DeveloperGPT
v0.7.5
DeveloperGPT est un outil de ligne de commande alimenté par LLM qui permet d'utiliser le langage naturel pour les commandes du terminal et la discussion dans le terminal. DeveloperGPT est alimenté par Google Gemini 1.5 Flash par défaut mais prend également en charge Google Gemini 1.0 Pro, OpenAI GPT-3.5 & GPT-4, Anthropic Claude 3 Haiku & Sonnet, les LLM ouverts (Zephyr, Gemma, Mistral) hébergés sur Hugging Face et quantifiés. Mistral-7B-Instruct s'exécutant hors ligne sur l'appareil.
Depuis juin 2024, DeveloperGPT est totalement gratuit lors de l'utilisation de Google Gemini 1.5 Pro (utilisé par défaut) ou de Google Gemini 1.0 Pro jusqu'à 15 requêtes par minute.
Basculez entre différents LLM à l'aide de l'indicateur --model : developergpt --model [llm_name] [cmd, chat]
| Modèle(s) | Source | Détails |
|---|---|---|
| Gemini Pro , Gemini Flash (par défaut) | Google Gemini 1.0 Pro, Gemini 1.5 Flash | Gratuit (jusqu'à 15 requêtes/min), clé API Google AI requise |
| GPT35, GPT4 | OpenAI | Paiement à l'utilisation, clé API OpenAI requise |
| Haïku, Sonnet | Anthropique (Claude 3) | Paiement à l'utilisation, clé API Anthropic requise |
| Zéphyr | Zephyr7B-Bêta | API gratuite et ouverte d'inférence LLM, Hugging Face |
| Gemma, Gemma-Base | Gemma-1.1-7B-Instruct, Gemma-Base | API gratuite et ouverte d'inférence LLM, Hugging Face |
| Mistral-Q6, Mistral-Q4 | GGUF Mistral-7B-Instruct quantifié | LLM gratuit, ouvert, HORS LIGNE, SUR APPAREIL |
| Mistral | Mistral-7B-Instruire | API gratuite et ouverte d'inférence LLM, Hugging Face |
mistral-q6 et mistral-q4 sont des LLM quantifiés GGUF Mistral-7B-Instruct exécutés localement sur l'appareil à l'aide de lama.cpp (modèles quantifiés Q6_K et Q4_K respectivement). Ces LLM peuvent fonctionner sur des machines sans GPU dédié – voir llama.cpp pour plus de détails.DeveloperGPT a 2 fonctionnalités principales.
Utilisation : developergpt cmd [your natural language command request]
# Example
$ developergpt cmd list all git commits that contain the word llm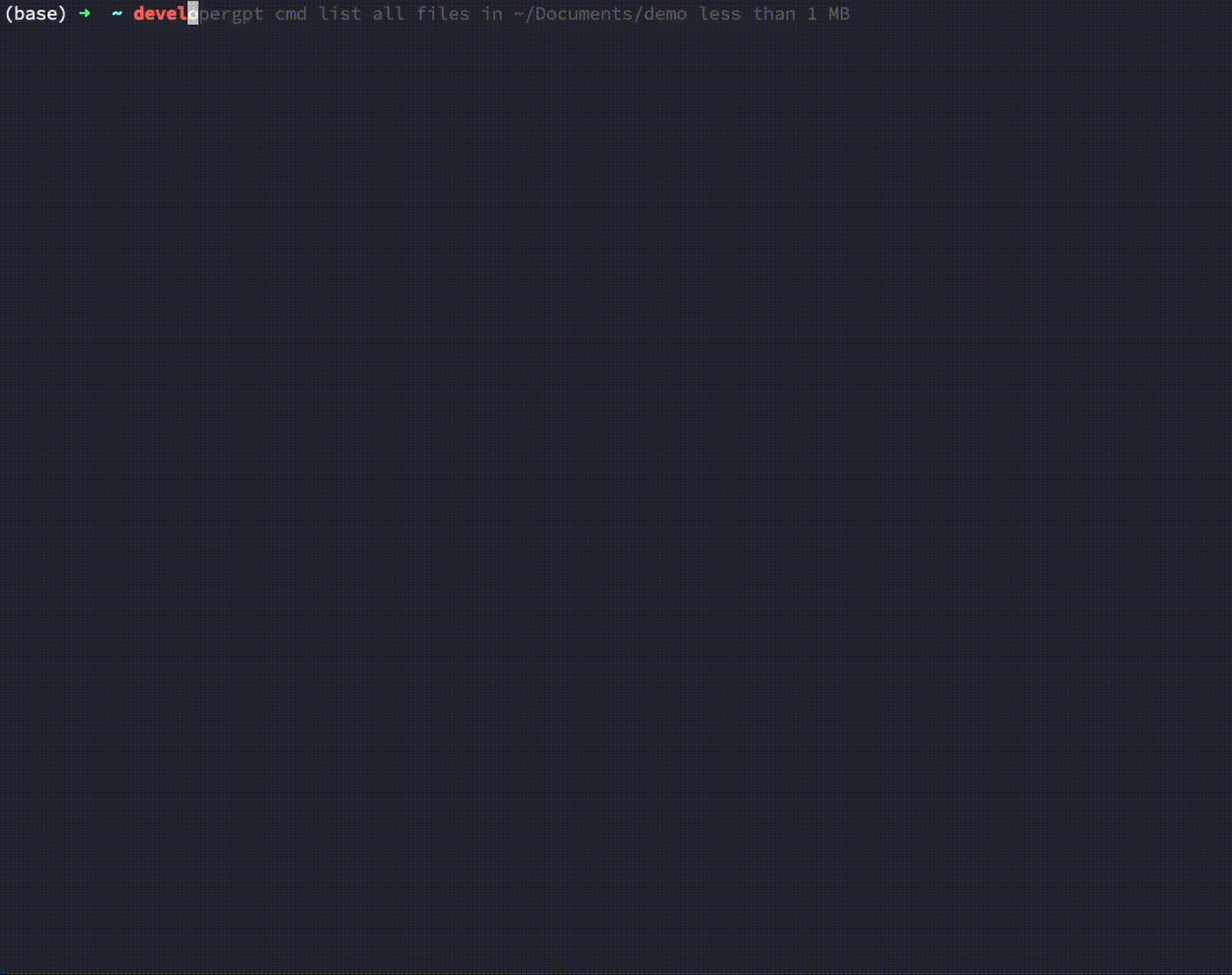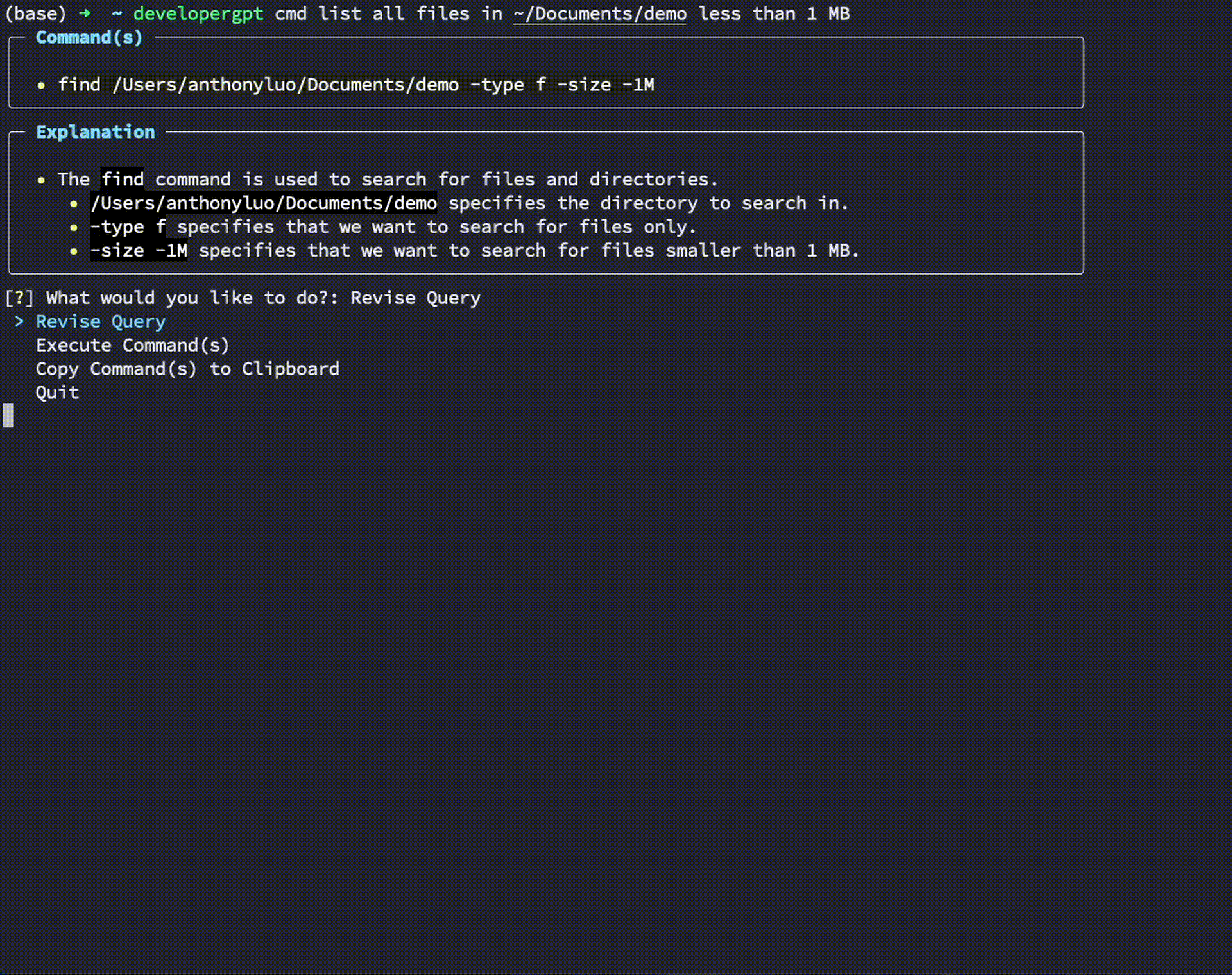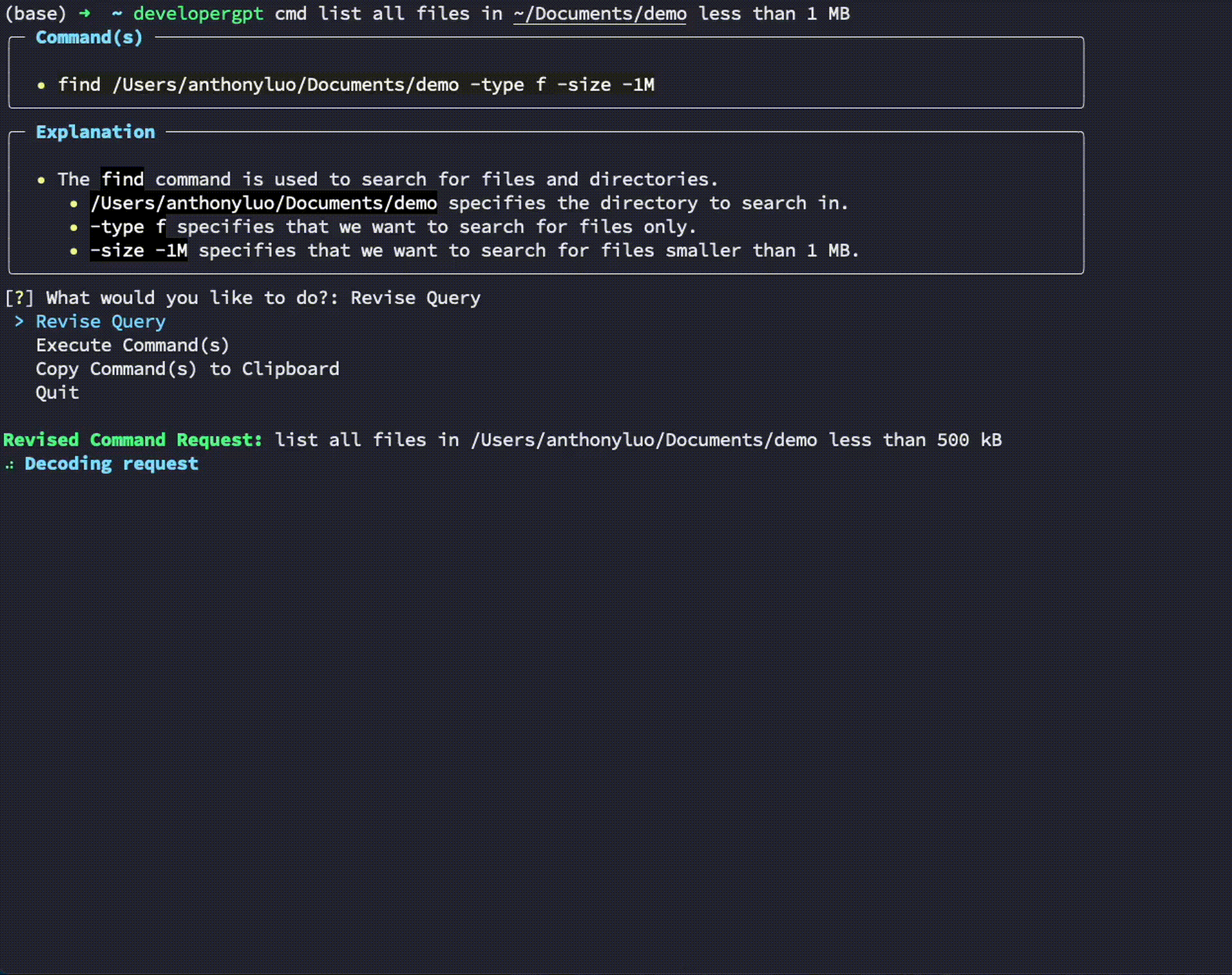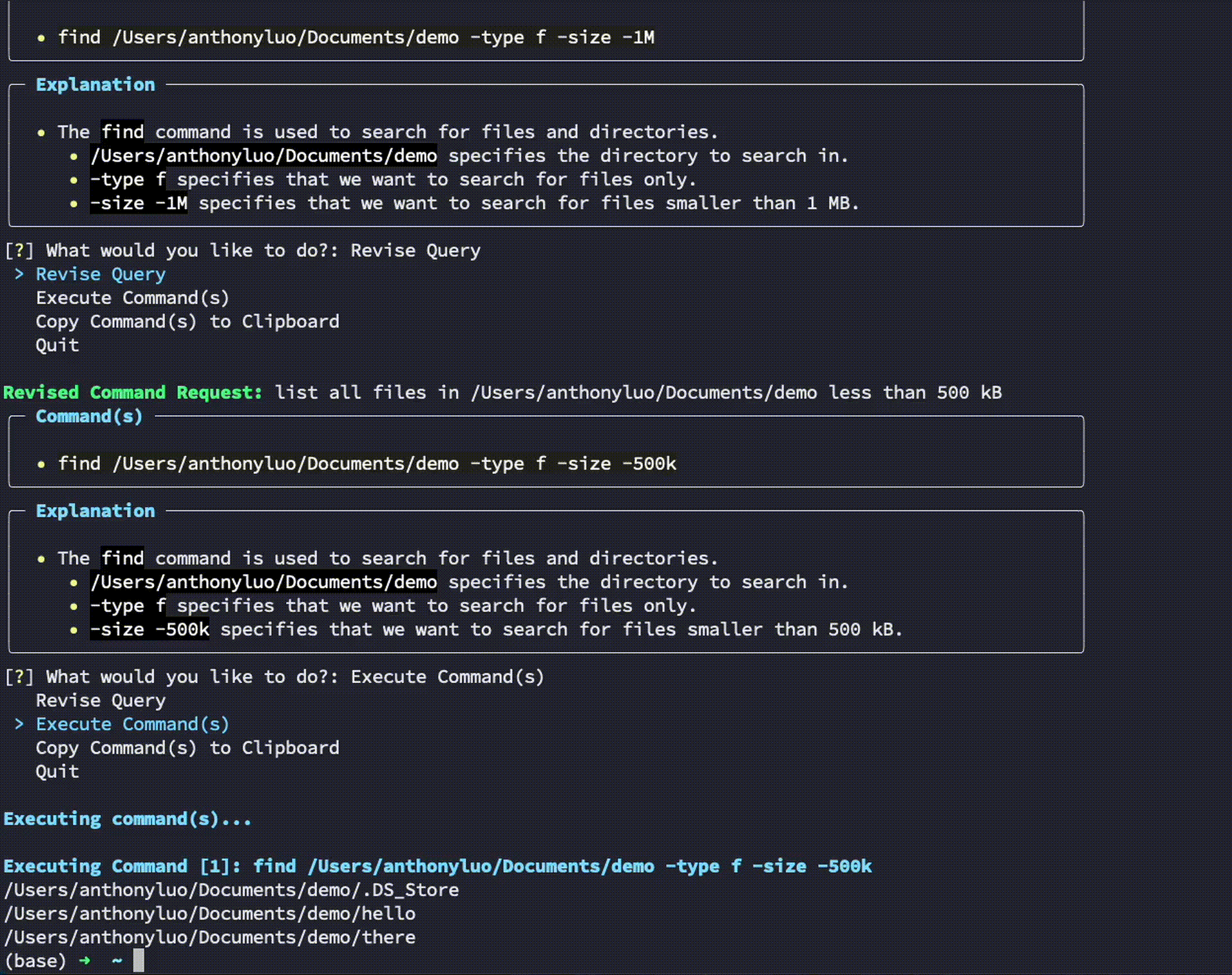
Utilisez developergpt cmd --fast pour obtenir des commandes plus rapidement sans aucune explication (~ 1,6 secondes avec --fast contre ~ 3,2 secondes avec Regular en moyenne). Les commandes fournies par DeveloperGPT en mode --fast peuvent être moins précises - voir DeveloperGPT Natural Language to Terminal Command Accuracy pour plus de détails.
# Fast Mode: Commands are given without explanation for faster response
$ developergpt cmd --fast [your natural language command request] Utilisez developergpt --model [model_name] cmd pour utiliser un LLM différent au lieu de Gemini Flash (utilisé par défaut).
# Example: Natural Language to Terminal Commands using the GPT-3.5 instead of Gemini Flash
$ developergpt --model gpt35 cmd [your natural language command request] Utilisation : developergpt chat
# Chat with DeveloperGPT using Gemini 1.5 Flash (default)
$ developergpt chat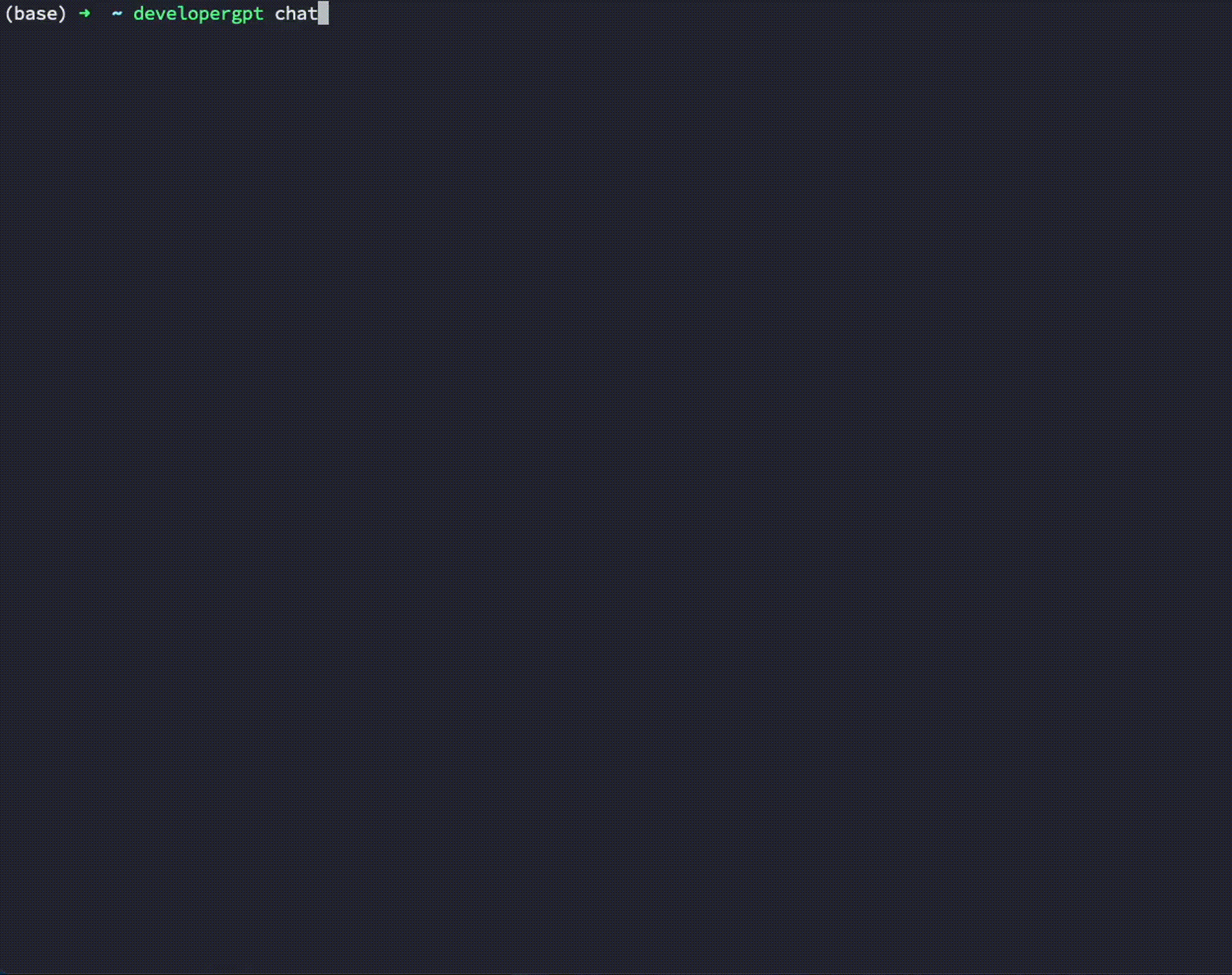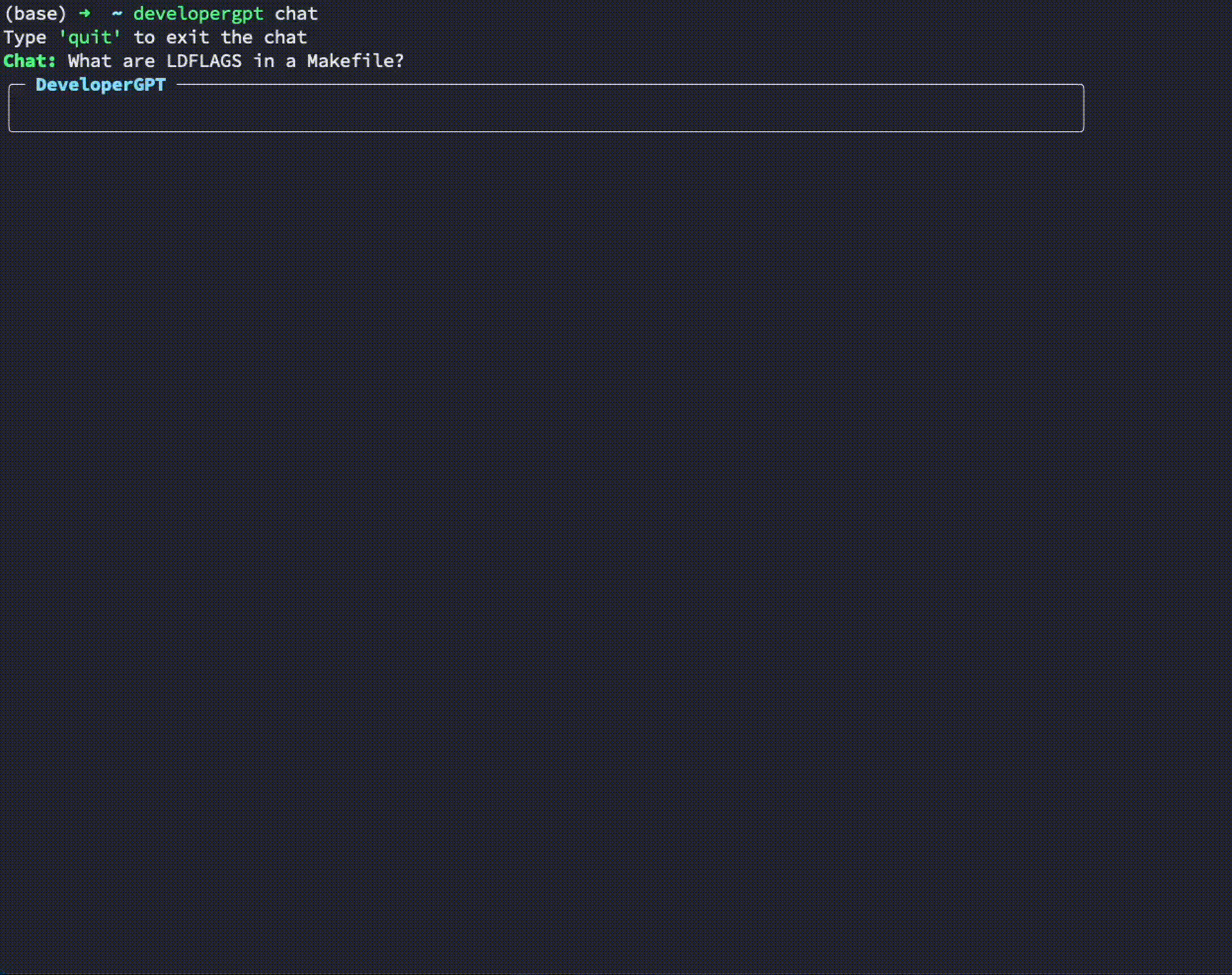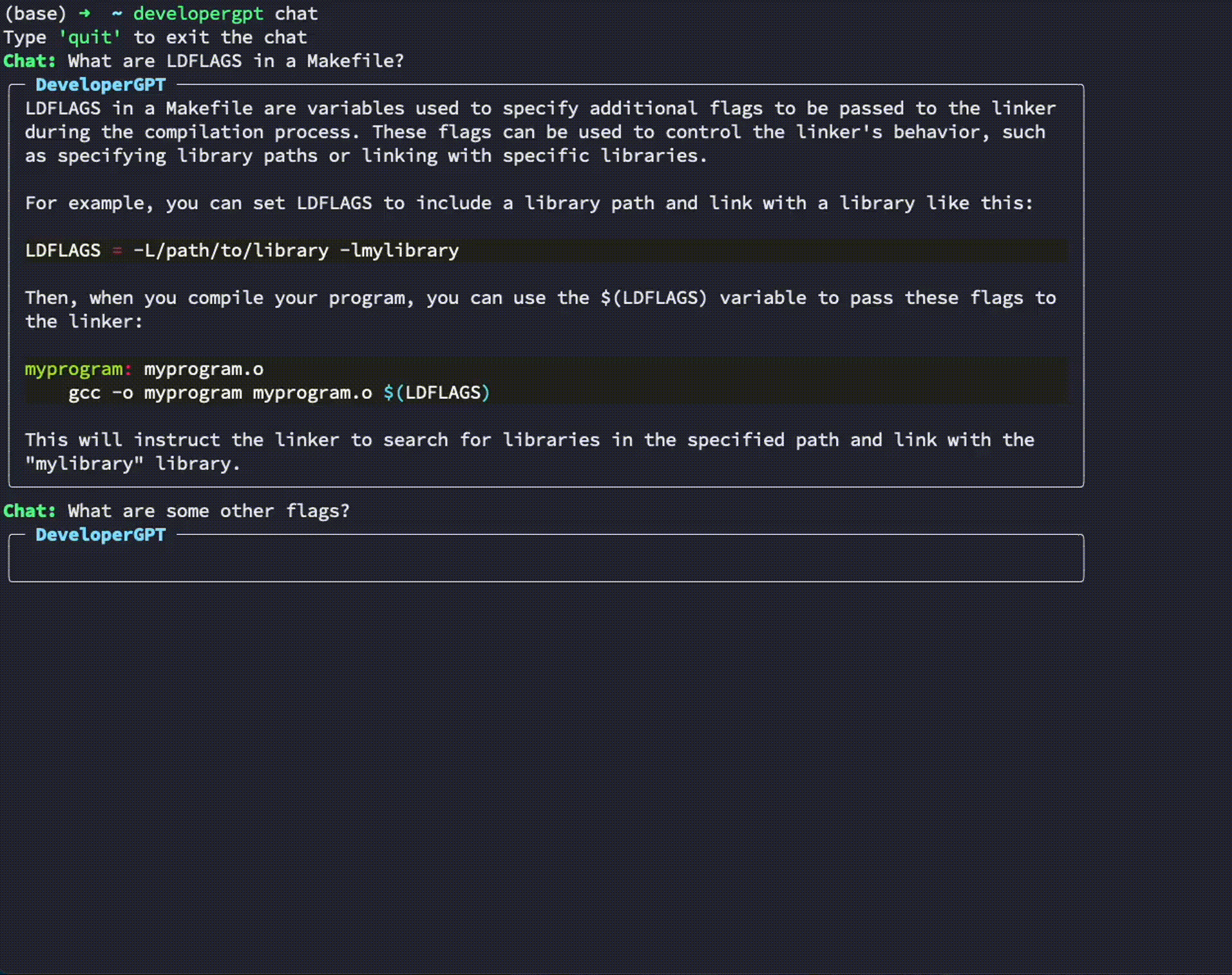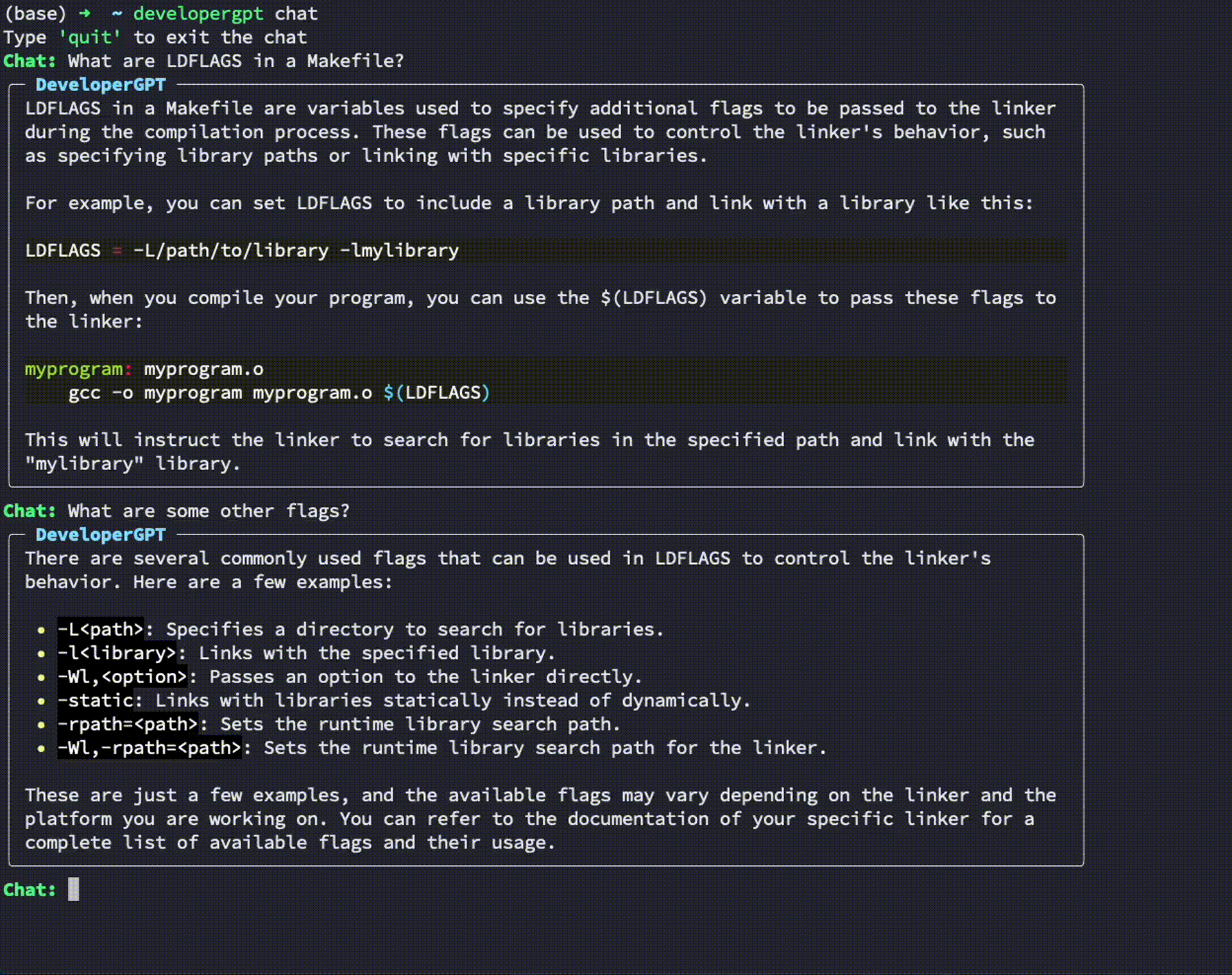
Utilisez developergpt --model [model_name] chat pour utiliser un LLM différent.
# Example
$ developergpt --model mistral chatLa modération du chat n'est PAS implémentée - tous vos messages de chat doivent suivre les conditions d'utilisation du LLM utilisé.
DeveloperGPT ne doit PAS être utilisé à des fins interdites par les conditions d'utilisation des LLM utilisés. De plus, DeveloperGPT lui-même (à l'exception des LLM) est un outil de preuve de concept et n'est pas destiné à être utilisé pour un travail sérieux ou commercial.
pip install -U developergpt # see available commands
$ developergpt La précision de DeveloperGPT varie en fonction du LLM utilisé ainsi que du mode ( --fast vs. Regular). Vous trouverez ci-dessous la précision Top@1 de différents LLM sur un ensemble de 85 requêtes de commandes en langage naturel (il ne s'agit pas d'une évaluation rigoureuse, mais cela donne une idée approximative de l'exactitude). Github CoPilot dans la CLI v1.0.1 est également inclus à des fins de comparaison.
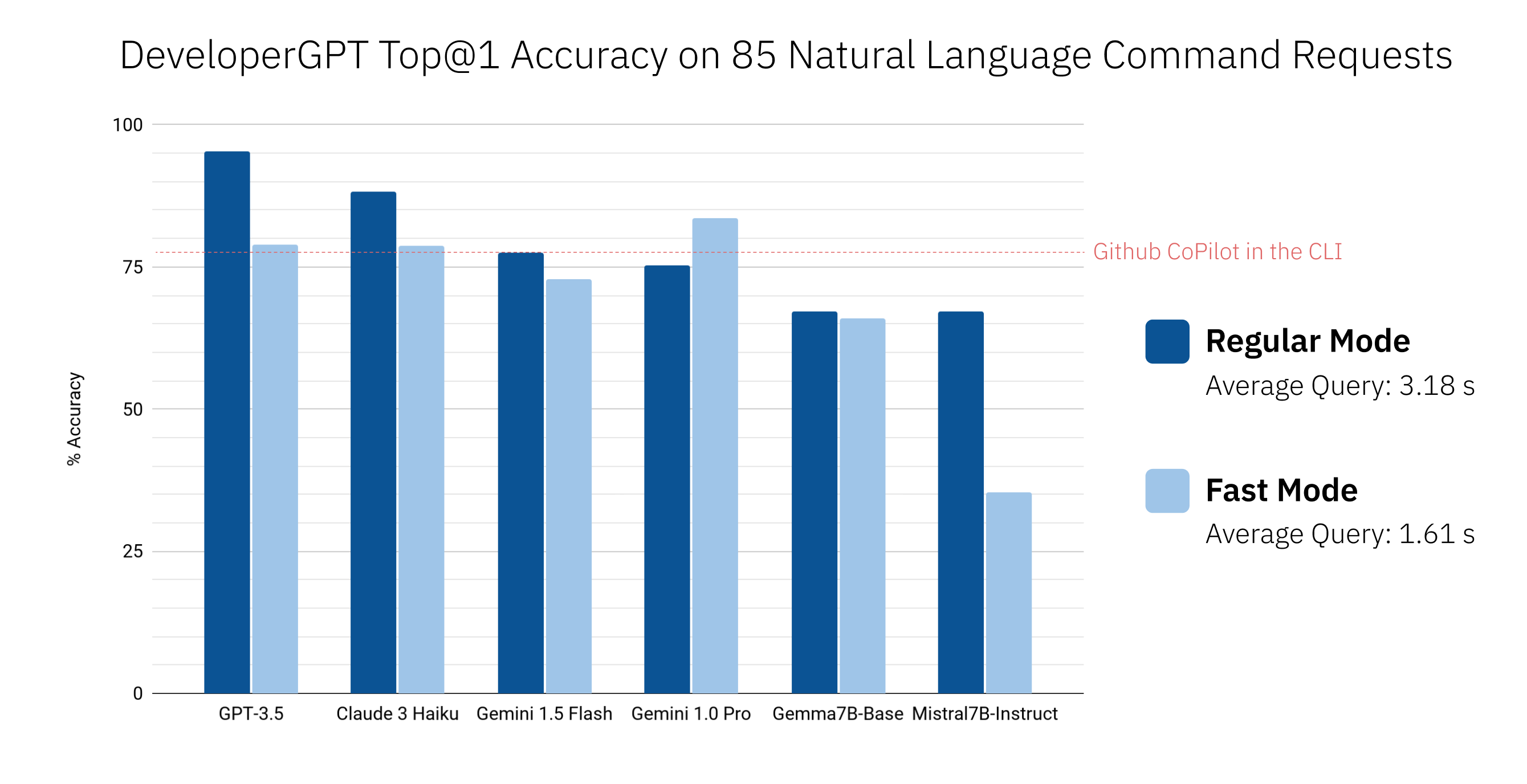
Par défaut, DeveloperGPT utilise Google Gemini 1.5 Flash. Pour utiliser Gemini 1.0 Pro ou Gemini 1.5 Flash, vous aurez besoin d'une clé API (gratuite pour utiliser jusqu'à 15 requêtes par minute).
GOOGLE_API_KEY . Vous ne devez le faire qu'une seule fois. # set Google API Key (using zsh for example)
$ echo ' export GOOGLE_API_KEY=[your_key_here] ' >> ~ /.zshenv
# reload the environment (or just quit and open a new terminal)
$ source ~ /.zshenv Pour utiliser des LLM ouverts tels que Gemma ou Mistral hébergés sur Hugging Face, vous pouvez éventuellement configurer un jeton API d'inférence Hugging Face en tant que variable d'environnement HUGGING_FACE_API_KEY . Voir https://huggingface.co/docs/api-inference/index pour plus de détails.
Pour utiliser Mistral-7B-Instruct quantifié, exécutez simplement DeveloperGPT avec l'indicateur --offline . Cela téléchargera le modèle lors de la première exécution et l'utilisera localement lors de toutes les exécutions futures (aucune connexion Internet n'est requise après la première utilisation). Aucune configuration particulière n'est requise.
developergpt --offline chatPour utiliser GPT-3.5 ou GPT-4, vous aurez besoin d'une clé API OpenAI.
OPENAI_API_KEY . Vous ne devez le faire qu'une seule fois. Pour utiliser Anthropic Claude 3 Sonnet ou Haiku, vous aurez besoin d'une clé API Anthropic.
ANTHROPIC_API_KEY . Vous ne devez le faire qu'une seule fois.Depuis juin 2024, Google Gemini 1.0 Pro et Gemini 1.5 Flash sont libres d'utiliser jusqu'à 15 requêtes par minute. Pour plus d'informations, consultez : https://ai.google.dev/pricing
Depuis juin 2024, l'utilisation des LLM hébergés par l'API Hugging Face Inference est gratuite mais à tarif limité. Voir https://huggingface.co/docs/api-inference/index pour plus de détails.
Mistral-7B-Instruct est gratuit et s'exécute localement sur l'appareil.
Vous pouvez surveiller votre utilisation de l'API OpenAI ici : https://platform.openai.com/account/usage. Le coût moyen par requête utilisant GPT-3.5 est < 0,1 centime. L'utilisation de GPT-4 n'est pas recommandée car GPT-3.5 est beaucoup plus rentable et atteint une très grande précision pour la plupart des commandes.
Vous pouvez surveiller votre utilisation de l'API Anthropic ici : https://console.anthropic.com/settings/plans. Le coût moyen par requête utilisant Claude 3 Haiku est < 0,1 centime. Voir https://www.anthropic.com/api pour plus de détails sur les prix.
Lisez le fichier CONTRIBUTING.md.


