Agent FLAN
1.0.0
[? Visage câlin] [? OpenXLab] [? Document] [ Page du projet]
Les grands modèles de langage (LLM) open source ont obtenu un grand succès dans diverses tâches de PNL, mais ils sont encore bien inférieurs aux modèles basés sur des API lorsqu'ils agissent en tant qu'agents. Comment intégrer les capacités des agents dans les LLM généraux devient un problème crucial et urgent. Cet article livre tout d'abord trois observations clés : (1) le corpus actuel de formation des agents est intriqué à la fois par le suivi des formats et par le raisonnement des agents, qui s'écarte considérablement de la distribution de ses données de pré-formation ; (2) Les LLM présentent différentes vitesses d'apprentissage sur les capacités requises par les tâches des agents ; et (3) les approches actuelles ont des effets secondaires en améliorant les capacités des agents en introduisant des hallucinations. Sur la base des résultats ci-dessus, nous proposons Agent-FLAN pour affiner efficacement les modèles de langage pour les agents. Grâce à une décomposition minutieuse et à une refonte du corpus de formation, Agent-FLAN permet à Llama2-7B de surpasser de 3,5 % les meilleurs travaux antérieurs sur divers ensembles de données d'évaluation d'agents. Avec des échantillons négatifs entièrement construits, Agent-FLAN atténue considérablement les problèmes d'hallucinations sur la base de notre référence d'évaluation établie. En outre, il améliore systématiquement la capacité des agents des LLM lors de la mise à l'échelle de la taille des modèles tout en améliorant légèrement la capacité générale des LLM.
Les séries Agent-FLAN sont affinées sur AgentInstruct et Toolbench en appliquant le pipeline de génération de données proposé dans l'article Agent-FLAN, qui possède de fortes capacités sur diverses tâches d'agent et utilisation des outils ~
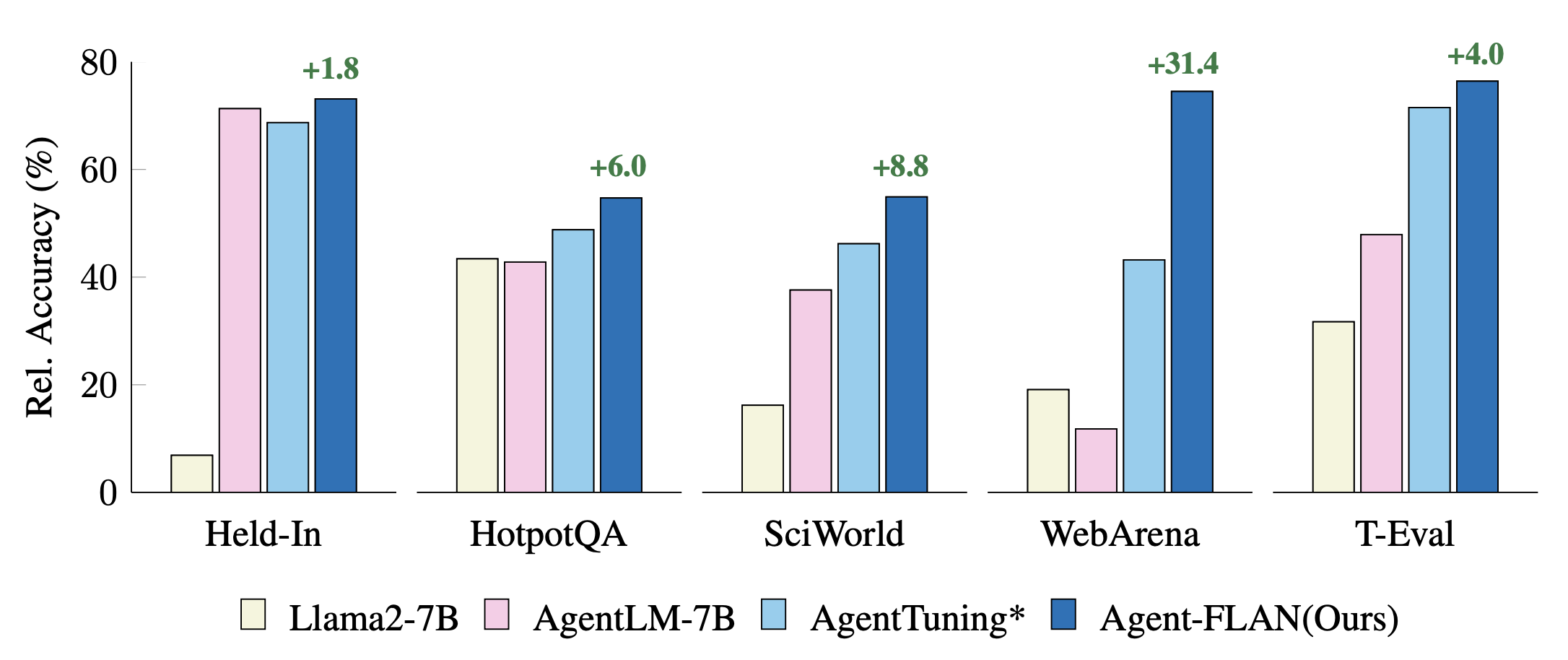
Comparaison des approches récentes de réglage des agents sur les tâches Held-In et Hold-Out. Les performances sont normalisées avec les résultats GPT-4 pour une meilleure visualisation. * désigne notre réimplémentation pour une comparaison équitable.
Agent-FLAN est produit par une formation mixte sur les ensembles de données AgentInstruct, ToolBench et ShareGPT de la série Llama2-chat.
Les modèles suivent le format de conversation de Llama-2-chat, avec le protocole de modèle comme suit :
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),Le modèle 7B est disponible sur le hub de modèles Huggingface & OpenXLab.
| Modèle | Repo Huggingface | Dépôt OpenXLab |
|---|---|---|
| Agent-FLAN-7B | Lien du modèle | Lien du modèle |
L'ensemble de données Agent-FLAN est également disponible sur le hub de l'ensemble de données Huggingface.
| Ensemble de données | Repo Huggingface |
|---|---|
| Agent-FLAN | Lien vers l'ensemble de données |
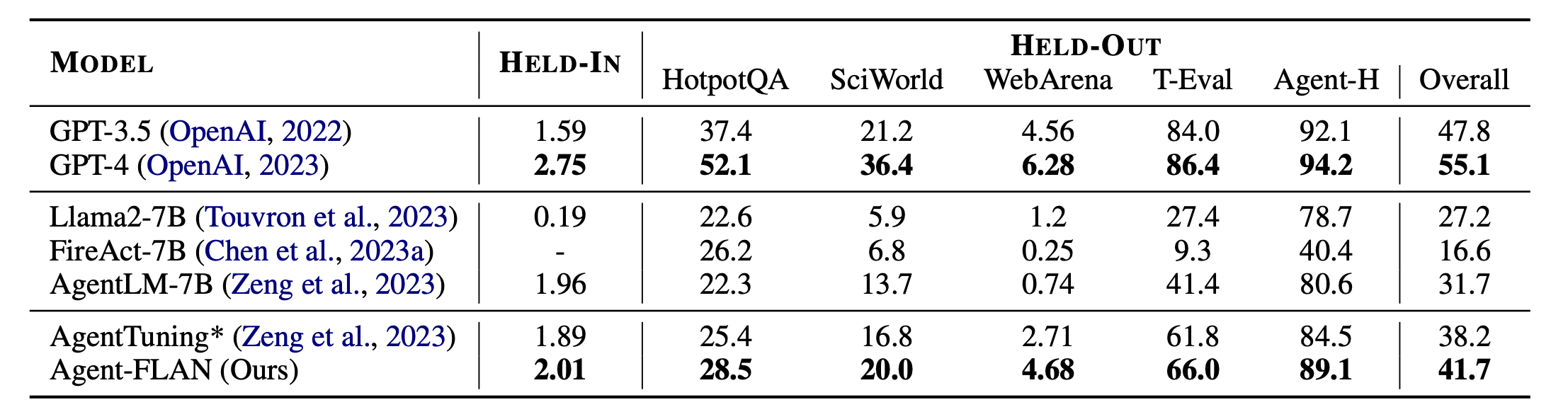
Principaux résultats de Agent-FLAN. Agent-FLAN surpasse largement les précédentes approches de réglage d'agent sur les tâches maintenues et suspendues. * désigne notre réimplémentation avec la même quantité de données d'entraînement pour une comparaison équitable. Étant donné que FireAct ne s'entraîne pas sur l'ensemble de données AgentInstruct, nous omettons ses performances sur l'ensemble HELD-IN. Audacieux : le meilleur des modèles basés sur API et open source.
Agent-FLAN est construit avec Lagent et T-Eval. Merci pour leur superbe travail !
Si vous trouvez ce projet utile dans votre recherche, pensez à citer :
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
Ce projet est publié sous la licence Apache 2.0.


