de latence guidé par profil peut être utilisé manuellement ou automatiquement. En mode automatique, JAX collectera les informations de profil et recompilera un module en une seule fois. En mode manuel, vous devez exécuter une tâche deux fois, la première fois pour collecter et enregistrer des profils et la seconde pour compiler et exécuter avec les données fournies.
Le PGLE automatique peut être activé en définissant les variables d'environnement suivantes :
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
Ou dans JAX, cela peut être défini comme suit :
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
Vous pouvez contrôler le nombre de réexécutions utilisées pour collecter les données de profil en modifiant JAX_PGLE_PROFILING_RUNS . L'augmentation de ce paramètre entraînerait de meilleures informations de profil, mais cela augmenterait également le nombre d'étapes de formation non optimisées.
Les paramètres JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY permettent d'utiliser les rappels d'hôte avec le PGLE automatique.
La diminution du paramètre JAX_PGLE_AGGREGATION_PERCENTILE peut être utile dans le cas où les performances entre les étapes sont trop bruyantes pour filtrer les mesures non pertinentes.
Attention : Auto PGLE ne fonctionne pas pour les modules précompilés. Puisque JAX doit recompiler le module lors de l'exécution, le PGLE automatique ne fonctionnera ni pour AoT ni pour le cas suivant :
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
Si vous souhaitez toujours utiliser un estimateur de latence guidé par profil manuel, le flux de travail dans XLA/GPU est :
Vous pouvez le faire en définissant :
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) Après cette étape, vous obtiendrez un fichier profile.pb sous le rundir imprimé dans le code.
Vous devez transmettre le fichier profile.pb à l'indicateur --xla_gpu_pgle_profile_file_or_directory_path .
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " Pour activer la journalisation dans XLA et vérifier si le profil est bon, définissez le niveau de journalisation pour inclure INFO :
export TF_CPP_MIN_LOG_LEVEL=0Exécutez le vrai workflow, si vous avez trouvé ces enregistrements dans le journal en cours d'exécution, cela signifie que le profileur est utilisé dans le planificateur de masquage de latence :
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax fonctionne sur Jax, vous pouvez trouver des détails sur l'exécution de tâches Jax sur Cloud TPU ici, vous pouvez également trouver des détails sur l'exécution de tâches Jax sur un pod Cloud TPU ici
Si vous rencontrez des erreurs de dépendance, veuillez vous référer au fichier requirements.txt dans la branche correspondant à la version stable que vous installez. Par exemple, pour la version stable 0.4.0, utilisez la branche r0.4.0 et reportez-vous au fichier conditions.txt pour les versions exactes des dépendances utilisées pour la version stable.
Voici quelques exemples d’exécutions de convergence sur l’ensemble de données c4.
Vous pouvez exécuter un modèle de paramètres 1B sur l'ensemble de données c4 sur TPU v4-8 à l'aide de la configuration C4Spmd1BAdam4Replicas de c4.py comme suit :
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
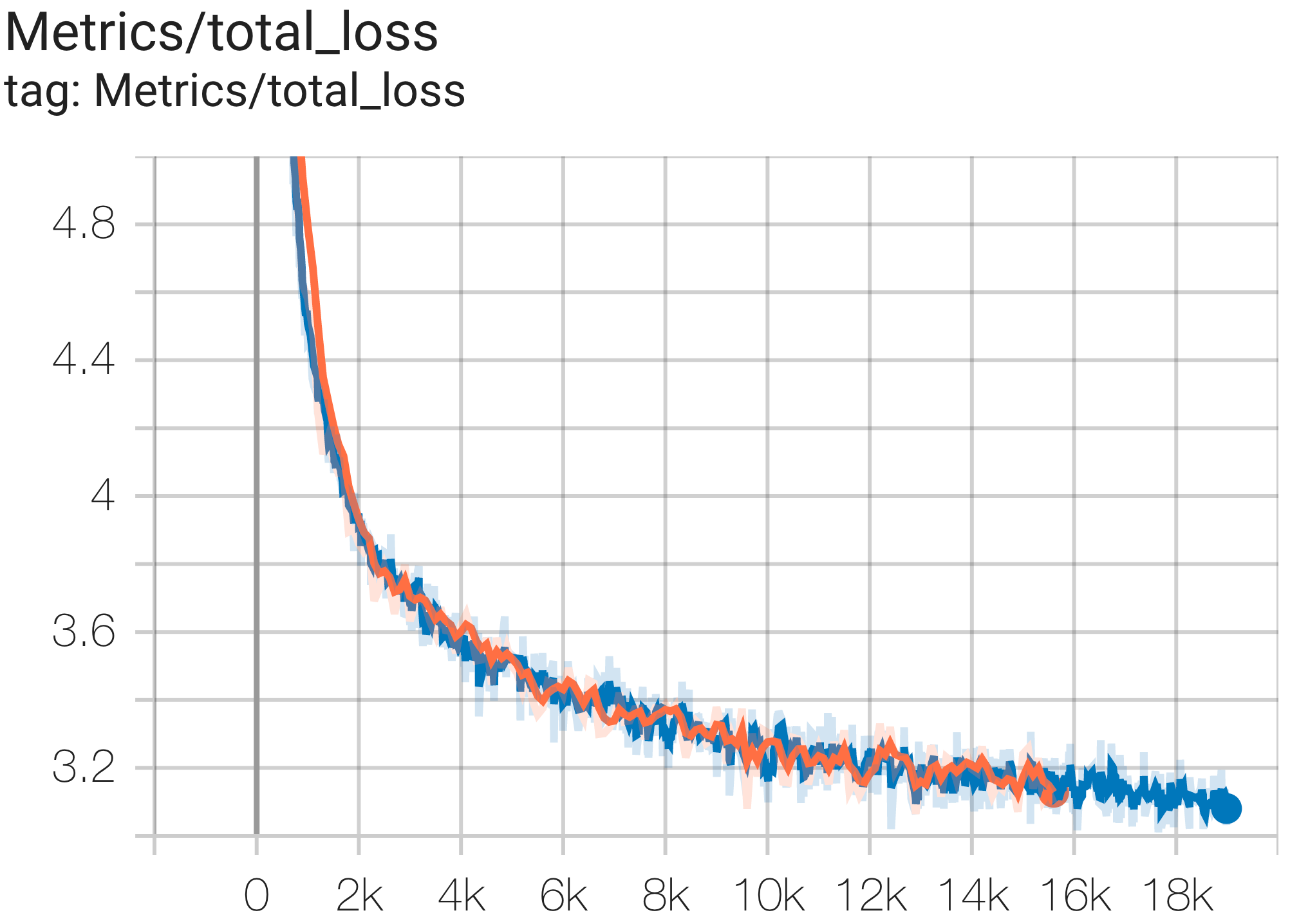
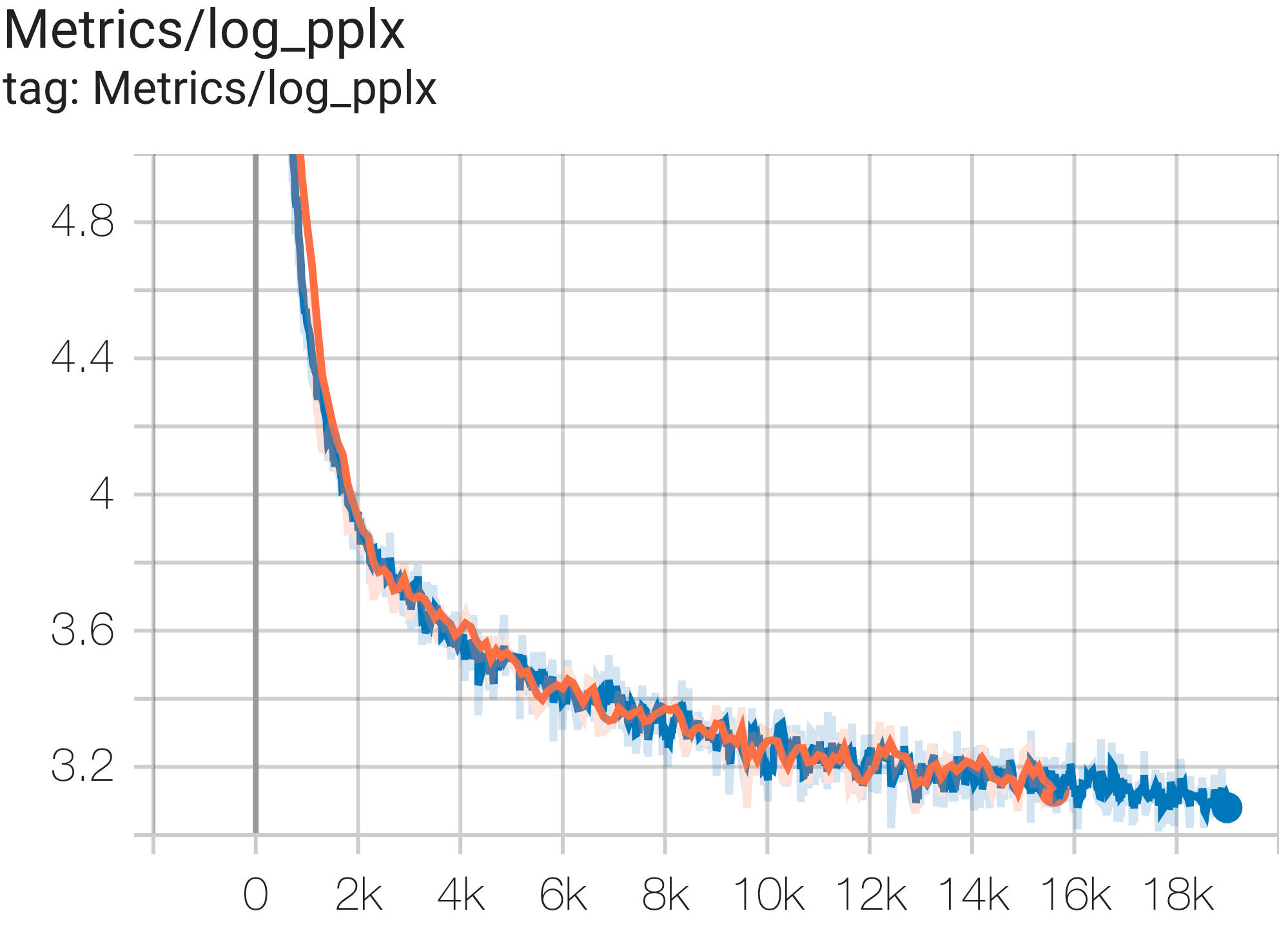
--job_log_dir=gs:// < your-bucket > Vous pouvez observer la courbe de perte et le graphique log perplexity comme suit :
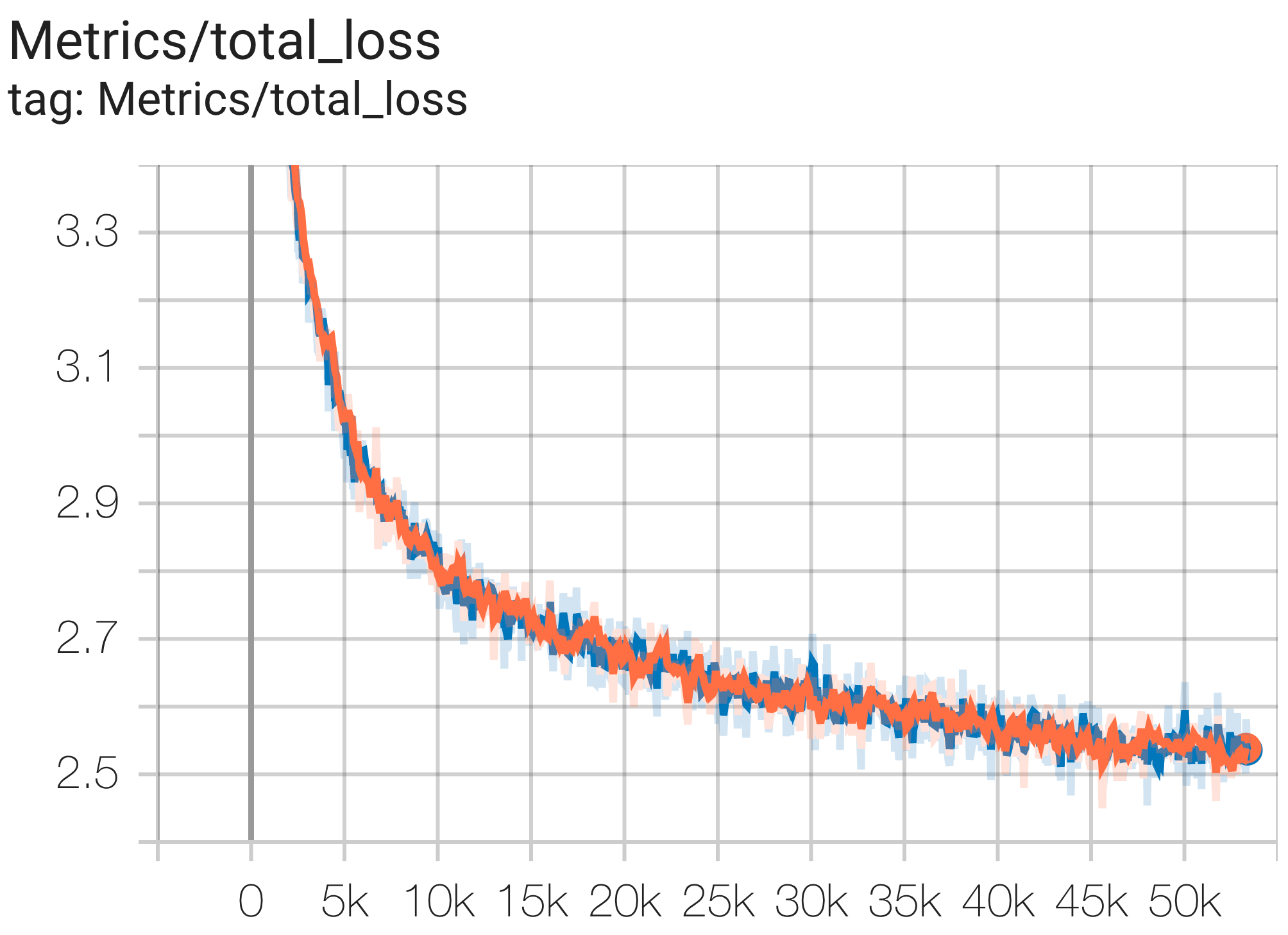
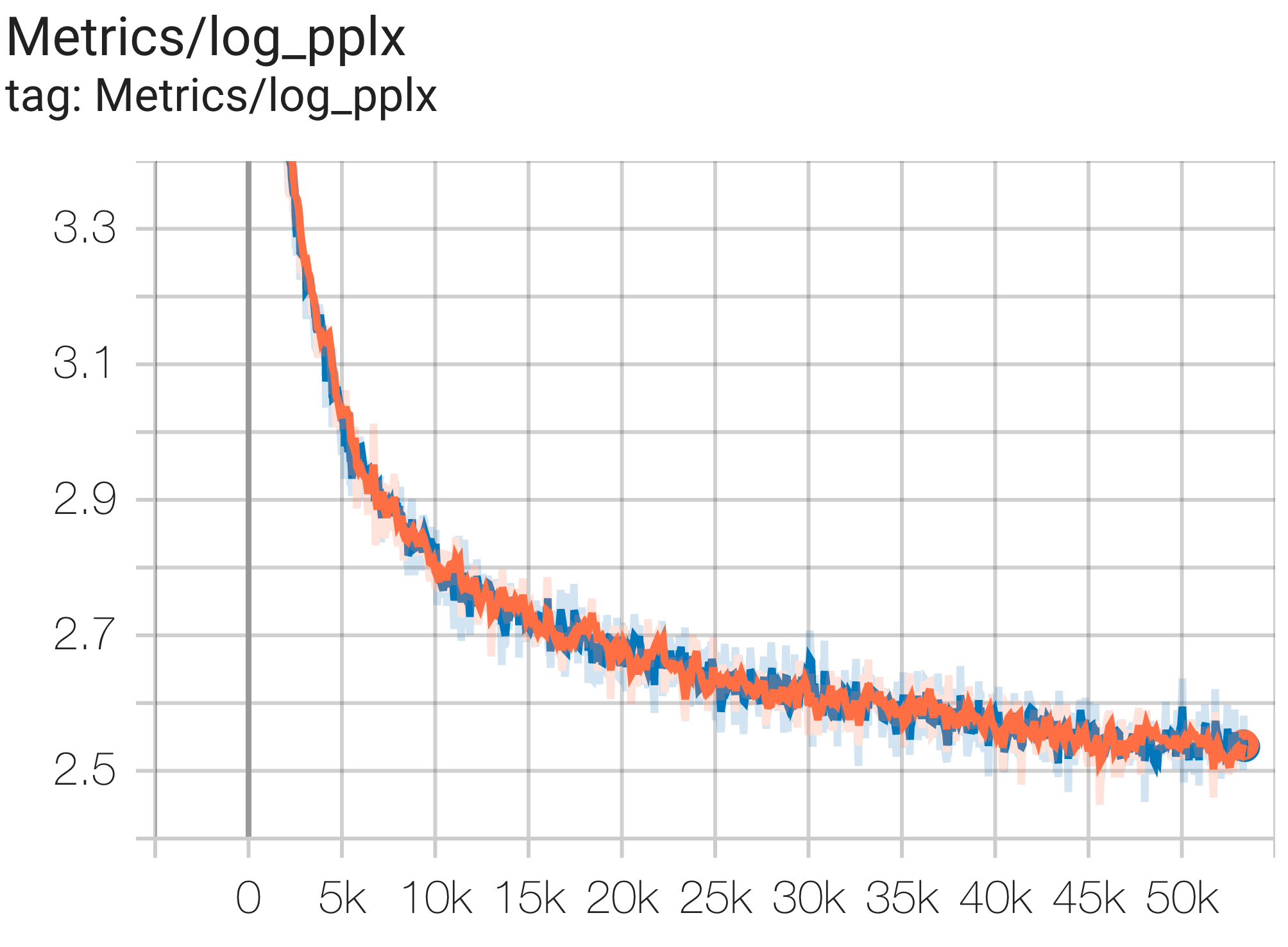
Vous pouvez exécuter un modèle de paramètres 16B sur l'ensemble de données c4 sur TPU v4-64 à l'aide de la configuration C4Spmd16BAdam32Replicas de c4.py comme suit :
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > Vous pouvez observer la courbe de perte et le graphique log perplexity comme suit :
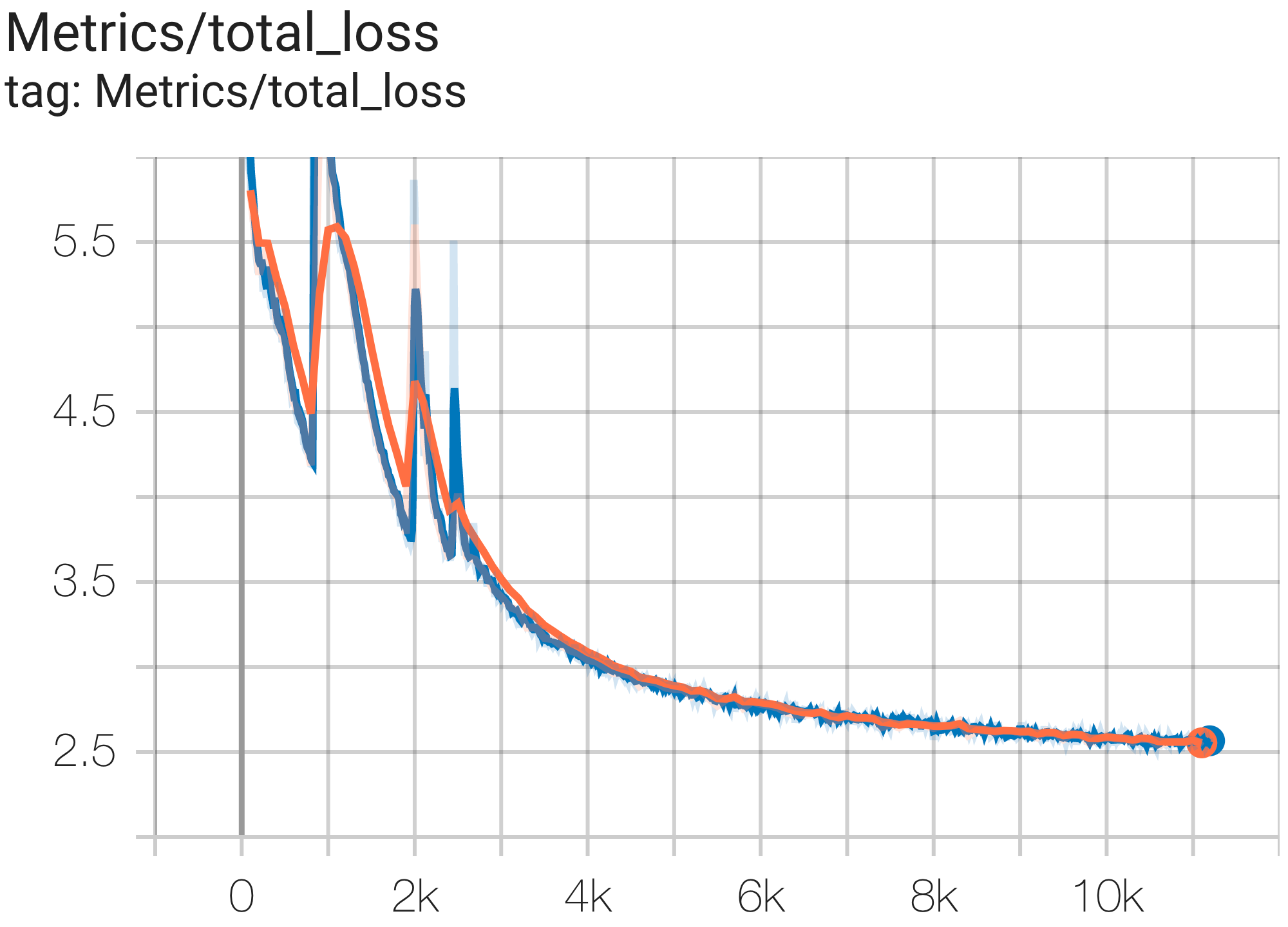
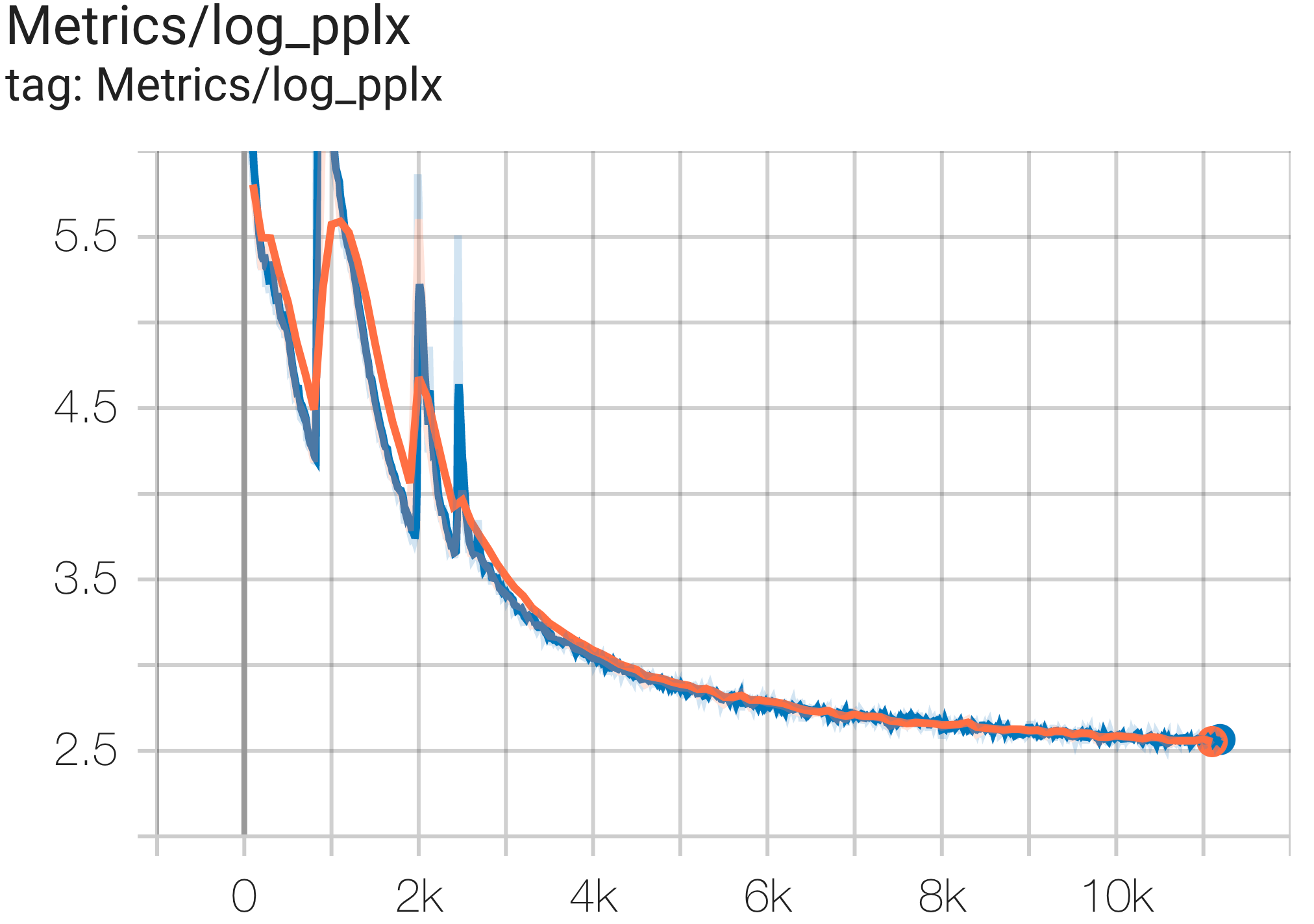
Vous pouvez exécuter le modèle GPT3-XL sur l'ensemble de données c4 sur TPU v4-128 à l'aide de la configuration C4SpmdPipelineGpt3SmallAdam64Replicas de c4.py comme suit :
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > Vous pouvez observer la courbe de perte et le graphique log perplexity comme suit :
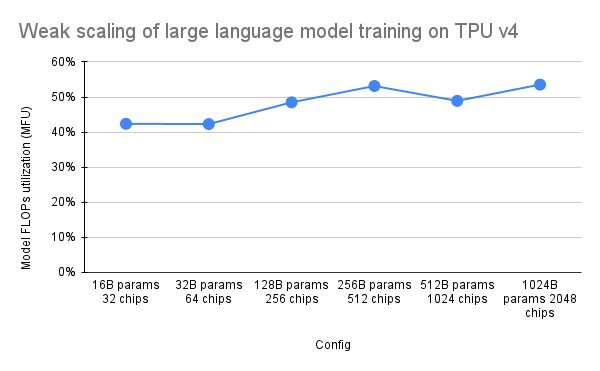
L'article PaLM a introduit une mesure d'efficacité appelée Utilisation des FLOP modèles (MFU). Ceci est mesuré comme le rapport entre le débit observé (en jetons par seconde, par exemple pour un modèle de langage) et le débit maximum théorique d'un système exploitant 100 % des FLOP de pointe. Il diffère des autres méthodes de mesure de l'utilisation du calcul car il n'inclut pas les FLOP dépensés pour la rematérialisation de l'activation lors de la passe arrière, ce qui signifie que l'efficacité telle que mesurée par MFU se traduit directement par la vitesse d'entraînement de bout en bout.
Pour évaluer le MFU d'une classe clé de charges de travail sur les pods TPU v4 avec Pax, nous avons mené une campagne de référence approfondie sur une série de configurations de modèle de langage Transformer (GPT) uniquement pour décodeur, dont la taille varie de milliards à des milliards de paramètres. sur l'ensemble de données c4. Le graphique suivant montre l'efficacité de la formation en utilisant le modèle de « mise à l'échelle faible » dans lequel nous avons augmenté la taille du modèle proportionnellement au nombre de puces utilisées.
Les configurations multislices dans ce dépôt font référence à 1. Configurations de tranche unique pour la syntaxe/architecture de modèle et 2. Repo MaxText pour les valeurs de configuration.
Nous fournissons des exemples d'exécution sous c4_multislice.py` comme point de départ pour Pax sur multislice.
Nous nous référons à cette page pour une documentation plus exhaustive sur l'utilisation des ressources en file d'attente pour un projet Cloud TPU multi-tranches. Ce qui suit montre les étapes nécessaires pour configurer les TPU pour exécuter des exemples de configuration dans ce référentiel.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run Supposons que pour exécuter C4Spmd22BAdam2xv4_128 sur 2 tranches de la v4-128, vous devez configurer les TPU de la manière suivante :
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX Les commandes de configuration décrites précédemment doivent être exécutées sur TOUS les nœuds de calcul dans TOUTES les tranches. Vous pouvez 1) accéder à chaque travailleur et à chaque tranche individuellement ; ou 2) utilisez la boucle for avec --worker=all comme commande suivante.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done Afin d'exécuter les configurations multislice, ouvrez le même nombre de terminaux que votre $NODE_COUNT. Pour nos expériences sur 2 tranches ( C4Spmd22BAdam2xv4_128 ), ouvrez deux terminaux. Ensuite, exécutez chacune de ces commandes individuellement depuis chaque terminal.
Depuis le terminal 0, exécutez la commande d'entraînement pour la tranche 0 comme suit :
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Depuis le terminal 1, exécutez simultanément la commande de formation pour la tranche 1 comme suit :
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Ce tableau couvre les détails sur la façon dont les noms de variables MaxText ont été traduits en Pax.
Notez que MaxText a une "échelle" qui est multipliée par plusieurs paramètres (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) pour les valeurs finales.
Une autre chose à mentionner est que si Pax couvre DCN et ICN MESH_SHAPE sous forme de tableau, dans MaxText, il existe des variables distinctes de data_parallelism, fsdp_parallelism et tensor_parallelism pour DCN et ICI. Puisque ces valeurs sont définies sur 1 par défaut, seules les variables dont la valeur est supérieure à 1 sont enregistrées dans cette table de traduction.
Autrement dit, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] et DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| Pax C4Spmd22BAdam2xv4_128 | MaxText 2xv4-128.sh | (une fois l'échelle appliquée) | ||
|---|---|---|---|---|
| échelle (appliquée aux 4 variables suivantes) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| MODÈLE_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | head_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | par_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | taille_vocabule | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | type | bfloat16 | |
| USE_REPEATED_LAYER | VRAI | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_parallélisme | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_parallélisme | 2 |
L'entrée est une instance de la classe BaseInput permettant d'obtenir des données dans le modèle pour l'entraînement/l'évaluation/le décodage.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass Il agit comme un itérateur : get_next() renvoie un NestedMap , où chaque champ est un tableau numérique avec la taille du lot comme dimension principale.
Chaque entrée est configurée par une sous-classe de BaseInput.HParams . Dans cette page, nous utilisons p pour désigner une instance de BaseInput.Params , et elle est instanciée en input .
Dans Pax, les données sont toujours multi-hôtes : chaque processus Jax aura une input distincte et indépendante instanciée. Leurs paramètres auront p.infeed_host_index différent, défini automatiquement par Pax.
Par conséquent, la taille du lot local observée sur chaque hôte est p.batch_size et la taille du lot global est (p.batch_size * p.num_infeed_hosts) . On verra souvent p.batch_size défini sur jax.local_device_count() * PERCORE_BATCH_SIZE .
En raison de cette nature multihôte, input doivent être partitionnées correctement.
Pour la formation, chaque input ne doit jamais émettre de lots identiques, et pour une évaluation sur un ensemble de données fini, chaque input doit se terminer après le même nombre de lots. La meilleure solution consiste à ce que l'implémentation d'entrée partitionne correctement les données, de sorte que chaque input sur différents hôtes ne se chevauche pas. À défaut, on peut également utiliser différentes graines aléatoires pour éviter les lots en double lors de la formation.
input.reset() n'est jamais appelé sur les données d'entraînement, mais il peut le faire pour évaluer (ou décoder) des données.
Pour chaque exécution d'évaluation (ou de décodage), Pax récupère N lots de input en appelant input.get_next() N fois. Le nombre de lots utilisés, N , peut être un nombre fixe spécifié par l'utilisateur, via p.eval_loop_num_batches ; ou N peut être dynamique ( p.eval_loop_num_batches=None ), c'est-à-dire que nous appelons input.get_next() jusqu'à ce que nous épuisions toutes ses données (en augmentant StopIteration ou tf.errors.OutOfRange ).
Si p.reset_for_eval=True , p.eval_loop_num_batches est ignoré et N est déterminé dynamiquement comme le nombre de lots pour épuiser les données. Dans ce cas, p.repeat doit être défini sur False, sinon cela conduirait à un décodage/évaluation infini.
Si p.reset_for_eval=False , Pax récupérera les lots p.eval_loop_num_batches . Cela doit être défini avec p.repeat=True afin que les données ne soient pas épuisées prématurément.
Notez que les entrées LingvoEvalAdaptor nécessitent p.reset_for_eval=True .
N : statique | N : dynamique | |
|---|---|---|
p.reset_for_eval=True | Chaque exécution d'évaluation utilise le | Une époque par exécution d'évaluation. |
: : premiers N lots. Non : eval_loop_num_batches : | ||
| : : encore pris en charge. : est ignoré. La saisie doit : | ||
| : : : être fini : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | Chaque exécution d'évaluation utilise | Non pris en charge. |
: : non chevauchant N : : | ||
| : : lots en roulage : : | ||
| : : base, selon : : | ||
: : eval_loop_num_batches : : | ||
| : : . La saisie doit être répétée : : | ||
| : : indéfiniment : : | ||
: : ( p.repeat=True ) ou : : | ||
| : sinon peut augmenter : | ||
| : : exception : : |
Si vous exécutez decode/eval exactement à une époque (c'est-à-dire lorsque p.reset_for_eval=True ), l'entrée doit gérer correctement le partitionnement de sorte que chaque fragment apparaisse à la même étape après la production exacte du même nombre de lots. Cela signifie généralement que l'entrée doit compléter les données d'évaluation. Cela est effectué automatiquement par SeqIOInput et LingvoEvalAdaptor (voir plus ci-dessous).
Pour la majorité des entrées, nous n'appelons get_next() que pour obtenir des lots de données. Un type de données d'évaluation constitue une exception à cette règle, où « comment calculer les métriques » est également défini sur l'objet d'entrée.
Ceci n'est pris en charge qu'avec SeqIOInput qui définit un benchmark d'évaluation canonique. Plus précisément, Pax utilise predict_metric_fns et score_metric_fns() définis sur la tâche SeqIO pour calculer les métriques d'évaluation (bien que Pax ne dépende pas directement de l'évaluateur SeqIO).
Lorsqu'un modèle utilise plusieurs entrées, soit entre l'entraînement/l'évaluation, soit entre des données d'entraînement différentes entre le pré-entraînement/le réglage fin, les utilisateurs doivent s'assurer que les tokenizers utilisés par les entrées sont identiques, en particulier lors de l'importation de différentes entrées implémentées par d'autres.
Les utilisateurs peuvent vérifier les tokenizers en décodant certains identifiants avec input.ids_to_strings() .
C'est toujours une bonne idée de vérifier les données en examinant quelques lots. Les utilisateurs peuvent facilement reproduire le paramètre dans un colab et inspecter les données :
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) Les données d’entraînement ne doivent généralement pas utiliser de graine aléatoire fixe. En effet, si la tâche de formation est anticipée, les données de formation commenceront à se répéter. En particulier, pour les entrées Lingvo, nous recommandons de définir p.input.file_random_seed = 0 pour les données d'entraînement.
Pour tester si le partitionnement est géré correctement, les utilisateurs peuvent définir manuellement différentes valeurs pour p.num_infeed_hosts, p.infeed_host_index et voir si les entrées instanciées émettent différents lots.
Pax prend en charge 3 types d'entrées : SeqIO, Lingvo et personnalisée.
SeqIOInput peut être utilisé pour importer des ensembles de données.
Les entrées SeqIO gèrent automatiquement le partitionnement et le remplissage corrects des données d'évaluation.
LingvoInputAdaptor peut être utilisé pour importer des ensembles de données.
L'entrée est entièrement déléguée à l'implémentation Lingvo, qui peut ou non gérer automatiquement le partitionnement.
Pour l'implémentation d'entrée Lingvo basée sur GenericInput utilisant un packing_factor fixe, nous vous recommandons d'utiliser LingvoInputAdaptorNewBatchSize pour spécifier une taille de lot plus grande pour l'entrée Lingvo interne et de mettre la taille de lot souhaitée (généralement beaucoup plus petite) sur p.batch_size .
Pour les données d'évaluation, nous vous recommandons d'utiliser LingvoEvalAdaptor pour gérer le partitionnement et le remplissage afin d'exécuter eval sur une époque.
Sous-classe personnalisée de BaseInput . Les utilisateurs implémentent leur propre sous-classe, généralement avec tf.data ou SeqIO.
Les utilisateurs peuvent également hériter d'une classe d'entrée existante pour personnaliser uniquement le post-traitement des lots. Par exemple:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchLes hyperparamètres jouent un rôle important dans la définition des modèles et la configuration des expériences.
Pour mieux s'intégrer aux outils Python, Pax/Praxis utilise un style de configuration basé sur une classe de données pythonique pour les hyperparamètres.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0Il est également possible d'imbriquer des classes de données HParams, dans l'exemple ci-dessous, l'attribut Linear_tpl est un Linear.HParams imbriqué.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )Un calque représente une fonction arbitraire éventuellement avec des paramètres pouvant être entraînés. Un calque peut contenir d’autres calques en tant qu’enfants. Les calques sont les éléments de base essentiels des modèles. Les calques héritent du Flax nn.Module.
Généralement, les calques définissent deux méthodes :
Cette méthode crée des poids pouvant être entraînés et des couches enfants.
Cette méthode définit la fonction de propagation directe, calculant certaines sorties en fonction des entrées. De plus, fprop peut ajouter des résumés ou suivre les pertes auxiliaires.
Fiddle est une bibliothèque de configuration open source Python conçue pour les applications ML. Pax/Praxis prend en charge l'interopérabilité avec Fiddle Config/Partial(s) et certaines fonctionnalités avancées telles que la vérification rapide des erreurs et les paramètres partagés.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )À l'aide de Fiddle, les couches peuvent être configurées pour être partagées (par exemple : instanciées une seule fois avec des poids pouvant être entraînés partagés).
Un modèle définit uniquement le réseau, généralement un ensemble de couches, et définit des interfaces pour interagir avec le modèle telles que le décodage, etc.
Voici quelques exemples de modèles de base :
Une tâche contient encore un modèle et un apprenant/optimiseur supplémentaire. La sous-classe Task la plus simple est une SingleTask qui nécessite les Hparams suivants :
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| Version PyPI | Commettre |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


