safe rlhf
1.0.0
Beaver est un framework RLHF open source hautement modulaire développé par l'équipe PKU-Alignment de l'Université de Pékin. Il vise à fournir des données de formation et un pipeline de code reproductible pour la recherche d'alignement, en particulier la recherche LLM d'alignement contraint via les méthodes Safe RLHF.
Les principales caractéristiques de Beaver sont :
2024/06/13 : Nous sommes heureux d'annoncer l'open source de notre ensemble de données PKU-SafeRLHF version 1.0. Cette version progresse par rapport à la version bêta initiale en incorporant des annotations conjointes humain-IA, en élargissant la portée des catégories de dommages et en introduisant des étiquettes détaillées de niveau de gravité. Pour plus de détails et un accès, veuillez visiter notre page d'ensemble de données sur ? Visage câlin : PKU-Alignement/PKU-SafeRLHF.2024/01/16 : Notre méthode Safe RLHF a été acceptée par ICLR 2024 Spotlight.2023/10/19 : Nous avons publié notre article Safe RLHF sur arXiv, détaillant notre nouvel algorithme d'alignement sécurisé et sa mise en œuvre.2023/07/10 : Nous sommes ravis d'annoncer l'open source des modèles Beaver-7B v1 / v2 / v3 comme première étape de la série de formations Safe RLHF, complétée par les modèles de récompense correspondants v1 / v2 / v3 / unifiés. et modèles de coûts v1/v2/v3/points de contrôle unifiés sur ? Visage câlin.2023/07/10 : Nous étendons l'ensemble de données open source sur les préférences de sécurité, PKU-Alignment/PKU-SafeRLHF , qui contient désormais plus de 300 000 exemples. (Voir également la section PKU-SafeRLHF-Dataset)2023/07/05 : Nous avons amélioré notre prise en charge des modèles de pré-formation chinois et incorporé des ensembles de données chinois open source supplémentaires. (Voir également les sections Prise en charge chinoise (中文支持) et Ensembles de données personnalisés (自定义数据集))2023/05/15 : Première version du pipeline Safe RLHF, résultats de l'évaluation et code de formation.Apprentissage par renforcement à partir du feedback humain : maximisation des récompenses via l'apprentissage des préférences
Apprentissage par renforcement sécurisé à partir de la rétroaction humaine : maximisation contrainte des récompenses via l'apprentissage des préférences
où
Le but ultime est de trouver un modèle
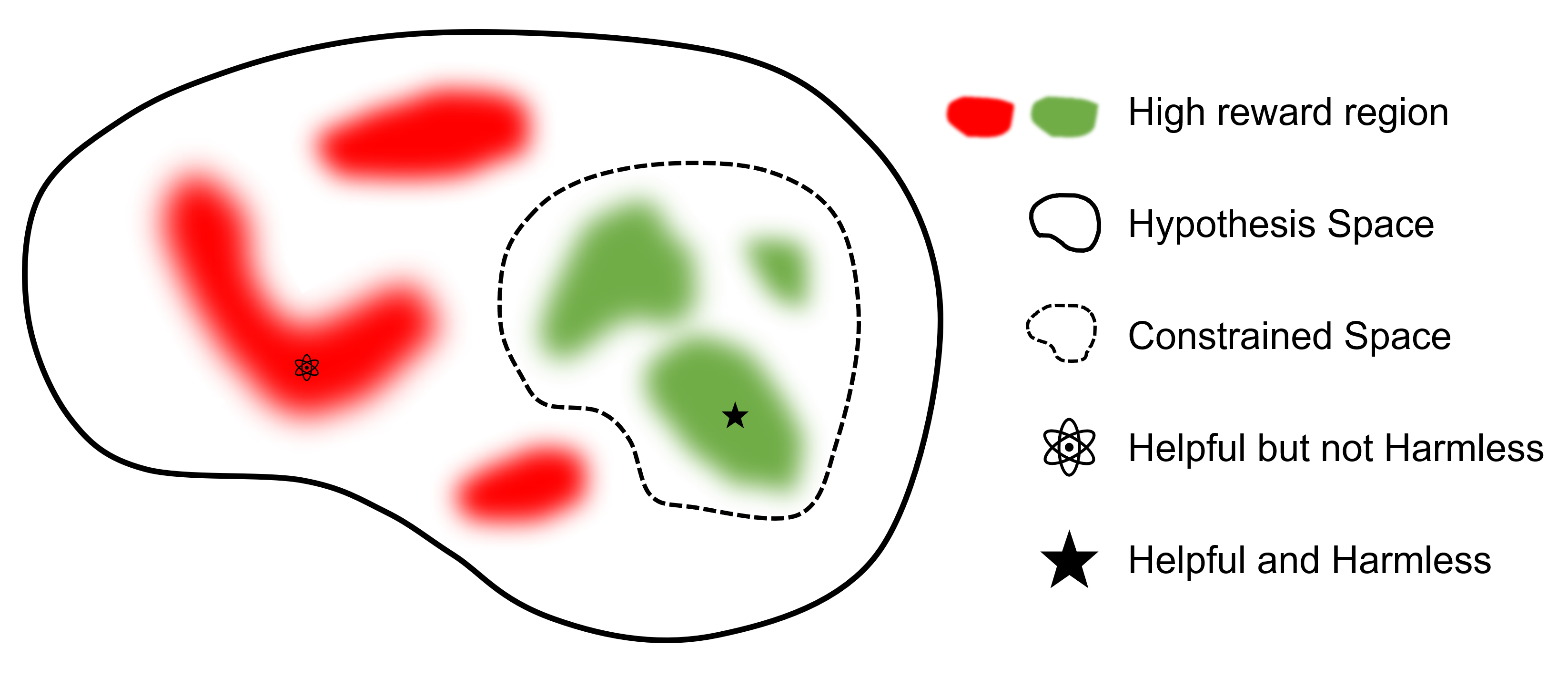
Comparez avec d'autres frameworks prenant en charge le RLHF, safe-rlhf est le premier framework à prendre en charge toutes les étapes, de SFT à RLHF et à l'évaluation. De plus, safe-rlhf est le premier cadre qui prend en compte les préférences en matière de sécurité lors de l'étape RLHF. Il offre une garantie plus théorique pour la recherche contrainte de paramètres dans l’espace politique.
| SFT | Formation de préférence modèle 1 | RLHF | RLHF sécuritaire | Perte PTX | Évaluation | Back-end | |
|---|---|---|---|---|---|---|---|
| Castor (Coffre-fort-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | Vitesse profonde |
| trlX | ✔️ | 2 | ✔️ | Accélérer / NeMo | |||
| Chat DeepSpeed | ✔️ | ✔️ | ✔️ | ✔️ | Vitesse profonde | ||
| Colossal-IA | ✔️ | ✔️ | ✔️ | ✔️ | ColossalAI | ||
| AlpagaFerme | 3 | ✔️ | ✔️ | ✔️ | Accélérer |
L'ensemble de données PKU-SafeRLHF est un ensemble de données étiquetées par l'homme contenant à la fois des préférences en matière de performances et de sécurité. Il comprend des contraintes dans plus de dix dimensions, telles que les insultes, l'immoralité, la criminalité, les dommages émotionnels et la vie privée, entre autres. Ces contraintes sont conçues pour un alignement fin des valeurs dans la technologie RLHF.
Pour faciliter le réglage précis sur plusieurs tours, nous publierons les poids des paramètres initiaux, les ensembles de données requis et les paramètres d'entraînement pour chaque tour. Cela garantit la reproductibilité dans la recherche scientifique et universitaire. L'ensemble de données sera publié progressivement grâce à des mises à jour progressives.
L'ensemble de données est disponible sur Hugging Face : PKU-Alignment/PKU-SafeRLHF.
PKU-SafeRLHF-10K est un sous-ensemble de PKU-SafeRLHF qui contient la première série de données de formation Safe RLHF avec 10 000 instances, y compris les préférences de sécurité. Vous pouvez le trouver sur Hugging Face : PKU-Alignment/PKU-SafeRLHF-10K.
Nous publierons progressivement les ensembles de données complets Safe-RLHF, qui comprennent 1 million de paires étiquetées par l'homme pour des préférences à la fois utiles et inoffensives.
Beaver est un grand modèle de langage basé sur LLaMA, formé à l'aide de safe-rlhf . Il est développé sur la base du modèle Alpaca, en collectant des données sur les préférences humaines liées à l'utilité et à l'innocuité et en utilisant la technique Safe RLHF pour la formation. Tout en conservant les performances utiles de l'Alpaga, le Castor améliore considérablement son innocuité.
Les castors sont connus comme les « ingénieurs naturels des barrages », car ils savent utiliser des branches, des arbustes, des roches et de la terre pour construire des barrages et de petites maisons en bois, créant ainsi des environnements de zones humides propices à l'habitat d'autres créatures, ce qui en fait un élément indispensable de l'écosystème. . Pour garantir la sécurité et la fiabilité des grands modèles linguistiques (LLM) tout en prenant en compte un large éventail de valeurs dans différentes populations, l'équipe de l'Université de Pékin a nommé son modèle open source « Beaver » et vise à construire un barrage pour les LLM grâce à la valeur contrainte. Technologie d'alignement (CVA). Cette technologie permet un étiquetage fin des informations et, combinée à des méthodes d'apprentissage par renforcement sécurisées, réduit considérablement les biais et la discrimination du modèle, améliorant ainsi la sécurité du modèle. Analogue au rôle des castors dans l'écosystème, le modèle Beaver fournira un soutien crucial au développement de grands modèles de langage et apportera une contribution positive au développement durable de la technologie de l'intelligence artificielle.
Suivant la méthodologie d'évaluation du modèle Vicuna, nous avons utilisé GPT-4 pour évaluer Beaver. Les résultats indiquent que, par rapport à l'alpaga, le castor présente des améliorations significatives dans plusieurs dimensions liées à la sécurité.
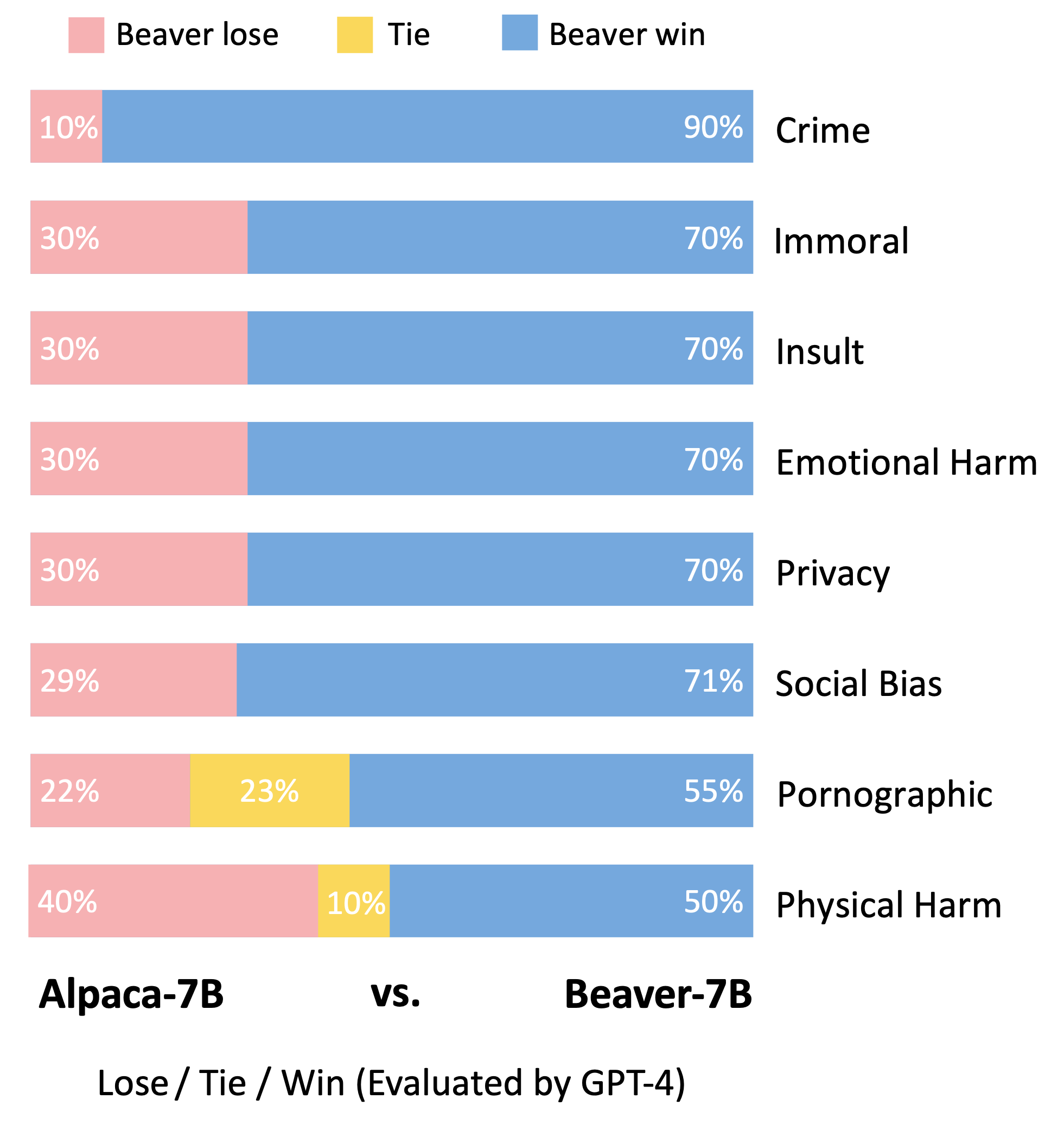
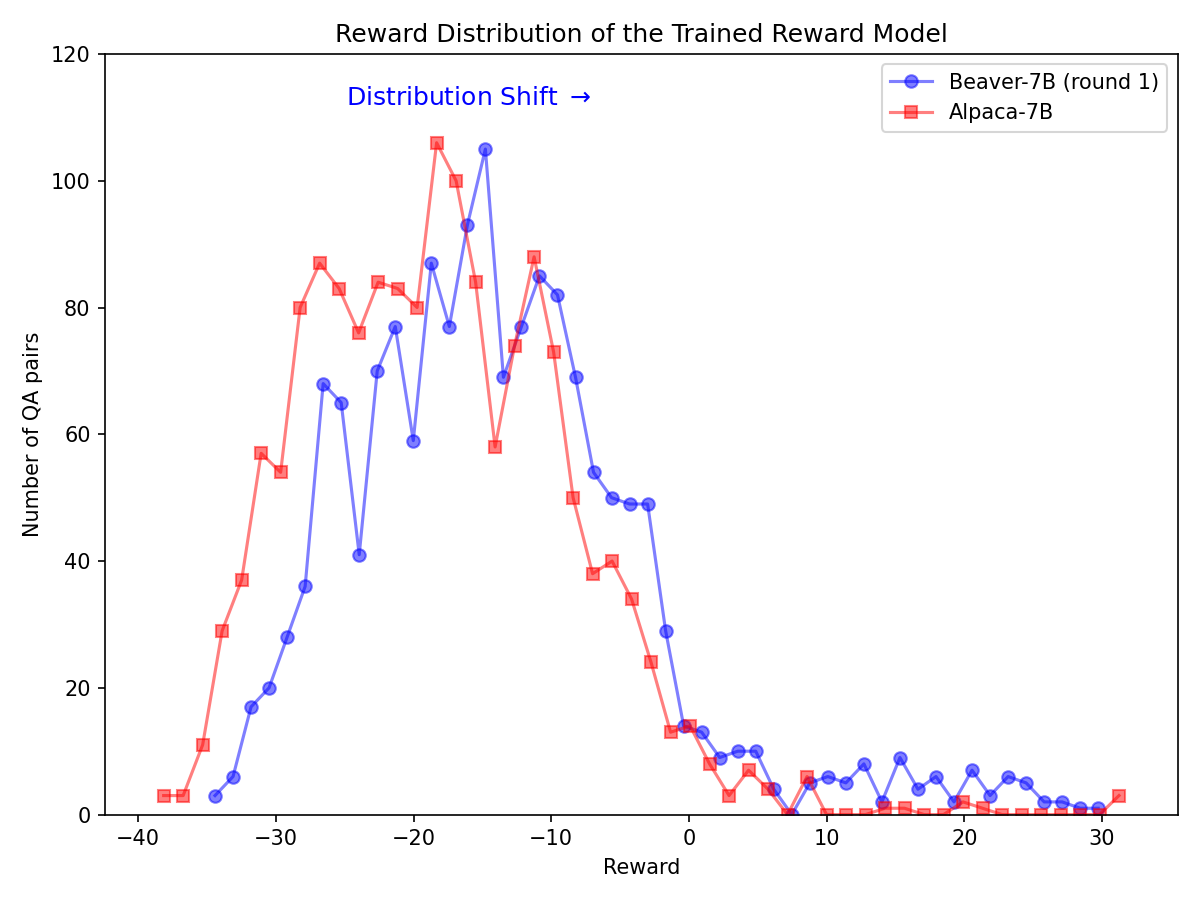
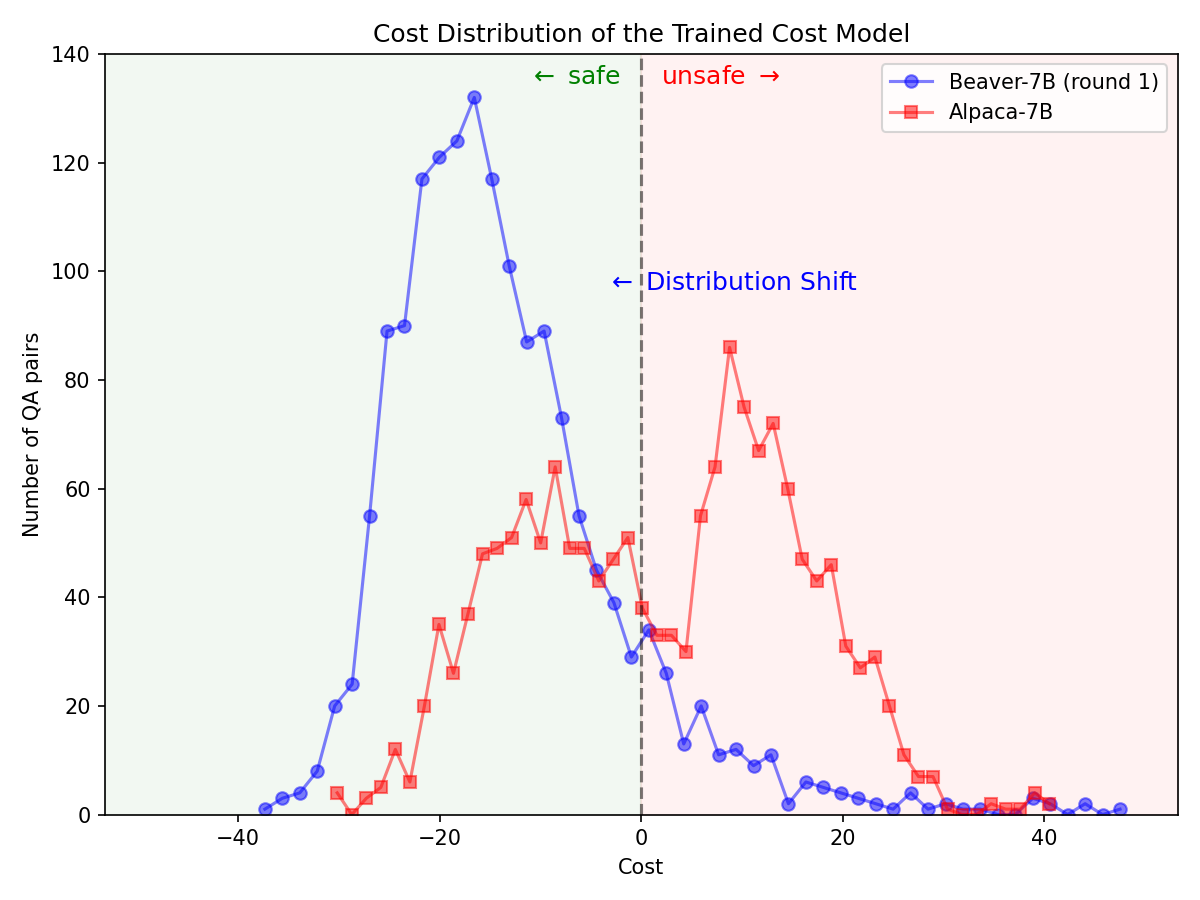
Changement de distribution important pour les préférences de sécurité après l'utilisation du pipeline Safe RLHF sur le modèle Alpaca-7B.
 |  |
Clonez le code source depuis GitHub :
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner : configurez un environnement conda en utilisant conda / mamba :
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`Cela configurera automatiquement toutes les dépendances.
Containerized Runner : outre l'utilisation de la machine native avec l'isolation conda, vous pouvez également utiliser des images Docker pour configurer l'environnement.
Tout d'abord, veuillez suivre NVIDIA Container Toolkit : Guide d'installation et NVIDIA Docker : Guide d'installation pour configurer nvidia-docker . Ensuite, vous pouvez exécuter :
make docker-run Cette commande créera et démarrera un conteneur Docker installé avec les dépendances appropriées. Le chemin de l'hôte / sera mappé à /host et le répertoire de travail actuel sera mappé à /workspace à l'intérieur du conteneur.
safe-rlhf prend en charge un pipeline complet allant du réglage fin supervisé (SFT) à la formation sur les modèles de préférences en passant par la formation à l'alignement RLHF.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereou
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftREMARQUE : Vous devrez peut-être mettre à jour certains paramètres du script en fonction de la configuration de votre machine, tels que le nombre de GPU pour l'entraînement, la taille du lot d'entraînement, etc.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagUn exemple de commandes pour exécuter l'ensemble du pipeline avec LLaMA-7B :
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagTous les processus de formation répertoriés ci-dessus sont testés avec LLaMA-7B sur un serveur cloud doté de 8 GPU NVIDIA A800-80GB.
Les utilisateurs qui ne disposent pas de suffisamment de ressources de mémoire GPU peuvent activer DeepSpeed ZeRO-Offload pour atténuer l'utilisation maximale de la mémoire GPU.
Tous les scripts de formation peuvent être transmis avec une option supplémentaire --offload (par défaut sur none , c'est-à-dire désactiver ZeRO-Offload) pour décharger les tenseurs (paramètres et/ou états de l'optimiseur) sur le processeur. Par exemple:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`Pour les paramètres multi-nœuds, les utilisateurs peuvent se référer à la documentation DeepSpeed : Configuration des ressources (multi-nœuds) pour plus de détails. Voici un exemple pour démarrer le processus de formation sur 4 nœuds (chacun dispose de 8 GPU) :
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
Lancez ensuite les scripts de formation avec :
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf fournit une abstraction pour créer des ensembles de données pour toutes les étapes de réglage fin supervisé, de formation du modèle de préférence et de formation RL.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""Voici un exemple pour implémenter un ensemble de données personnalisé (voir safe_rlhf/datasets/raw pour plus d'exemples) :
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()Ensuite, vous pouvez transmettre cet ensemble de données aux scripts de formation comme :
python3 train.py --datasets my-dataset-name Vous pouvez également transmettre plusieurs ensembles de données avec éventuellement des proportions d'ensemble de données supplémentaires (séparées par deux points : ). Par exemple:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5Cela utilisera une répartition aléatoire de 75 % de l'ensemble de données Stanford Alpaca et de 50 % de votre ensemble de données personnalisé.
De plus, l'argument de l'ensemble de données peut également être suivi d'un chemin local (séparé par deux points : ) si vous avez déjà cloné le référentiel de l'ensemble de données depuis Hugging Face.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryREMARQUE : La classe d'ensemble de données doit être importée avant que le script de formation ne commence à analyser les arguments de ligne de commande.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
Le pipeline Safe-RLHF prend en charge non seulement la famille de modèles LLaMA, mais également d'autres modèles pré-entraînés tels que Baichuan, InternLM, etc. qui offrent une meilleure prise en charge du chinois. Il vous suffit de mettre à jour le chemin d'accès au modèle pré-entraîné dans le code de formation et d'inférence.
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型,它也支持其他一些对中文支持更好的预训练模型,例如 Baichuan你只需要在训练和推理的代码中更新预训练模型的路径即可。
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft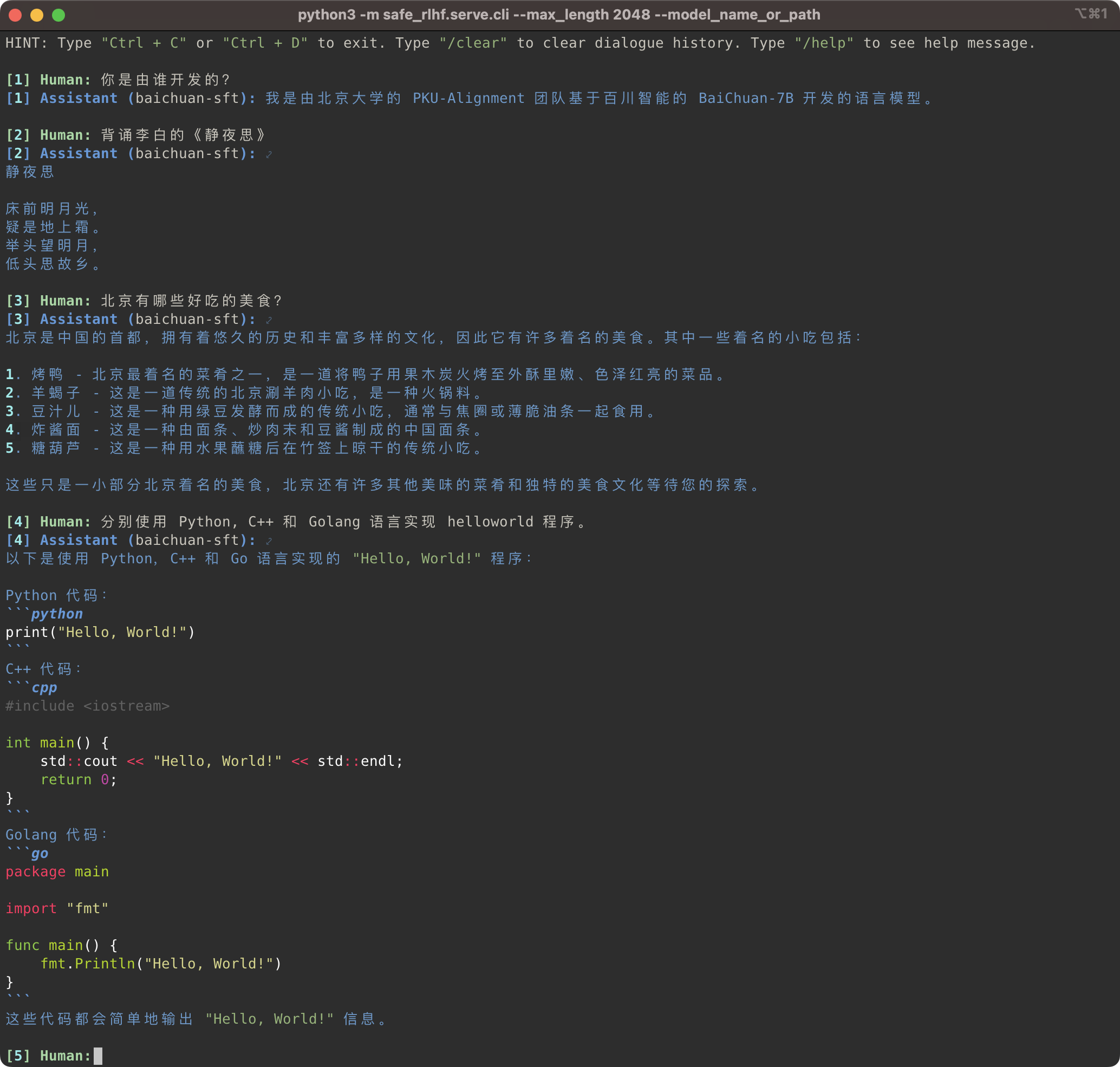
Entre-temps, nous avons ajouté la prise en charge des ensembles de données chinois tels que les séries Firefly et MOSS à nos ensembles de données brutes. Il vous suffit de modifier le chemin de l'ensemble de données dans le code de formation pour utiliser l'ensemble de données correspondant afin d'affiner le modèle de pré-entraînement chinois :
Il s'agit d'ensembles de données brutes et de Firefly et MOSS.系列等。在训练代码中更改数据集路径,你就可以使用相应的数据集来微调中文预训练模型:
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly Pour obtenir des instructions sur la façon d'ajouter des ensembles de données personnalisés, veuillez vous référer à la section Ensembles de données personnalisés.
Ensembles de données personnalisés (自定义数据集)。
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagSi vous trouvez Safe-RLHF utile ou utilisez Safe-RLHF (modèle, code, ensemble de données, etc.) dans votre recherche, veuillez envisager de citer les travaux suivants dans vos publications.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}Tous les étudiants ci-dessous ont contribué à parts égales et l'ordre est déterminé par ordre alphabétique :
Le tout conseillé par Yizhou Wang et Yaodong Yang. Remerciements : Nous apprécions Mme Yi Qu pour la conception du logo Beaver.
Ce référentiel bénéficie de LLaMA, Stanford Alpaca, DeepSpeed et DeepSpeed-Chat. Merci pour leurs merveilleux travaux et leurs efforts pour démocratiser la recherche LLM. Safe-RLHF et ses actifs associés sont construits et open source avec amour ?❤️.
Ce travail est soutenu et financé par l'Université de Pékin.
 |  |
Safe-RLHF est publié sous licence Apache 2.0.


