REaLTabFormer
v0.2.1
Le REaLTabFormer (Realistic Relational and Tabular Data using Transformers) offre un cadre unifié pour synthétiser des données tabulaires de différents types. Un modèle séquence à séquence (Seq2Seq) est utilisé pour générer des ensembles de données relationnelles synthétiques. Le modèle REaLTabFormer pour les données tabulaires non relationnelles utilise GPT-2 et peut être utilisé immédiatement pour modéliser n'importe quelle donnée tabulaire avec des observations indépendantes.
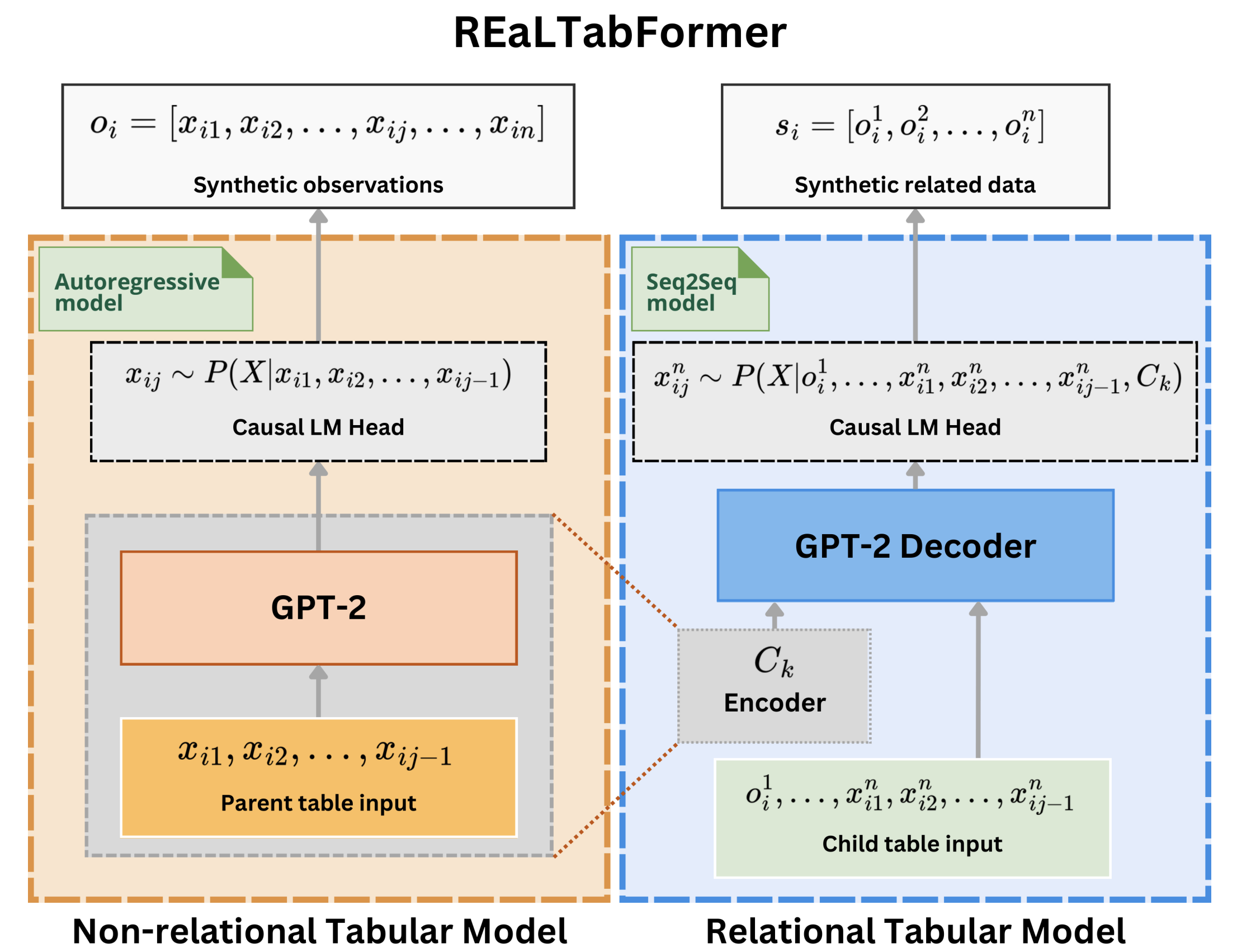
REaLTabFormer : génération de données relationnelles et tabulaires réalistes à l'aide de transformateurs
Article sur ArXiv
REaLTabFormer est disponible sur PyPi et peut être facilement installé avec pip (version Python >= 3.7) :
pip installer realtabformer
Nous montrons des exemples d'utilisation de REaLTabFormer pour modéliser et générer des données synthétiques à partir d'un modèle entraîné.
Note
Le modèle implémente un critère d'arrêt optimal basé sur la distribution des données synthétiques lors de la formation d'un modèle tabulaire non relationnel. Le modèle arrêtera l'entraînement lorsque la distribution des données synthétiques sera proche de la distribution des données réelles.
Assurez-vous de définir le paramètre epochs sur un nombre élevé pour permettre au modèle de mieux s'adapter aux données. Le modèle arrêtera l'entraînement lorsque le critère d'arrêt optimal sera rempli.
# pip install realtabformerimport pandas as pdfrom realtabformer import REaLTabFormerdf = pd.read_csv("foo.csv")# REMARQUE : supprimez tous les identifiants uniques dans les# données que vous ne souhaitez pas modéliser.# Table non relationnelle ou parent. rtf_model = REaLTabFormer(model_type="tabular",gradient_accumulation_steps=4,logging_steps=100)# Ajuster le modèle sur l'ensemble de données.# Des paramètres supplémentaires peuvent être# transmis à la méthode `.fit`.rtf_model.fit(df)# Enregistrez le modèle dans le répertoire actuel.# Un nouveau répertoire `rtf_model/` sera créé.# Dans celui-ci , un répertoire avec l'identifiant d'expérience du modèle `idXXXX` sera également créé# où les artefacts du modèle seront stockés.rtf_model.save("rtf_model/")# Générer des données synthétiques avec le même# nombre d'observations que le dataset réel.samples = rtf_model.sample(n_samples=len(df))# Charger le modèle enregistré. Le répertoire de l'expérience # doit être fourni.rtf_model2 = REaLTabFormer.load_from_dir(path="rtf_model/idXXXX") # pip install realtabformerimport osimport pandas as pdfrom pathlib import Pathfrom realtabformer import REaLTabFormerparent_df = pd.read_csv("foo.csv")child_df = pd.read_csv("bar.csv")join_on = "unique_id"# Assurez-vous que les colonnes clés dans la table # parent et la table enfant ont le même nom.assert ((join_on in parent_df.columns) et (join_on in child_df.columns))# Table non relationnelle ou parent. N'incluez pas le # unique_id field.parent_model = REaLTabFormer(model_type="tabular")parent_model.fit(parent_df.drop(join_on, axis=1))pdir = Path("rtf_parent/")parent_model.save(pdir)# # Obtenez le modèle parent enregistré le plus récemment,# # ou spécifiez un autre modèle enregistré.# parent_model_path = pdir / "idXXX"parent_model_path = trié([p pour p in pdir.glob("id*") if p.is_dir()],key=os.path.getmtime)[-1]child_model = REaLTabFormer(model_type="relational",parent_realtabformer_path=parent_model_path,output_max_length=None,train_size=0.8)child_model.fit(df=child_df,in_df=parent_df,join_on=join_on)# Générer des échantillons parents.parent_samples = parent_model.sample(len(parend_df ))# Créez les identifiants uniques basés sur sur l'index.parent_samples.index.name = join_onparent_samples = parent_samples.reset_index()# Générer les observations relationnelles.child_samples = child_model.sample(input_unique_ids=parent_samples[join_on],input_df=parent_samples.drop(join_on, axis=1),gen_batch =64) Le framework REaLTabFormer fournit une interface permettant de créer facilement des validateurs d'observation pour filtrer les échantillons synthétiques non valides. Nous montrons ci-dessous un exemple d'utilisation du GeoValidator . Le graphique de gauche montre la répartition de la latitude et de la longitude générées sans validation. Le graphique de droite montre les échantillons synthétiques avec des observations validées à l'aide du GeoValidator avec la frontière californienne. Pourtant, même lorsque nous n'avons pas entraîné le modèle de manière optimale pour générer cela, les échantillons invalides (se trouvant en dehors des limites) sont rares à partir des données générées sans validateur.
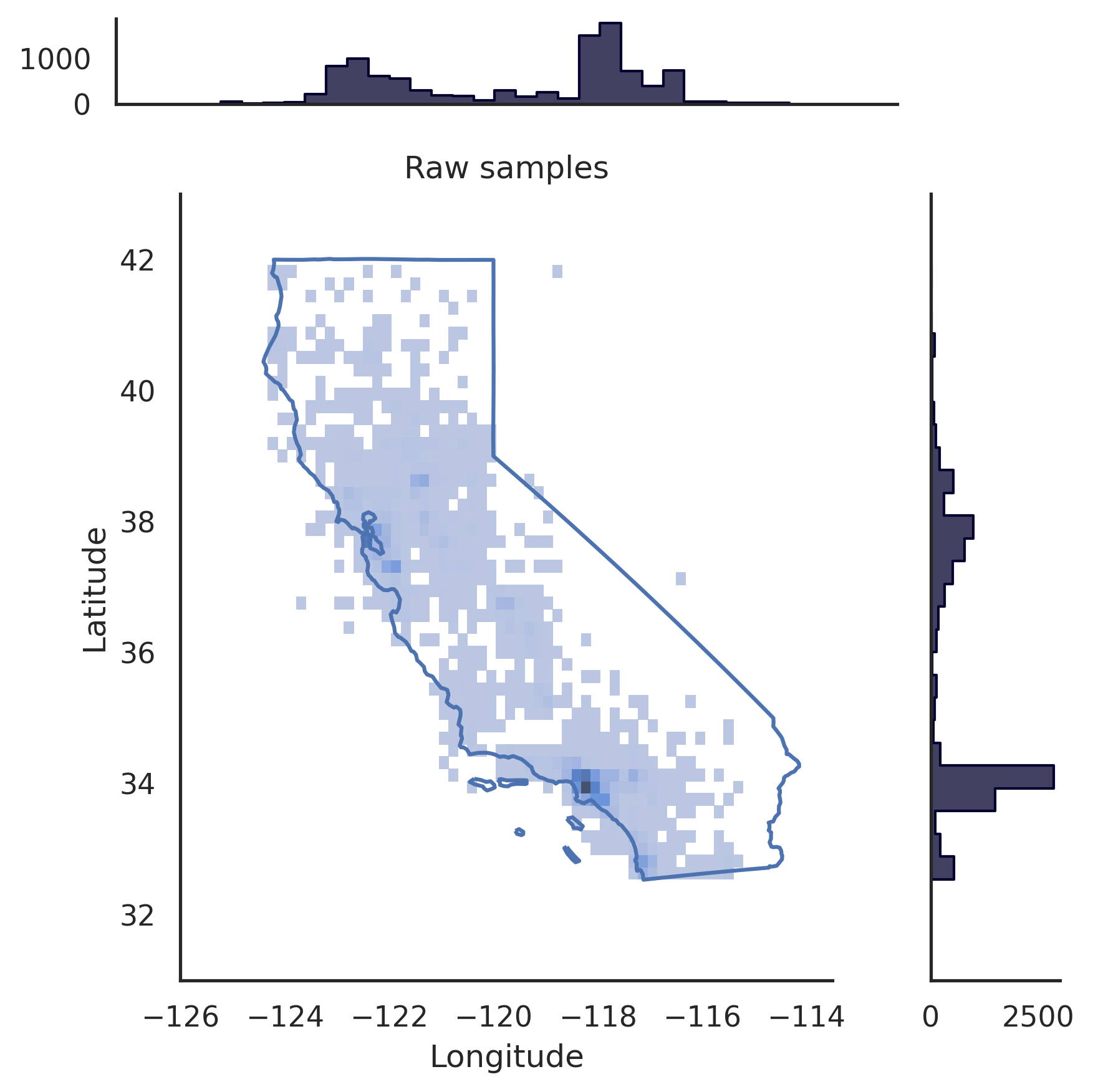
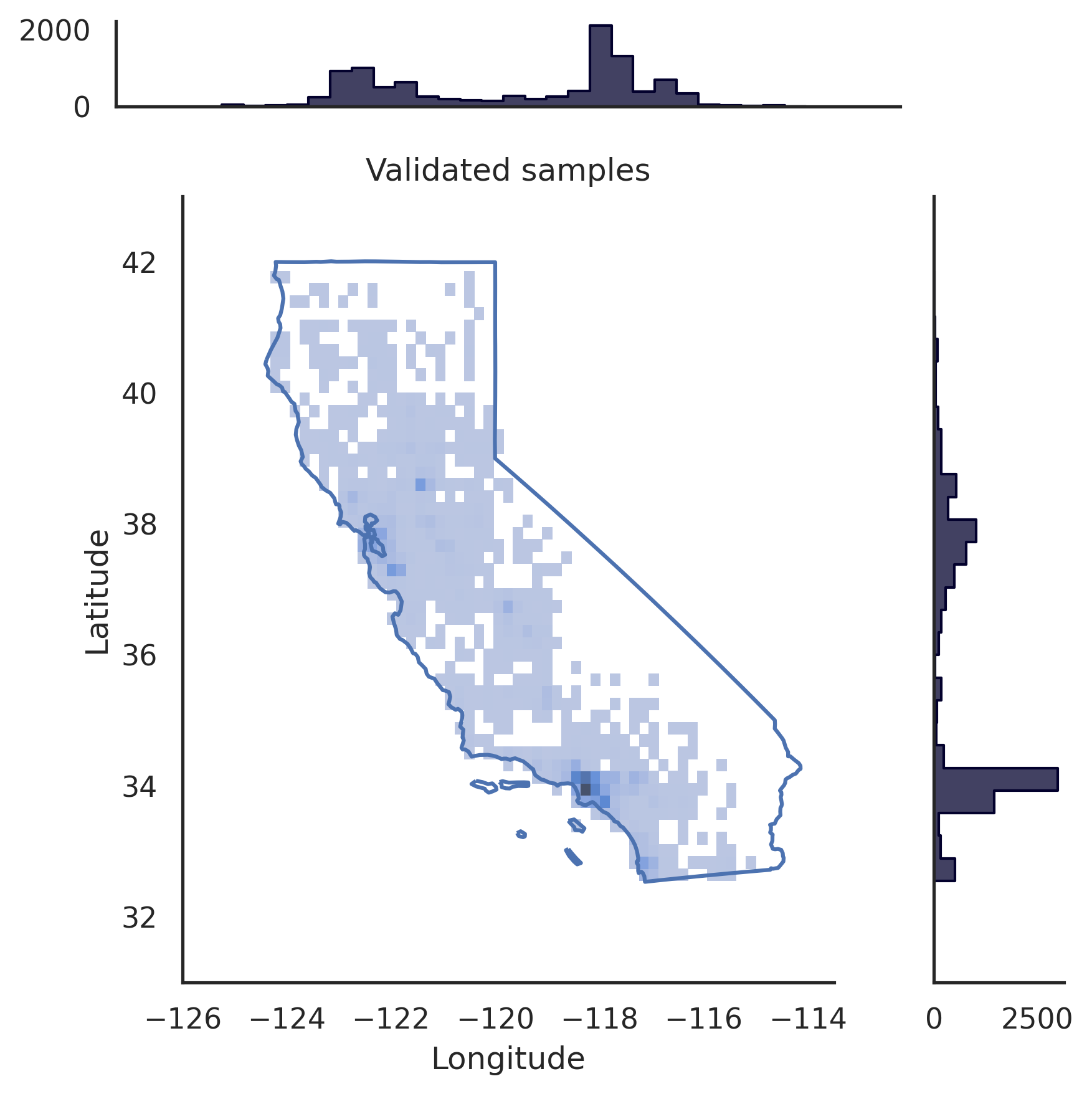
# !pip install geopandas &> /dev/null# !pip install realtabformer &> /dev/null# !git clone https://github.com/joncutrer/geopandas-tutorial.git &> /dev/nullimport geopandasimport seaborn as snsimport matplotlib.pyplot as pltfrom realtabformer importer REaLTabFormerfrom realtabformer importer rtf_validators as rtf_valfrom shapely.geometry import Polygon, LineString, Point, MultiPolygonfrom sklearn.datasets import fetch_california_housingdef plot_sf(data, samples, title=Aucun):xlims = (-126, -113.5)ylims = (31, 43)bins = (50, 50 )dd = échantillons.copie()pp = jj.loc[jj["Longitude"].between(data["Longitude"].min(), data["Longitude"].max()) &dd["Latitude"].between(data["Latitude"] .min(), données["Latitude"].max())
]g = sns.JointGrid(data=pp, x="Longitude", y="Latitude", marginal_ticks=True)g.plot_joint(sns.histplot,bins=bins,
)states[states['NAME'] == 'Californie'].boundary.plot(ax=g.ax_joint)g.ax_joint.set_xlim(*xlims)g.ax_joint.set_ylim(*ylims)g.plot_marginals(sns. histplot, element="step", color="#03012d")si title:g.ax_joint.set_title(title)plt.tight_layout()# Obtenir les fichiers géographiquesstates = geopandas.read_file('geopandas-tutorial/data/usa-states-census-2014.shp')states = states.to_crs("EPSG :4326") # Projection GPS# Obtenez le jeu de données sur le logement en Californiedata = fetch_california_housing(as_frame=True).frame# Nous créons un modèle avec de petites époques pour la démo, la valeur par défaut est 200.rtf_model = REaLTabFormer(model_type="tabular",batch_size=64,epochs=10,gradient_accumulation_steps=4,logging_steps=100) # Adaptez le modèle spécifié. Nous réduisons également le num_bootstrap, la valeur par défaut est 500.rtf_model.fit(data, num_bootstrap=10)# Enregistrez le modèle formértf_model.save("rtf_model/")# Échantillon de données brutes sans validatorsamples_raw = rtf_model.sample(n_samples=10240, gen_batch= 512)# Exemples de données avec le validateur géographiqueobs_validator = rtf_val.ObservationValidator()obs_validator.add_validator("geo_validator",rtf_val.GeoValidator(MultiPolygon(states[states['NAME'] == 'California'].geometry[0])),
("Longitude", "Latitude")
)samples_validated = rtf_model.sample(n_samples=10240, gen_batch=512,validator=obs_validator,
)# Visualisez les échantillonsplot_sf(data, samples_raw, title="Échantillons bruts")plot_sf(data, samples_validated, title="Échantillons validés")Veuillez citer notre travail si vous utilisez le REaLTabFormer dans vos projets ou recherches.
@article{solatorio2023realtabformer, title={REaLTabFormer : Générer des données relationnelles et tabulaires réalistes à l'aide de transformateurs}, author={Solatorio, Aivin V. et Dupriez, Olivier}, journal={arXiv preprint arXiv:2302.02041}, year={2023}}Nous remercions le Centre de données conjoint Banque mondiale-HCR sur les déplacements forcés (JDC) pour le financement du projet « Améliorer l'accès responsable aux microdonnées pour améliorer les politiques et la réponse dans les situations de déplacement forcé » (KP-P174174-GINP-TF0B5124). Une partie du fonds a servi à soutenir le développement du cadre REaLTabFormer qui a été utilisé pour générer la population synthétique pour la recherche sur le risque de divulgation et l'effet mosaïque.
Nous envoyons également ? au HuggingFace ? pour tous les logiciels open source qu'ils publient. Et à tous les projets open source, merci !


