spelltest
v0.0.4
? Si vous trouvez ce projet utile, pensez à lui donner une étoile ! Votre soutien me motive à continuer de l'améliorer ! ?
Les applications actuelles basées sur l'IA dépendent largement des grands modèles linguistiques (LLM) tels que GPT-4 pour fournir des solutions innovantes. Cependant, garantir qu’ils fournissent des réponses pertinentes et précises dans chaque situation constitue un défi. Spelltest résout ce problème en simulant les réponses LLM à l'aide de personnalités d'utilisateurs synthétiques et d'une technique d'évaluation pour évaluer automatiquement ces réponses (mais nécessite toujours une supervision humaine).
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

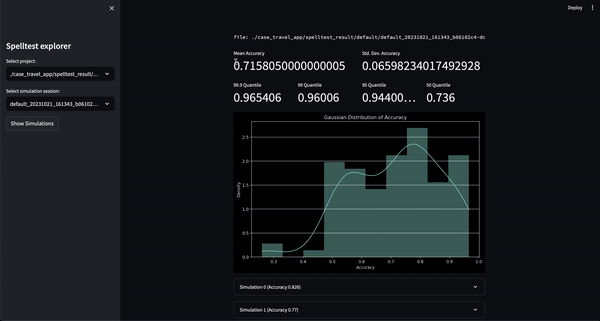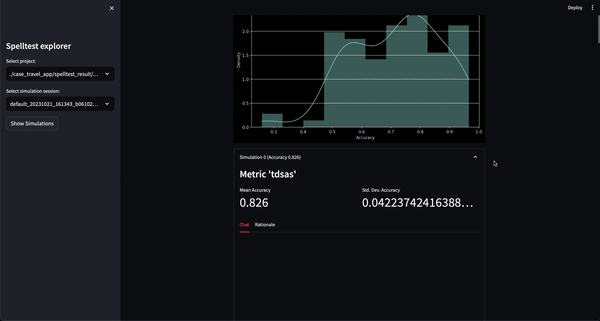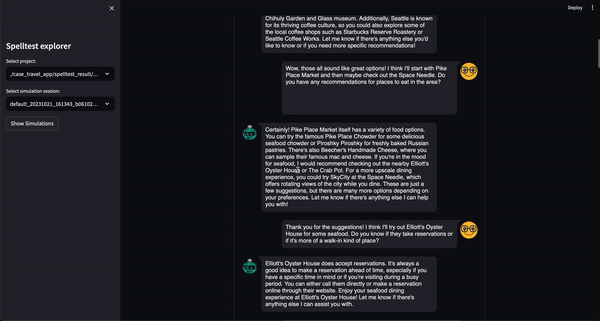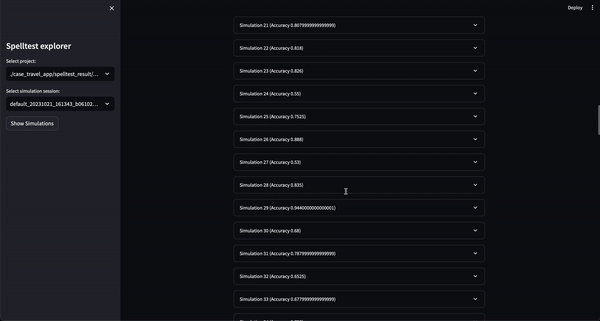
Vous pouvez désormais essayer ce projet dans un environnement interactif basé sur le Web via Google Colab ! Aucune installation n'est requise.
Cliquez simplement sur le badge ci-dessus pour commencer !
Qualité assurée : simulez les interactions des utilisateurs pour des réponses optimales.
Efficacité et économies : économisez sur les coûts de tests manuels.
Intégration fluide du flux de travail : s'intègre parfaitement à votre processus de développement.
Veuillez noter qu'il s'agit d'une toute première version de Spelltest. En tant que tel, il n’a pas encore été testé de manière approfondie dans divers environnements et cas d’utilisation. En décidant d'utiliser cette version, vous acceptez que vous utilisez le framework Spelltest à vos propres risques. Nous encourageons fortement les utilisateurs à signaler tout problème ou bug qu'ils rencontrent pour aider à l'amélioration du projet.
Concernant les coûts opérationnels, il est important de noter que l'exécution de simulations avec Spelltest entraîne des frais basés sur l'utilisation de l'API OpenAI. Il n’y a pas d’estimation de coûts ni de limite budgétaire pour le moment. Pour le contexte, l'exécution d'un lot de 100 simulations peut coûter environ 0,7 à 1,8 $ (gpt-3,5-turbo), en fonction de plusieurs facteurs, notamment le LLM spécifique et la complexité des simulations.
Compte tenu de ces coûts, nous vous recommandons fortement de commencer par un plus petit nombre de simulations pour à la fois réduire vos coûts initiaux et vous aider à mieux estimer les dépenses futures. À mesure que vous vous familiariserez avec le cadre et ses implications financières, vous pourrez ajuster le nombre de simulations en fonction de votre budget et de vos besoins.
N'oubliez pas que l'objectif de Spelltest est de garantir des réponses de haute qualité de la part des LLM tout en restant aussi rentable que possible dans votre processus de développement et de test d'IA.

Spelltest adopte une approche distinctive en matière d’assurance qualité. En utilisant des personnalités d'utilisateurs synthétiques, nous simulons non seulement les interactions, mais capturons également les attentes uniques des utilisateurs, fournissant ainsi un environnement de test riche en contexte. Cette profondeur du contexte nous permet d'évaluer la qualité des réponses LLM d'une manière qui reflète fidèlement les applications du monde réel.
Le résultat ? Un score de qualité allant de 0,0 à 1,0, faisant office de répétition générale complète avant que votre application ne rencontre ses vrais utilisateurs. Que ce soit en mode chat ou en mode complétion, Spelltest garantit que les réponses LLM correspondent étroitement aux attentes des utilisateurs, améliorant ainsi la satisfaction globale des utilisateurs.
Installez le framework en utilisant pip :
pip install spelltest Le .spellforge.yaml est au cœur de Spelltest, contenant des profils utilisateur synthétiques, des métriques, des invites et des simulations. Vous trouverez ci-dessous un aperçu de sa structure :
Les utilisateurs synthétiques imitent les utilisateurs du monde réel, chacun avec un parcours, des attentes et une compréhension uniques de l'application. La configuration pour les utilisateurs synthétiques comprend :
Sous-invites : ce sont des éléments descriptifs fournissant un contexte au profil utilisateur. Ils comprennent :
description : Une brève présentation de l'utilisateur synthétique.expectation : ce que l'utilisateur attend de l'interaction.user_knowledge_about_app : Niveau de familiarité avec l'application.Chaque utilisateur synthétique dispose également d'un :
name : L’identifiant de l’utilisateur synthétique.llm_name : Les modèles LLM à utiliser (testés sur les modèles OpenAI uniquement).temperature : ...Exemple de configuration utilisateur synthétique :
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... Des mesures sont utilisées pour évaluer et noter les réponses du LLM. Chaque métrique contient une sous- description d'invite qui fournit un contexte sur ce que la métrique évalue.
Exemple de configuration de métrique simple :
...
metrics :
accuracy :
description : " Accuracy "
...Exemple de configuration de métriques complexes/personnalisées :
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... Les invites sont des questions ou des tâches posées par l'application. Ceux-ci sont utilisés dans des simulations pour tester la capacité du LLM à générer des réponses appropriées. Chaque invite est définie avec une description et le texte ou la tâche prompt réelle.
...
prompts :
book_flight :
file : book-flight-prompt.txt
... Les simulations précisent le scénario de test. Les éléments clés incluent prompt , users , llm_name , temperature , size , chat_mode et quality_threshold .
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
La configuration complète avec les fichiers d'invite est ici.
Coûts OpenAI : L'utilisation de ce framework peut conduire à un nombre important de requêtes vers OpenAI, en particulier lors de l'exécution de simulations approfondies. Cela peut entraîner des coûts importants sur votre compte OpenAI. Assurez-vous de respecter votre budget OpenAI et de comprendre le modèle de tarification. Je n'assume aucune responsabilité pour les dépenses engagées.
Version anticipée : Cette version de Spelltest en est à ses débuts et n'a aucune garantie de stabilité. Veuillez l'utiliser avec prudence et n'hésitez pas à nous faire part de vos commentaires ou à signaler des problèmes.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlVérifiez les résultats de la simulation.
spelltest --analyzeL'intégration de Spelltest dans votre pipeline de versions améliore votre stratégie de déploiement en intégrant des tests cohérents et automatisés. Cette étape cruciale garantit que vos applications basées sur LLM maintiennent un haut niveau de qualité en simulant et en évaluant systématiquement les interactions des utilisateurs avant toute version. Cette pratique peut permettre de gagner beaucoup de temps, de réduire les erreurs manuelles et de fournir des informations clés sur la manière dont les modifications ou les nouvelles fonctionnalités affecteront l'expérience utilisateur.
Ce guide vous guidera tout au long du processus de mise en place et d'automatisation de l'intégration continue de vos projets.
Avant de commencer, assurez-vous que les conditions préalables suivantes sont remplies :
Un référentiel GitHub contenant votre projet.
Accès à SpellForge avec une clé API. Si vous n'en avez pas, vous pouvez l'obtenir sur le site SpellForge.
Une clé API OpenAI pour utiliser les services OpenAI. Si vous n'en avez pas, vous pouvez l'obtenir sur le site OpenAI.
.spellforge.yaml Créez un fichier .spellforge.yaml dans le répertoire racine de votre projet. Ce fichier contiendra les instructions pour Spelltest.
Créez un fichier de workflow GitHub Actions, par exemple .github/workflows/.spelltest.yaml, pour automatiser les tests SpellForge. Insérez le code suivant dans ce fichier :
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHCe workflow est déclenché à chaque poussée vers la branche principale et exécutera vos tests SpellForge.
Accédez à votre référentiel GitHub et accédez à l'onglet « Paramètres ».
Sous « Secrets », ajoutez deux nouveaux secrets :
OPENAI_API_KEY : définissez ce secret sur votre clé API OpenAI.
Ajoutez une variable d'environnement GitHub :
SPELLTEST_CONFIG_PATH : définissez cette variable sur le chemin complet de votre fichier .spellforge.yaml dans votre référentiel.
Ceux-ci simulent des interactions d’utilisateurs réels avec des caractéristiques et des attentes spécifiques.
Contexte de l'utilisateur ( champ description dans .spellforge.yaml ) : une sous-invite qui fournit un aperçu de qui est cet utilisateur synthétique et des problèmes qu'il souhaite résoudre à l'aide de l'application, par exemple, un voyageur gérant son emploi du temps.
Attente de l'utilisateur (champ expectation ) : sous-invite qui définit ce que l'utilisateur synthétique anticipe comme une interaction ou une solution réussie grâce à l'utilisation de l'application.
Conscience de l'environnement (champ user_knowledge_about_app ) : une sous-invite qui garantit que l'utilisateur synthétique comprend le contexte de l'application, garantissant ainsi des scénarios de test réalistes.
Une sous-invite qui représente les normes ou critères utilisés pour évaluer et noter les réponses générées par le LLM dans les simulations. Les métriques peuvent aller de mesures générales à des métriques personnalisées plus spécifiques à une application.
Exemples de mesures générales :
Similarité sémantique : mesure dans quelle mesure la réponse fournie ressemble à une réponse attendue en termes de signification.
Toxicité : évalue la réponse pour tout langage ou contenu pouvant être considéré comme inapproprié ou nuisible.
Similarité structurelle : compare la structure et le format de la réponse générée à une norme prédéfinie ou à une sortie attendue.
Autres exemples de métriques personnalisées :
TPAS (Travel Plan Accuracy Score) : "Cette métrique mesure l'exactitude de la réponse générée en évaluant l'inclusion du résultat attendu et la qualité du plan de voyage proposé. TPAS est une valeur numérique comprise entre 0 et 100, 100 représentant un parfait correspond au résultat attendu et 0 indiquant un résultat non précis."
EES (Empathy Engagement Score) : "L'EES évalue la résonance empathique des réponses du LLM. En évaluant la compréhension, la validation et les éléments de soutien du message, il note le niveau d'empathie véhiculé. L'EES varie de 0 à 100, où 100 indique un réponse très empathique, tandis que 0 dénote un manque d'engagement empathique.
Améliorez votre application basée sur LLM avec Spelltest !


