PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtTous les modèles seront automatiquement téléchargés. Vous pouvez également choisir de télécharger manuellement à partir de cette URL.
| Modèle | #Params | URL | Télécharger dans OpenXLab |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | VAE | VAE |
| PixArt-α-SAM-256 | 0,6 B | Version PixArt-XL-2-SAM-256x256.pth ou diffuseurs | 256-SAM |
| PixArt-α-256 | 0,6 B | PixArt-XL-2-256x256.pth ou version diffuseurs | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0,6 B | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0,6 B | PixArt-XL-2-512x512.pth ou version diffuseurs | 512 |
| PixArt-α-1024 | 0,6 B | PixArt-XL-2-1024-MS.pth ou version diffuseurs | 1024 |
| PixArt-δ-1024-LCM | 0,6 B | version diffuseurs | |
| Encodeur ControlNet-HED | 30M | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0,9 milliard | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0,9 milliard | PixArt-XL-2-1024-ControlNet.pth | 1024 |
Retrouvez AUSSI tous les modèles dans OpenXLab_PixArt-alpha
Tout d'abord.
Grâce à @kopyl, vous pouvez reproduire le flux complet d'entraînement sur l'ensemble de données Pokémon de HugginFace avec des cahiers :
Ensuite, pour plus de détails.
Ici, nous prenons comme exemple la configuration de formation de l'ensemble de données SAM, mais bien sûr, vous pouvez également préparer votre propre ensemble de données en suivant cette méthode.
Vous devez UNIQUEMENT modifier le fichier de configuration dans la configuration et le chargeur de données dans l'ensemble de données.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256La structure du répertoire pour l'ensemble de données SAM est la suivante :
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Ici, nous préparons data_toy pour une meilleure compréhension
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyEnsuite, voici un exemple de fichier partition/part0.txt.
De plus, pour la formation guidée sur les fichiers json, voici un fichier json jouet pour une meilleure compréhension.
Suivre les conseils de formation Pixart + DreamBooth
Suivre les conseils de formation PixArt + LCM
Suivre les conseils de formation PixArt + ControlNet
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16 L'inférence nécessite au moins 23GB de mémoire GPU pour utiliser ce dépôt, tandis que 11GB and 8GB sont utilisés dans ? diffuseurs.
Supporte actuellement :
Pour commencer, installez d’abord les dépendances requises. Assurez-vous d'avoir téléchargé les modèles dans le dossier output/pretrained_models, puis exécutez-les sur votre ordinateur local :
DEMO_PORT=12345 python app/app.pyComme alternative, un exemple de Dockerfile est fourni pour créer un conteneur d'exécution qui démarre l'application Gradio.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixartOu utilisez docker-compose. Notez que si vous souhaitez changer le contexte de la version 1024 à 512 ou LCM de l'application, modifiez simplement la variable d'environnement APP_CONTEXT dans le fichier docker-compose.yml. La valeur par défaut est 1024
docker compose build
docker compose up Jetons un coup d'œil à un exemple simple utilisant http://your-server-ip:12345 .
Assurez-vous de disposer des versions mises à jour des bibliothèques suivantes :
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4Et puis:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )Consultez la documentation pour plus d’informations sur SA-Solver Sampler.
Cette intégration permet d'exécuter le pipeline avec une taille de lot de 4 sous 11 Go de VRAM GPU. Consultez la documentation pour en savoir plus.
PixArtAlphaPipeline avec moins de 8 Go de VRAM GPULa consommation GPU VRAM inférieure à 8 Go est désormais prise en charge, veuillez vous référer à la documentation pour plus d'informations.
Pour commencer, installez d'abord les dépendances requises, puis exécutez sur votre ordinateur local :
# diffusers version
DEMO_PORT=12345 python app/app.py Jetons un coup d'œil à un exemple simple utilisant http://your-server-ip:12345 .
Vous pouvez également cliquer ici pour bénéficier d'un essai gratuit sur Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True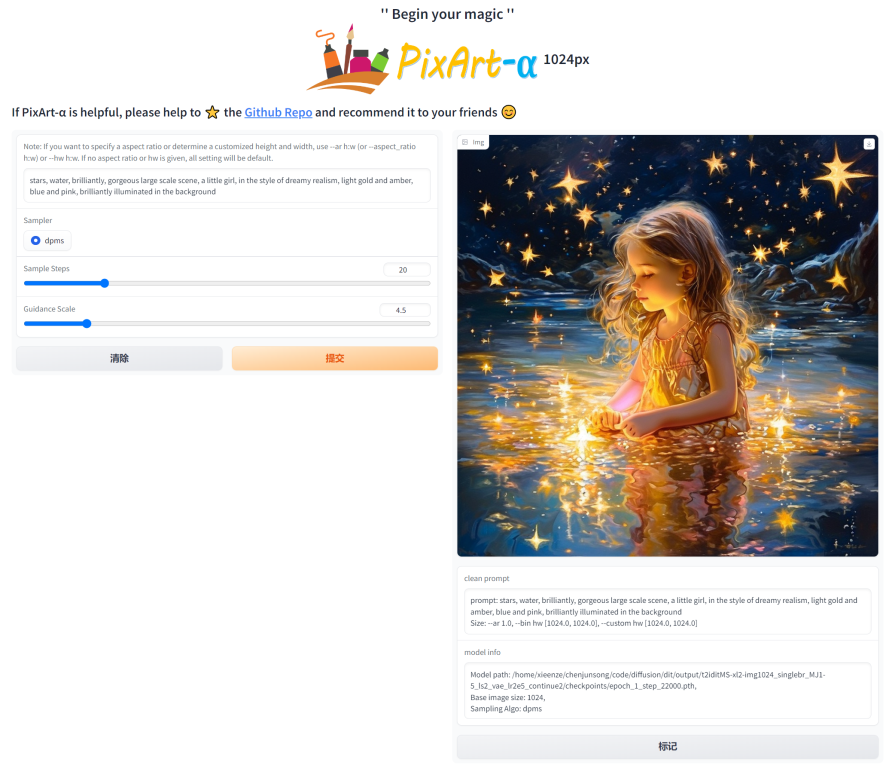
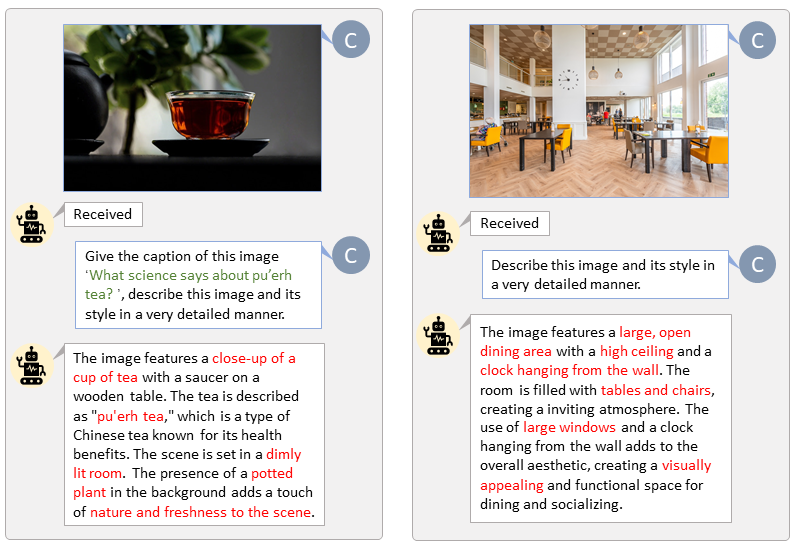
Grâce à la base de code de LLaVA-Lightning-MPT, nous pouvons légender le jeu de données LAION et SAM avec le code de lancement suivant :
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonNous présentons l'étiquetage automatique avec des invites personnalisées pour LAION (à gauche) et SAM (à droite). Les mots surlignés en vert représentent la légende originale de LAION, tandis que ceux marqués en rouge indiquent les légendes détaillées étiquetées par LLaVA.
Préparer à l'avance la fonction de texte T5 et la fonction d'image VAE accélérera le processus de formation et économisera la mémoire GPU.
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " Nous réalisons une vidéo comparant PixArt aux modèles Text-to-Image les plus puissants actuels.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


